





Recap of Databricks Machine Learning announcements from Data & AI Summit
Databricks Machine Learning on the lakehouse provides end-to-end machine learning capabilities from data ingestion and training to deployment and monitoring, all in one...
Data warehouses are not keeping up with today's world: the explosion of languages other than SQL, unstructured data, machine learning, IoT and streaming analytics have forced customers to adopt a bifurcated architecture: data warehouses for BI and data lakes for ML. While SQL is ubiquitous and known by millions of professionals, it has never been treated as a first-class citizen on the data lake - until the rise of the data lakehouse.
As customers adopt the lakehouse architecture, Databricks SQL (DBSQL) provides data warehousing capabilities and first-class support for SQL on the Databricks Lakehouse Platform - and brings together the best of data lakes and data warehouses. Thousands of customers worldwide have already adopted DBSQL, and at the Data + AI Summit, we announced a number of innovations for data transformation & ingest, connectivity, and classic data warehousing to continue to redefine analytics on the lakehouse. Read on for the highlights.
First, we announced the availability of serverless compute for Databricks SQL (DBSQL) in Public Preview on AWS! Now you can enable every analyst and analytics engineer to ingest, transform, and query the most complete and freshest data without having to worry about the underlying infrastructure.
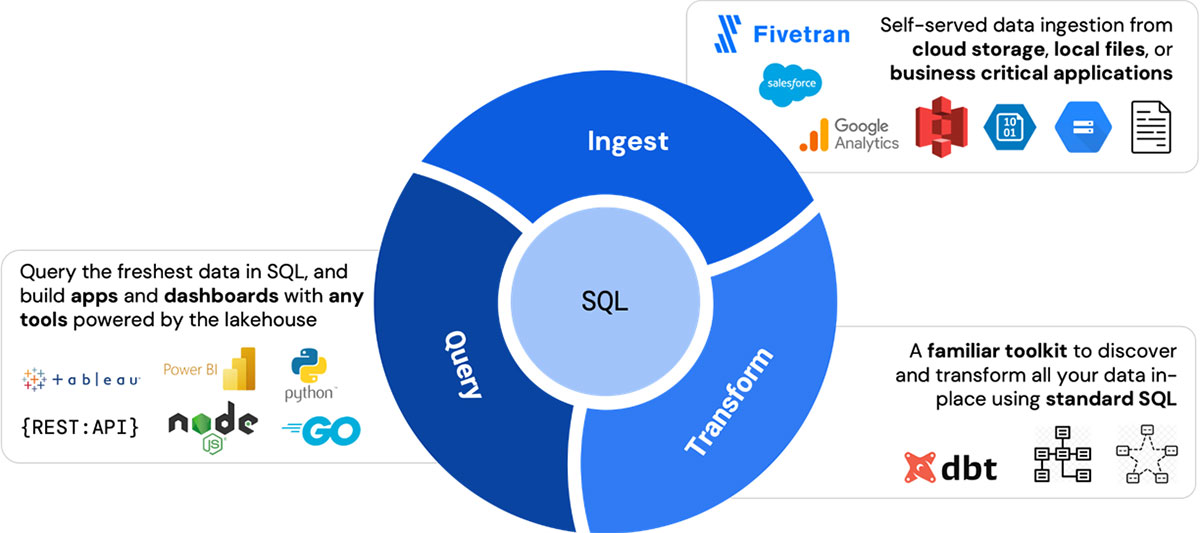
Many customers use Databricks SQL to build custom data applications powered by the lakehouse. So we announced a full lineup of open source connectors for Go, Node.js, Python, as well as a new CLI to make it simpler for developers to connect to Databricks SQL from any application. Contact us on GitHub and the Databricks Community for any feedback and let us know what's next to build!
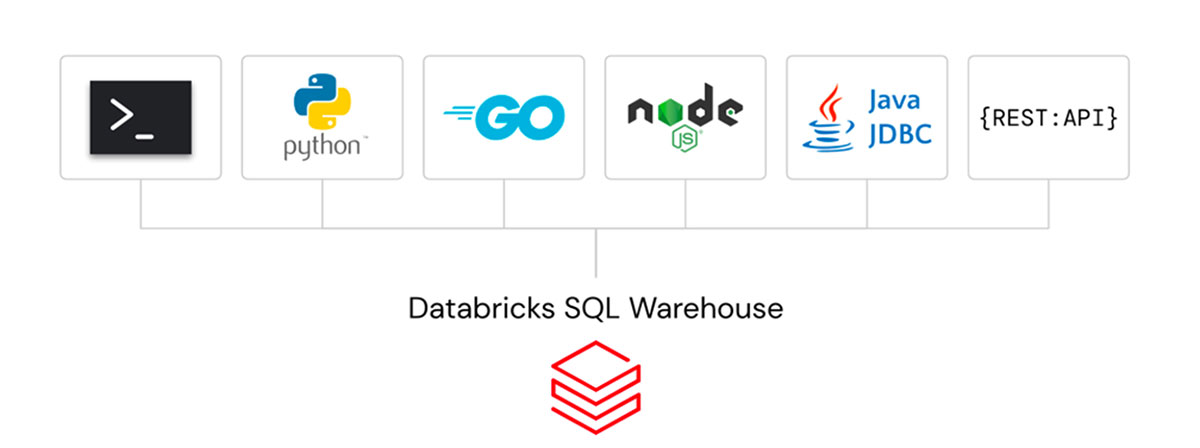
Bringing together data scientists and data analysts like never before, Python UDFs deliver the power of Python right into your favorite SQL environment! Now analysts can tap into python functions - from complex transformation logic to machine learning models - that data scientists have already developed and seamlessly use them in their SQL statements directly in Databricks SQL. Python UDFs are now in private preview - stay tuned for more updates to come.
CREATE FUNCTION redact(a STRING)
RETURNS STRING
LANGUAGE PYTHON
AS $$
import json
keys = ["email", "phone"]
obj = json.loads(a)
for k in obj:
if k in keys:
obj[k] = "REDACTED"
return json.dumps(obj)
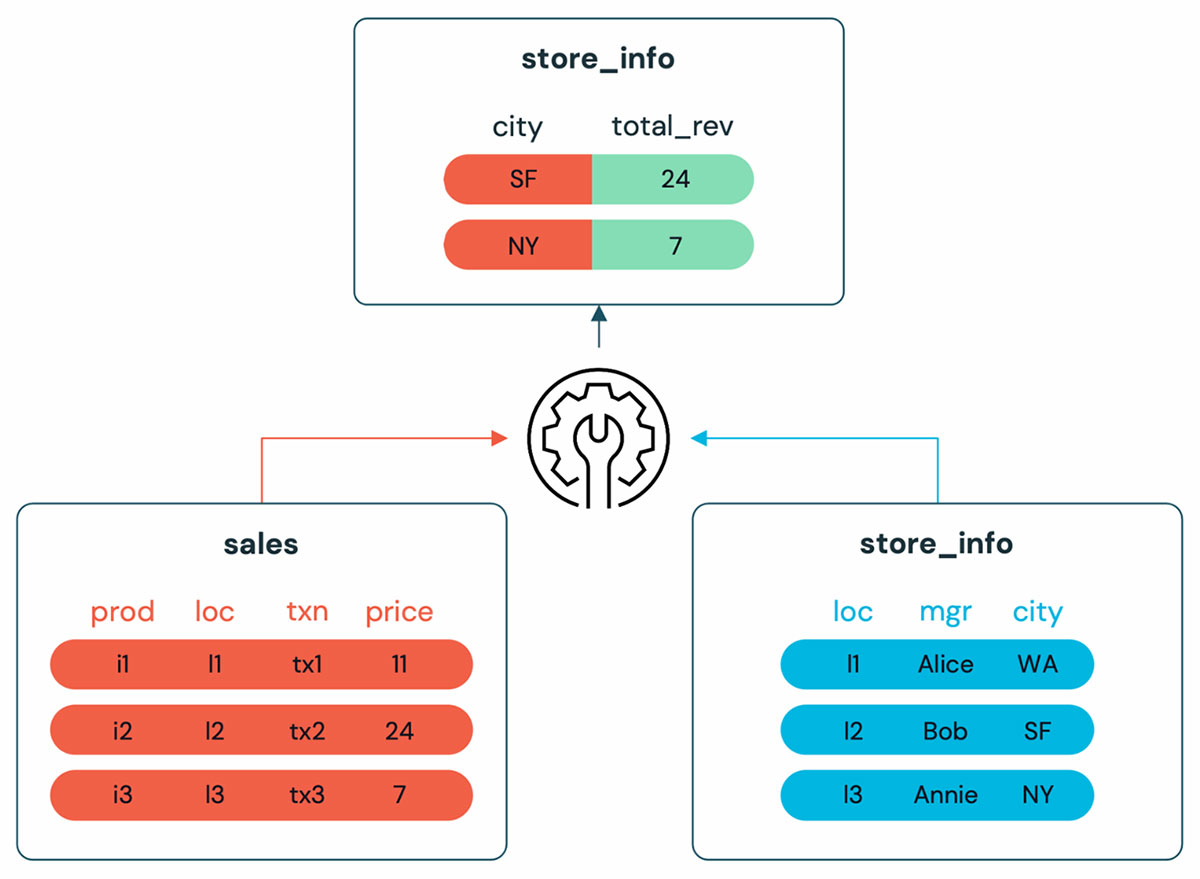
$$;The lakehouse is home to all data sources. Query federation allows analysts to directly query data stored outside of the lakehouse without the need to first extract and load the data from the source systems. Of course, it’s possible to combine data sources like PostgreSQL and delta transparently in the same query.
CREATE EXTERNAL TABLE
taxi_trips.taxi_transactions
USING postgresql OPTIONS
(
dbtable ‘taxi_trips’,
host secret(“postgresdb”,”host”),
port ‘5432’,
database secret(“postgresdb”,”db”),
user secret(postgresdb”,”username”),
password secret(“postgresdb”,”password”)
);Materialized Views (MVs) accelerate end-user queries and reduce infrastructure costs with efficient, incremental computation. Built on top of Delta Live Tables (DLT), MVs reduce query latency by pre-computing otherwise slow queries and frequently used computations.
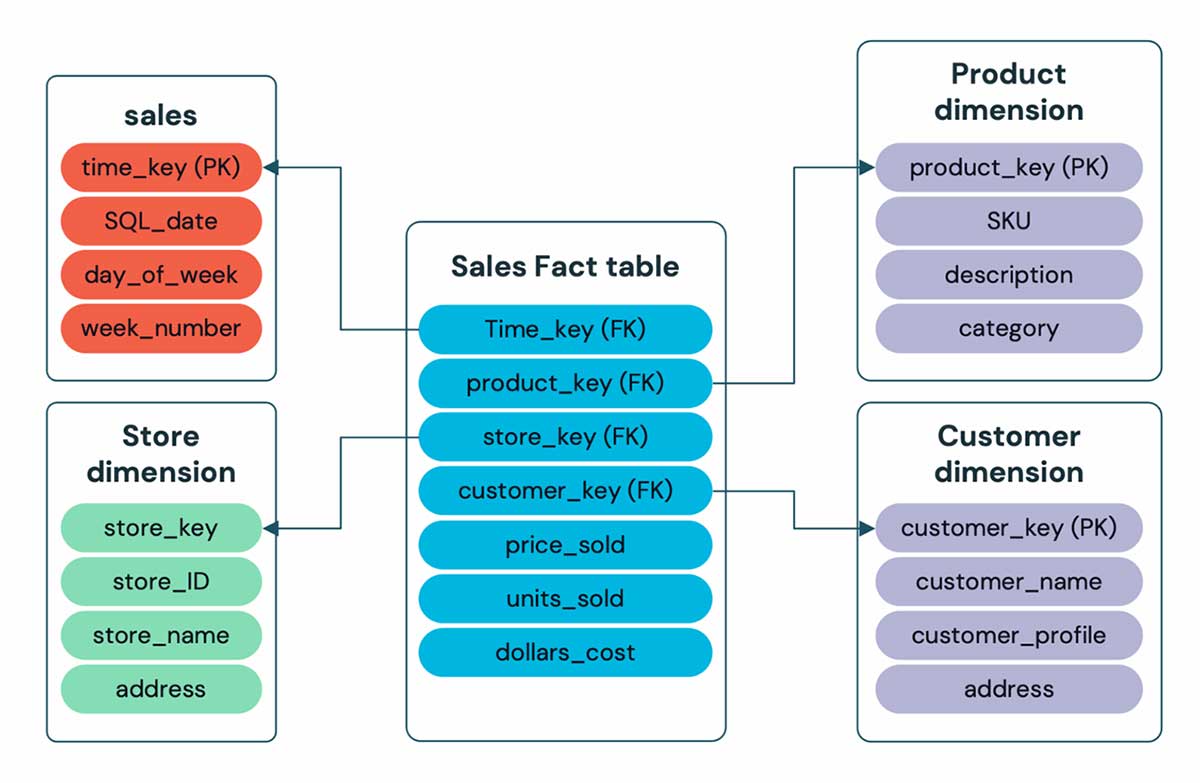
Everyone’s favorite data warehouse constraints are coming to the lakehouse! Primary Key & Foreign Key Constraints provides analysts with a familiar toolkit for advanced data modeling on the lakehouse. DBSQL & BI tools can then leverage this metadata for improved query planning.
Join the conversation in the Databricks Community where data-obsessed peers are chatting about Data + AI Summit 2022 announcements and updates, and visit https://dbricks.co/dbsql to get started today !
Below is a selection of related sessions from the Data+AI Summit 2022 to watch on-demand:
