Transformationen
Was sind Transformationen?
In Spark sind die Kerndatenstrukturen unveränderlich, d. h. sie können nach der Erstellung nicht mehr bearbeitet werden. Das mag auf den ersten Blick merkwürdig klingen, denn wenn Sie etwas nicht ändern können, wie sollen Sie es dann nutzen? Um einen DataFrame zu „ändern“, müssen Sie Spark sagen, wie Sie den vorhandenen DataFrame in den gewünschten überführen möchten. Solche Anweisungen werden als Transformationen bezeichnet. Transformationen bilden den Kern dessen, wie Sie Ihre Geschäftslogik mit Spark ausdrücken. Es gibt zwei Arten von Transformationen: Die einen spezifizieren schmale, die anderen breite Abhängigkeiten.
Was sind schmale Abhängigkeiten?
Transformationen, die aus schmalen Abhängigkeiten bestehen – wir nennen sie „schmale“ Transformationen –, sind solche, bei denen jede Eingabepartition nur zu einer Ausgabepartition beiträgt. 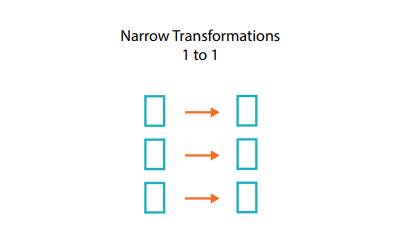
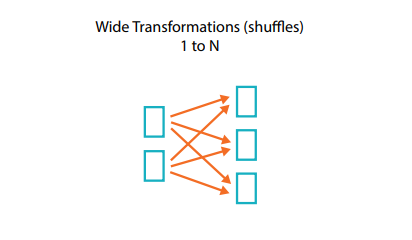
Was sind breite Abhängigkeiten?
Eine Transformation mit breiten Abhängigkeiten (oder einfach „breite Transformation“) hat Eingabepartitionen, die zu vielen Ausgabepartitionen beitragen. Häufig ist hiervon als Shuffle die Rede, wobei Spark Partitionen innerhalb des gesamten Clusters austauscht. Bei schmalen Transformationen führt Spark automatisch eine Operation namens Pipelining an schmalen Abhängigkeiten durch, d. h. wenn wir mehrere Filter auf DataFrames definieren, werden sie alle im Speicher ausgeführt. Für Shuffles gilt das dagegen nicht: Wenn wir einen Shuffle durchführen, schreibt Spark die Ergebnisse auf die Festplatte. Sie werden im Internet viel über die Optimierung von Zufallsgeneratoren lesen, da das ein wichtiges Thema ist. Für den Moment müssen Sie allerdings nur wissen, dass es zwei Arten von Transformationen gibt.