Trasformazioni
Che cosa sono le trasformazioni?
In Spark, le strutture di dati principali sono immutabili, cioè non possono essere modificate una volta create. A prima vista potrebbe sembrare una stranezza: se non sono modificabili, come si fa ad usarle? Per “cambiare” un DataFrame, bisogna istruire Spark su come si desidera modificare il DataFrame esistente in quello desiderato. Queste istruzioni vengono dette trasformazioni. Le trasformazioni sono il fulcro della formulazione della logica operativa in Spark. Esistono due tipi di trasformazioni: quelle che specificano dipendenze strette e quelle che specificano dipendenze ampie.
Che cosa sono le dipendenze strette?
Le trasformazioni che consistono in dipendenze strette (le chiameremo trasformazioni strette) sono quelle in cui ogni partizione di ingresso contribuisce a una sola partizione in uscita. 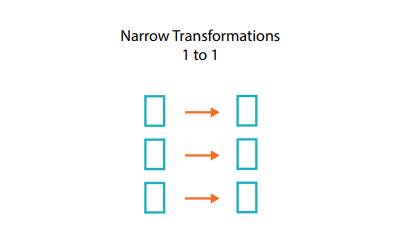
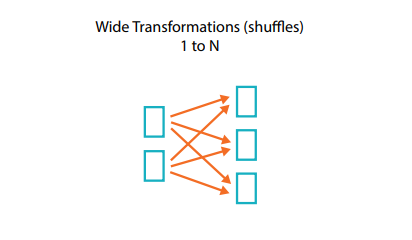
Che cosa sono le dipendenze ampie?
In una trasformazione con dipendenza ampia (o trasformazione ampia) le partizioni di ingresso contribuiscono a molte partizioni in uscita. Spesso questa operazione viene definita shuffle, poiché Spark "rimescola" le partizioni su tutto il cluster. Nelle trasformazioni strette, Spark esegue automaticamente un'operazione chiamata pipelining sulle dipendenze strette; questo significa che, se specifichiamo filtri multipli sui DataFrame, questi verranno eseguiti tutti in memoria. Lo stesso non vale per gli shuffle. Quando si esegue uno shuffle, Spark scrive i risultati sul disco. In rete si trovano molte discussioni sull'ottimizzazione dello shuffle, perché si tratta di un argomento importante, ma per ora tutto quello che serve sapere è che esistono due tipi di trasformazioni.