변환
변환이란 무엇입니까?
Spark에서 코어 데이터 구조가 변경 불가능(immutable)하다는 것은 일단 생성하면 변경할 수 없다는 뜻입니다. 이것은 처음에는 조금 기이한 개념으로 여겨질 수 있습니다. 변경할 수 없다면 어떻게 사용합니까? DataFrame을 "변경"하려면 Spark에 지금 가지고 있는 DataFrame을 원하는 버전으로 수정할 방법을 지시해야 합니다. 이런 지침을 변환(transformations)이라고 합니다. 변환은 Spark를 사용해 비즈니스 로직을 표현하는 방법의 핵심입니다. 변환에는 두 가지 유형이 있는데, 하나는 좁은 의존성(narrow dependency)을 지정하는 것이고 다른 하나는 넓은 의존성(wide dependency)을 지정하는 것입니다.
좁은 의존성이란 무엇입니까?
좁은 의존성으로 구성된 변환은 [일명 좁은 변환이라고 함] 각각의 입력 파티션이 딱 하나의 출력 파티션에만 영향을 미치는 변환을 말합니다.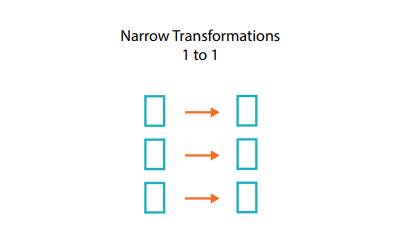
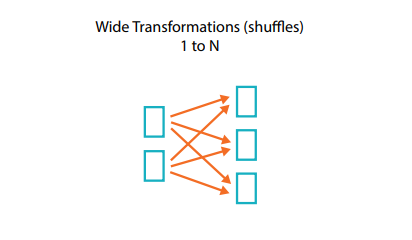
넓은 의존성이란 무엇입니까?
넓은 의존성 [또는 넓은 변환] 방식의 변환은 입력 파티션이 수많은 출력 파티션에 영향을 미칩니다. 이것은 주로 섞기(shuffle)라 불리며, 이 경우 Spark가 클러스터 전체에서 파티션을 교환하게 됩니다. 좁은 변환의 경우, Spark가 좁은 의존성에서 파이프라이닝이라는 작업을 자동으로 수행하는데, 이는 즉 DataFrames에 여러 개의 필터를 지정하면 모두 메모리 내에서 수행된다는 뜻입니다. 섞기(shuffle)의 경우 이야기가 다릅니다. 섞기(shuffle)를 수행하면 Spark가 결과를 디스크에 씁니다. 웹상에서 섞기(shuffle) 최적화에 관한 이야기가 많이 눈에 띌 텐데, 그만큼 중요한 주제이기 때문입니다. 하지만 지금으로서는 변환에는 두 가지 종류가 있다는 것만 이해하면 됩니다.