
A good benchmark is one that clearly shows which models are better and which are worse. The Databricks Mosaic Research team is dedicated to finding great measurement tools that allow researchers to evaluate experiments. The Mosaic Evaluation Gauntlet is our set of benchmarks for evaluating the quality of models and is composed of 39 publicly available benchmarks split across 6 core competencies: language understanding, reading comprehension, symbolic problem solving, world knowledge, commonsense, and programming. In order to prioritize the metrics that are most useful for research tasks across model scales, we tested the benchmarks using a series of increasingly advanced models.
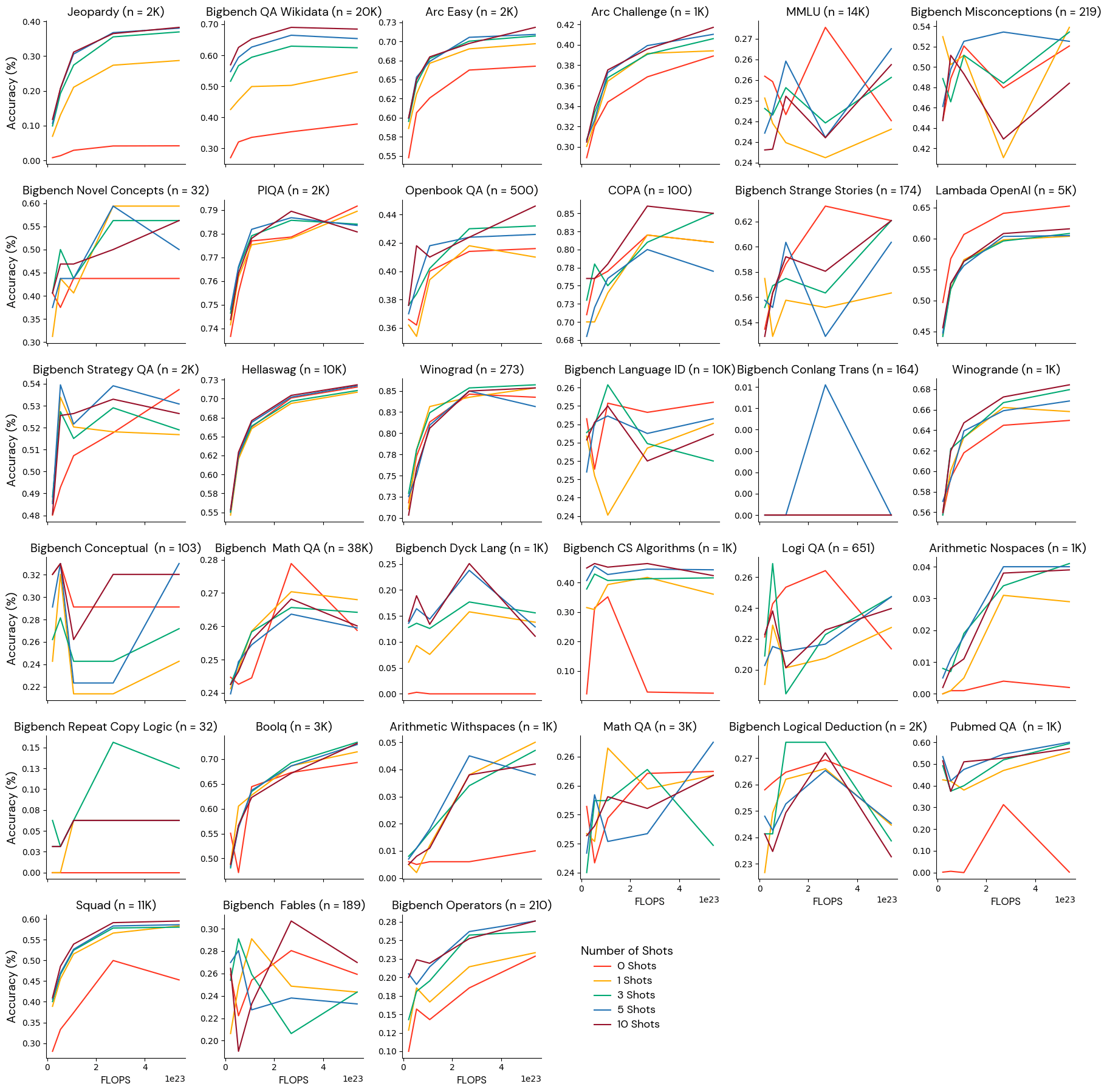
Recent research, particularly the Chinchilla paper from DeepMind, has demonstrated that scaling up language models by increasing both their parameter count and training data size leads to significant performance improvements. To identify a reliable set of benchmarks, we can leverage the well-established relationship between a model's performance and its scale. Assuming that scaling laws are a stronger ground truth than each individual benchmark, we tested which benchmarks could rank order the models correctly from least to most training FLOPS.
We trained 5 models with progressively larger amounts of training data: from a ratio of 20 tokens per parameter to a ratio of 500 tokens per parameter. Each model had 3 billion parameters, so the total FLOPS ranged from 2.1e22 to 5.4e23 FLOPS. We then selected the metrics that monotonically ranked the models from the least to the most training FLOPS.
Results
We sorted the metrics into four groups: (1) well-behaved and robust to few-shot settings, (2) well-behaved given a certain number of few-shot examples, (3) not better than noise, and (4) poorly behaved.
Group 1: Well-behaved metrics robust to few-shot settings
These benchmarks reliably ordered models by training scale and monotonically improved at any number of shots. We believe that these benchmarks can provide a reliable evaluation signal for models in this range.
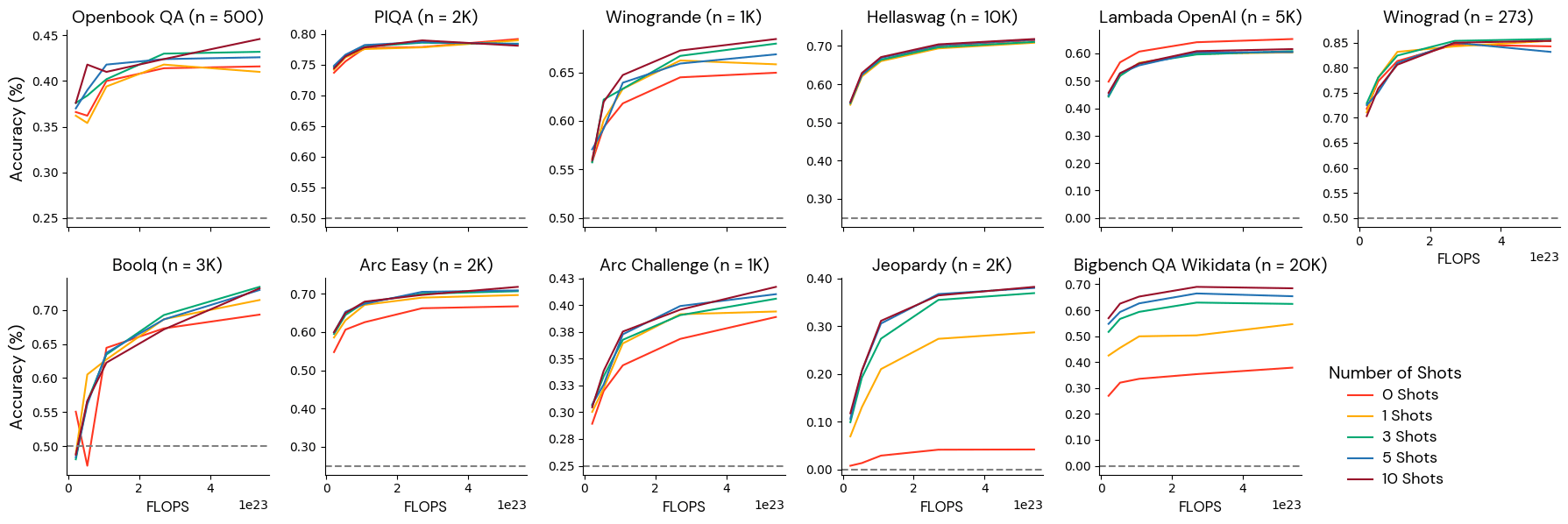
Group 2: Well-behaved at specific few-shot settings
These benchmarks were monotonically related to the model scale at some few-shot settings but unrelated to the model scale at other few-shot settings. For example, BigBench Strategy QA was monotonically related to the model scale if provided with 0 shots but was anti-correlated with the scale if given 1 shot. We recommend using these metrics with a reliable few-shot setting.

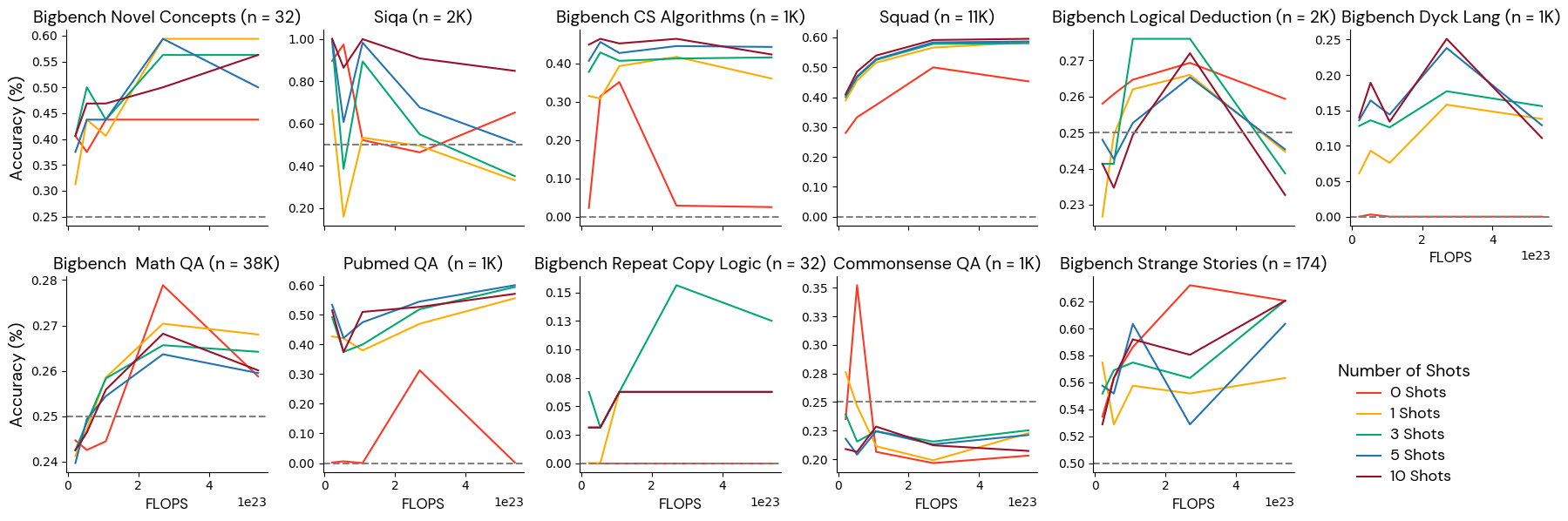
Group 3: Poorly behaved benchmarks
These benchmarks did not monotonically improve with more token duration at this model scale. Some benchmarks in this category actually got worse with scale. These benchmarks might mislead researchers about what decisions to make with their experimental results. We hypothesize that this behavior may be due to the fact that benchmarks in this category contain label imbalance (if one answer is more frequent than the others, models can be biased and give the more frequent answer), low information content (the same question is repeatedly asked with only minor variations), or inter-labeler disagreement (two experts looking at the same question dispute the correct answer). Manual inspection and filtering of these benchmarks may be required.
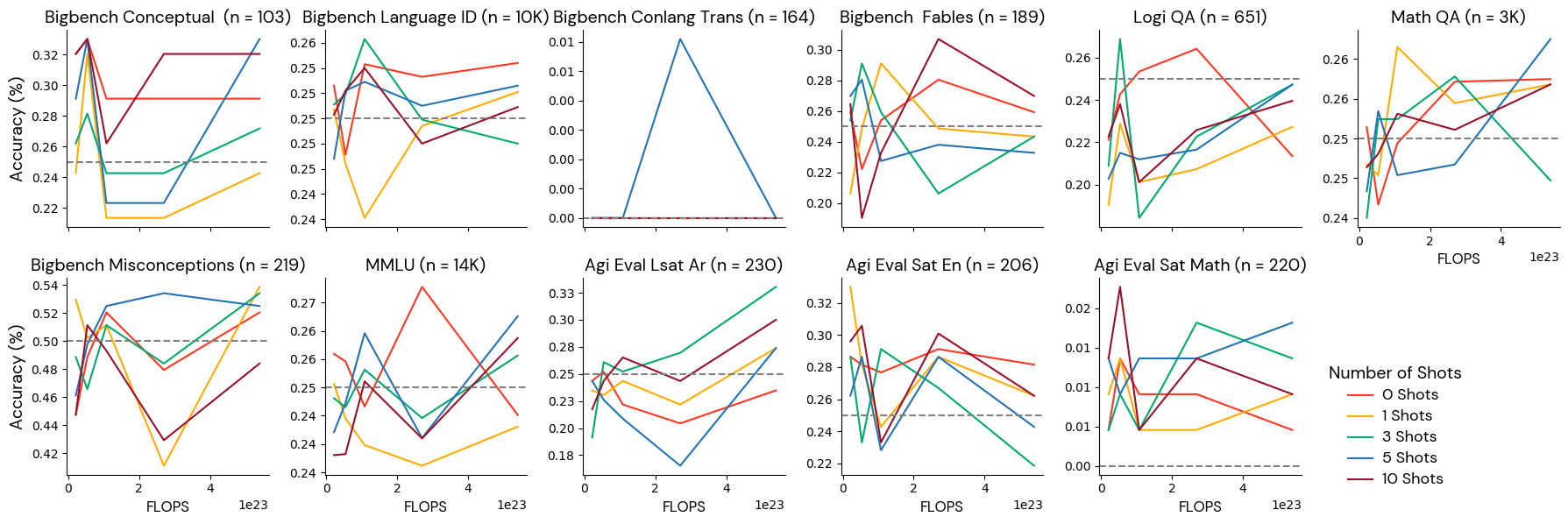
Group 4: Noise level benchmarks
The models do not do better than random guessing on these benchmarks, and scores do not reliably improve with more training at this scale. These benchmarks are too difficult for models of this scale (2.1e22- 5.4e23 FLOPS), and researchers should be cautious about drawing conclusions from experiments using these benchmarks for small models. Note that this category includes benchmarks that are popular and useful for more capable models, like MMLU, so we kept the tasks in this category despite their tendency to add noise to the aggregate Gauntlet. We recommend using caution when relying on these benchmarks for any of the combinations of model sizes and token counts we considered in this study since the results do not appear informative.
Conclusion and Limitations
After running this calibration experiment we changed the composition of our Evaluation Gauntlet to remove tasks from Group 3: Poorly Behaved Benchmarks. This reduced the amount of noise in our aggregate score. We kept the noisy benchmarks (Group 4) because they measure performance on tasks we are interested in improving on, in particular math and MMLU. We still recommend caution when relying on the benchmarks in Group 4. We selected a default few-shot setting for the benchmarks in Group 2 based on the strength and monotonicity of their correlation with FLOPS.
While the relationship between model scale and benchmark performance is well established, it's possible that any given benchmark measures capabilities that do not always improve with model scale. In this case, the decisions we made using this calibration method would be misguided. Additionally, our analysis relied on a limited set of model scales and architectures. It's possible that different model families would exhibit distinct scaling behavior on these benchmarks. Future work could explore a wider range of model sizes and types to further validate the robustness of these findings.
Despite these limitations, this calibration exercise gave us a principled approach to refining benchmark suites as models progress. By aligning our evaluation methodology with the empirical scaling properties of language models, we can more effectively track and compare their evolving capabilities. You can test your own evaluation metrics using our evaluation framework in our LLM Foundry repo. Ready to train your models on the Mosaic AI training infrastructure? Contact us today.
Acknowledgments
Thanks to Mansheej Paul for the original idea and for architecting the experiments, Sasha Doubov for training the models, and Jeremy Dohmann for creating the original Gauntlet.