Previsão de Séries Temporais com Granularidade Fina em Escala com Facebook Prophet e Apache Spark
Experimente este notebook de previsão de séries temporais em nosso Solution Accelerator for Demand Forecasting.
Os avanços na previsão de séries temporais permitem que os varejistas gerem previsões de demanda mais confiáveis. O desafio agora é produzir essas previsões em tempo hábil e em um nível de granularidade que permita à empresa fazer ajustes precisos nos estoques de produtos. Utilizando Apache Spark™ e Facebook Prophet, cada vez mais empresas que enfrentam esses desafios estão descobrindo que podem superar os limites de escalabilidade e precisão de soluções anteriores.
Neste post, discutiremos a importância da previsão de séries temporais, visualizaremos alguns dados de séries temporais de exemplo e, em seguida, construiremos um modelo simples para mostrar o uso do Facebook Prophet. Assim que você estiver confortável em construir um único modelo, combinaremos o Prophet com a magia do Apache Spark™ para mostrar como treinar centenas de modelos de uma vez, permitindo-nos criar previsões precisas para cada combinação individual de produto-loja em um nível de granularidade raramente alcançado até agora.
Previsão precisa e oportuna é agora mais importante do que nunca
Melhorar a velocidade e a precisão das análises de séries temporais para prever melhor a demanda por produtos e serviços é fundamental para o sucesso dos varejistas. Se muito produto for colocado em uma loja, o espaço nas prateleiras e nos estoques pode ficar sobrecarregado, os produtos podem expirar e os varejistas podem ter seus recursos financeiros presos em estoque, impedindo-os de aproveitar novas oportunidades geradas por fabricantes ou mudanças nos padrões de consumo. Se muito pouco produto for colocado em uma loja, os clientes podem não conseguir comprar os produtos de que precisam. Esses erros de previsão não resultam apenas em perda imediata de receita para o varejista, mas com o tempo a frustração do consumidor pode levar os clientes a concorrentes.
Novas expectativas exigem métodos e modelos de previsão de séries temporais mais precisos
Por algum tempo, os sistemas de planejamento de recursos empresariais (ERP) e soluções de terceiros forneceram aos varejistas recursos de previsão de demanda baseados em modelos simples de séries temporais. Mas com os avanços na tecnologia e o aumento da pressão no setor, muitos varejistas estão buscando ir além dos modelos lineares e algoritmos mais tradicionais historicamente disponíveis para eles.
Novas capacidades, como as fornecidas pelo Facebook Prophet, estão surgindo da comunidade de ciência de dados, e as empresas buscam a flexibilidade para aplicar esses modelos de machine learning às suas necessidades de previsão de séries temporais.
![]()
Esse movimento de afastamento das soluções tradicionais de previsão exige que varejistas e similares desenvolvam expertise interna não apenas nas complexidades da previsão de demanda, mas também na distribuição eficiente do trabalho necessário para gerar centenas de milhares ou até milhões de modelos de machine learning em tempo hábil. Felizmente, podemos usar o Spark para distribuir o treinamento desses modelos, tornando possível prever não apenas a demanda geral por produtos e serviços, mas a demanda única para cada produto em cada local.
Visualizando a sazonalidade da demanda em dados de séries temporais
Para demonstrar o uso do Prophet para gerar previsões de demanda detalhadas para lojas e produtos individuais, usaremos um conjunto de dados publicamente disponível do Kaggle. Ele consiste em 5 anos de dados de vendas diárias para 50 itens individuais em 10 lojas diferentes.
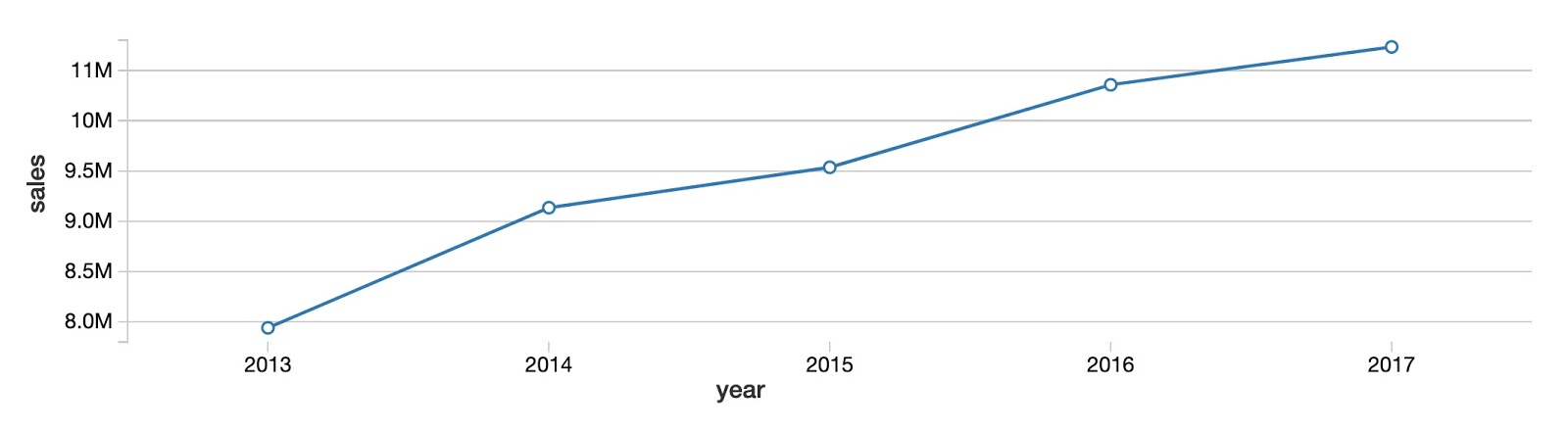
Para começar, vamos analisar a tendência geral de vendas anuais para todos os produtos e lojas. Como você pode ver, as vendas totais de produtos estão aumentando ano a ano, sem sinal claro de convergência em um platô.
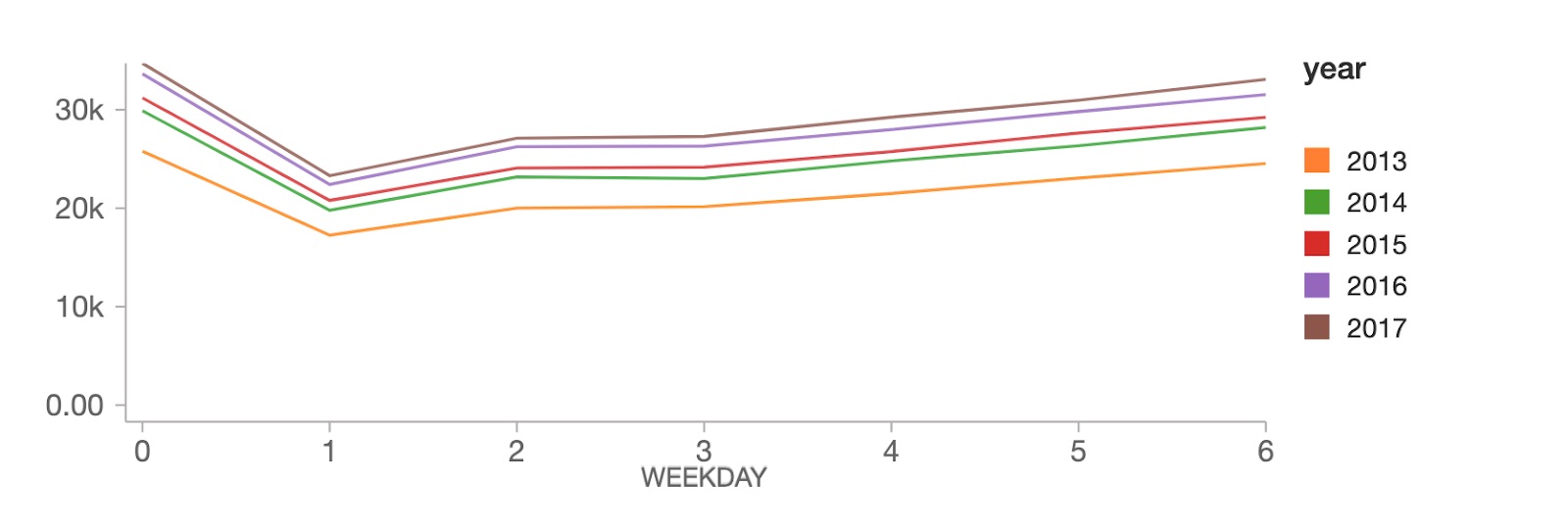
No nível do dia da semana, as vendas atingem o pico aos domingos (dia da semana 0), seguidas por uma queda acentuada às segundas-feiras (dia da semana 1), e depois se recuperam constantemente ao longo do resto da semana.
Começando com um modelo simples de previsão de séries temporais no Facebook Prophet
Como ilustrado nos gráficos acima, nossos dados mostram uma clara tendência de alta nas vendas ano a ano, juntamente com padrões sazonais anuais e semanais. São esses padrões sobrepostos nos dados que o Prophet foi projetado para abordar.
O Facebook Prophet segue a API do scikit-learn, portanto, deve ser fácil de usar para qualquer pessoa com experiência em sklearn. Precisamos passar um pandas DataFrame de 2 colunas como entrada: a primeira coluna é a data e a segunda é o valor a ser previsto (em nosso caso, vendas). Assim que nossos dados estiverem no formato correto, construir um modelo é fácil:
Agora que ajustamos nosso modelo aos dados, vamos usá-lo para construir uma previsão de 90 dias. No código abaixo, definimos um conjunto de dados que inclui datas históricas e 90 dias adicionais, usando o método make_future_dataframe do Prophet:
É isso! Agora podemos visualizar como nossos dados reais e previstos se alinham, bem como uma previsão para o futuro usando o método .plot integrado do Prophet. Como você pode ver, os padrões de demanda semanais e sazonais que ilustramos anteriormente são, de fato, refletidos nos resultados previstos.
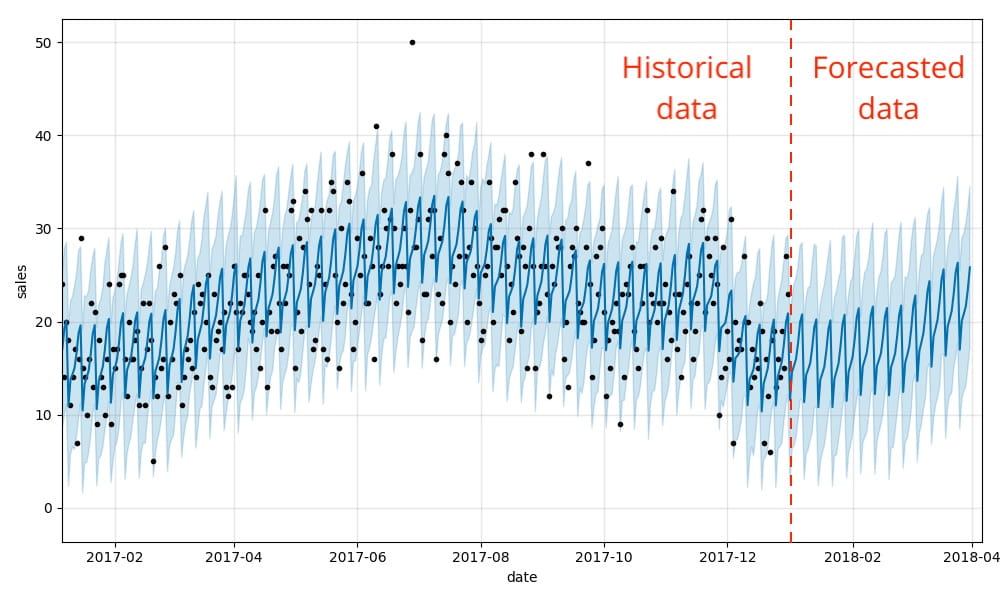
Esta visualização é um pouco confusa. Bartosz Mikulski fornece uma excelente análise dela que vale a pena conferir. Em resumo, os pontos pretos representam nossos dados reais, com a linha azul mais escura representando nossas previsões e a banda azul mais clara representando nosso intervalo de incerteza (95%).
Treinando centenas de modelos de previsão de séries temporais em paralelo com Prophet e Spark
Agora que demonstramos como construir um único modelo de previsão de séries temporais, podemos usar o poder do Apache Spark para multiplicar nossos esforços. Nosso objetivo é gerar não uma previsão para todo o conjunto de dados, mas centenas de modelos e previsões para cada combinação de produto-loja, algo que seria incrivelmente demorado para realizar como uma operação sequencial.
Construir modelos dessa forma poderia permitir que uma rede de supermercados, por exemplo, criasse uma previsão precisa para a quantidade de leite que deveriam pedir para sua loja em Sandusky, que difere da quantidade necessária em sua loja em Cleveland, com base na demanda diferente nesses locais.
Como usar Spark DataFrames para distribuir o processamento de dados de séries temporais
Cientistas de dados frequentemente enfrentam o desafio de treinar um grande número de modelos usando um motor de processamento de dados distribuído como o Apache Spark. Ao alavancar um cluster Spark, nós workers individuais no cluster podem treinar um subconjunto de modelos em paralelo com outros nós workers, reduzindo drasticamente o tempo total necessário para treinar toda a coleção de modelos de séries temporais.
Claro, treinar modelos em um cluster de nós workers (computadores) requer mais infraestrutura de nuvem, e isso tem um custo. Mas com a fácil disponibilidade de recursos de nuvem sob demanda, as empresas podem provisionar rapidamente os recursos de que precisam, treinar seus modelos e liberar esses recursos com a mesma rapidez, permitindo que alcancem escalabilidade massiva sem compromissos de longo prazo com ativos físicos.
O mecanismo chave para alcançar o processamento de dados distribuído no Spark é o DataFrame. Ao carregar os dados em um Spark DataFrame, os dados são distribuídos entre os workers no cluster. Isso permite que esses workers processem subconjuntos dos dados de forma paralela, reduzindo a quantidade total de tempo necessária para realizar nosso trabalho.
Claro, cada worker precisa ter acesso ao subconjunto de dados que ele requer para fazer seu trabalho. Agrupando os dados por valores-chave, neste caso em combinações de loja e item, reunimos todos os dados de séries temporais para esses valores-chave em um nó worker específico.
Compartilhamos o código groupBy aqui para enfatizar como ele nos permite treinar muitos modelos em paralelo de forma eficiente, embora ele não entre em jogo até configurarmos e aplicarmos um UDF aos nossos dados na próxima seção.
Alavancando o poder das funções definidas pelo usuário (UDFs) do pandas
Com nossos dados de séries temporais devidamente agrupados por loja e item, agora precisamos treinar um único modelo para cada grupo. Para realizar isso, podemos usar uma Função Definida pelo Usuário (UDF) do pandas, que nos permite aplicar uma função personalizada a cada grupo de dados em nosso DataFrame.
Este UDF não apenas treinará um modelo para cada grupo, mas também gerará um conjunto de resultados representando as previsões desse modelo. Mas enquanto a função treinará e fará previsões em cada grupo no DataFrame independentemente dos outros, os resultados retornados de cada grupo serão convenientemente coletados em um único DataFrame resultante. Isso nos permitirá gerar previsões em nível de loja-item, mas apresentar nossos resultados a analistas e gerentes como um único conjunto de dados de saída.
Como você pode ver no código Python abreviado abaixo, construir nosso UDF é relativamente simples. O UDF é instanciado com o método pandas_udf que identifica o esquema dos dados que ele retornará e o tipo de dados que ele espera receber. Logo após isso, definimos a função que realizará o trabalho do UDF.
Dentro da definição da função, instanciamos nosso modelo, configuramos seus parâmetros e o ajustamos aos dados que ele recebeu. O modelo faz uma previsão, e esses dados são retornados como a saída da função.
Agora, para juntar tudo, usamos o comando groupBy que discutimos anteriormente para garantir que nosso conjunto de dados seja devidamente particionado em grupos que representam combinações específicas de loja e item. Em seguida, simplesmente apply o UDF ao nosso DataFrame, permitindo que o UDF ajuste um modelo e faça previsões em cada agrupamento de dados.
O conjunto de dados retornado pela aplicação da função a cada grupo é atualizado para refletir a data em que geramos nossas previsões. Isso nos ajudará a acompanhar os dados gerados durante diferentes execuções de modelo à medida que eventualmente levamos nossa funcionalidade para produção.
Próximos passos
Agora construímos um modelo de previsão de séries temporais para cada combinação de loja-item. Usando uma consulta SQL, os analistas podem visualizar as previsões personalizadas para cada produto. No gráfico abaixo, plotamos a demanda projetada para o produto nº 1 em 10 lojas. Como você pode ver, as previsões de demanda variam de loja para loja, mas o padrão geral é consistente em todas as lojas, como seria de esperar.
À medida que novos dados de vendas chegam, podemos gerar eficientemente novas previsões e anexá-las às nossas estruturas de tabela existentes, permitindo que os analistas atualizem as expectativas do negócio à medida que as condições evoluem.
Para saber mais, assista ao webinar sob demanda intitulado Como a Starbucks Prevê a Demanda em Escala com Facebook Prophet e Azure Databricks e confira nosso Solution Accelerator para Previsão de Demanda.

(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.