Evolução de Esquema em Operações de Merge e Métricas Operacionais no Delta Lake
Delta Lake 0.6.0 introduz evolução de esquema e melhorias de performance em merges e métricas operacionais no histórico da tabela
por Tathagata Das e Denny Lee
Obtenha uma prévia antecipada do novo ebook da O'Reilly para obter as orientações passo a passo que você precisa para começar a usar o Delta Lake.
Experimente este notebook para reproduzir as etapas descritas abaixo.
Anunciamos recentemente o lançamento do Delta Lake 0.6.0, que introduz a evolução de esquema e melhorias de desempenho em operações de merge, além de métricas operacionais no histórico da tabela. Os principais recursos desta versão são:
- Suporte para evolução de esquema em operações de merge (#170) - Agora você pode evoluir automaticamente o esquema da tabela com a operação de merge. Isso é útil em cenários onde você deseja atualizar dados de alteração em uma tabela e o esquema dos dados muda ao longo do tempo. Em vez de detectar e aplicar alterações de esquema antes de atualizar, o merge pode evoluir o esquema e atualizar as alterações simultaneamente.
- Melhor desempenho de merge com particionamento automático (#349) - Ao fazer merge em tabelas particionadas, você pode optar por particionar automaticamente os dados pelas colunas de partição antes de gravar na tabela. Em casos onde a operação de merge em uma tabela particionada é lenta porque gera muitos arquivos pequenos (#345), habilitar o particionamento automático (spark.delta.merge.repartitionBeforeWrite) pode melhorar o desempenho.
- Melhor desempenho quando não há cláusula INSERT (#342) - Agora você pode obter melhor desempenho em uma operação de merge se ela não tiver nenhuma cláusula INSERT.
- Métricas de operação em DESCRIBE HISTORY (#312) - Agora você pode ver métricas de operação (por exemplo, número de arquivos e linhas alteradas) para todas as gravações, atualizações e exclusões em uma tabela Delta no histórico da tabela.
- Suporte para leitura de tabelas Delta de qualquer sistema de arquivos (#347) - Agora você pode ler tabelas Delta em qualquer sistema de armazenamento com uma implementação Hadoop FileSystem. No entanto, a gravação em tabelas Delta ainda requer a configuração de uma implementação LogStore que forneça as garantias necessárias no sistema de armazenamento.
Evolução de Esquema em Operações de Merge
Conforme observado em versões anteriores do Delta Lake, o Delta Lake inclui a capacidade de executar operações de merge para simplificar suas operações de INSERT/UPDATE/DELETE em uma única operação atômica, bem como a capacidade de impor e evoluir seu esquema (mais detalhes também podem ser encontrados neste tech talk). Com o lançamento do Delta Lake 0.6.0, você agora pode evoluir seu esquema dentro de uma operação de merge.
Vamos demonstrar isso usando um exemplo oportuno; você pode encontrar o exemplo de código original em este notebook. Começaremos com um pequeno subconjunto do 2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository by Johns Hopkins CSSE, que disponibilizamos em /databricks-datasets. Este é um conjunto de dados comumente usado por pesquisadores e analistas para obter insights sobre o número de casos de COVID-19 em todo o mundo. Um dos problemas com os dados é que o esquema muda ao longo do tempo.
Por exemplo, os arquivos que representam os casos de COVID-19 de 1º de março a 21 de março (em 30 de abril de 2020) têm o seguinte esquema:
Mas os arquivos de 22 de março em diante (em 30 de abril) tinham colunas adicionais, incluindo FIPS, Admin2, Active e Combined_Key.
Em nosso código de exemplo, renomeamos algumas das colunas (por exemplo, Long_ -> Longitude, Province/State -> Province_State, etc.) pois elas são semanticamente as mesmas. Em vez de evoluir o esquema da tabela, apenas renomeamos as colunas.
Se a principal preocupação fosse apenas mesclar os esquemas, poderíamos usar o recurso de evolução de esquema do Delta Lake com a opção “mergeSchema” em DataFrame.write(), como mostrado na instrução a seguir.
Mas o que acontece se você precisar atualizar um valor existente e mesclar o esquema ao mesmo tempo? Com o Delta Lake 0.6.0, isso pode ser alcançado com evolução de esquema para operações de merge. Para visualizar isso, vamos começar revisando os old_data, que é uma linha.
Em seguida, vamos simular uma entrada de atualização que segue o esquema de new_data.
e unir simulated_update e new_data com um total de 40 linhas.
Definimos o seguinte parâmetro para configurar seu ambiente para evolução automática de esquema:
Agora podemos executar uma única operação atômica para atualizar os valores (de 21/03/2020) e mesclar o novo esquema com a seguinte instrução.
Vamos revisar a tabela Delta Lake com a seguinte instrução:
Métricas Operacionais
Você pode se aprofundar nas métricas operacionais examinando o Histórico da Tabela Delta Lake (coluna operationMetrics) na Spark UI executando a seguinte instrução:
Abaixo está uma saída abreviada do comando anterior.
Você notará duas versões da tabela, uma para o esquema antigo e outra para o novo esquema. Ao revisar as métricas operacionais abaixo, ela indica que houve 39 linhas inseridas e 1 linha atualizada.
Você pode entender mais sobre os detalhes por trás dessas métricas operacionais indo para a aba SQL dentro da Spark UI.
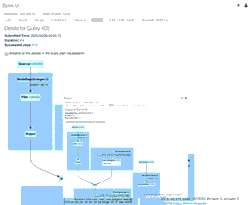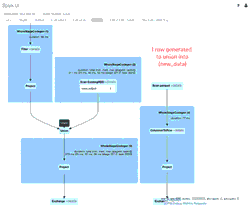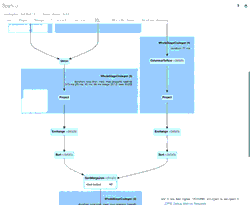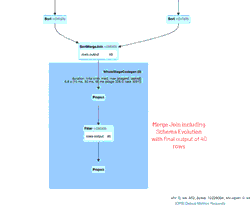
O GIF animado destaca os principais componentes da Spark UI para sua revisão.
- 39 linhas iniciais de um arquivo (para 11/04/2020 com o novo esquema) que criaram o DataFrame new_data inicial
- 1 linha de atualização simulada gerada que seria unida ao DataFrame new_data
- 1 linha de um arquivo (para 21/03/2020 com o esquema antigo) que criou o DataFrame old_data.
- Um SortMergeJoin usado para unir os dois DataFrames para serem persistidos em nossa tabela Delta Lake.
Para se aprofundar em como interpretar essas métricas operacionais, confira o tech talk Diving into Delta Lake Part 3: How do DELETE, UPDATE, and MERGE work.

Comece com o Delta Lake 0.6.0
Experimente o Delta Lake com os trechos de código anteriores em sua instância Apache Spark 2.4.5 (ou superior) (no Databricks, experimente com DBR 6.6+). O Delta Lake torna seus data lakes mais confiáveis (seja você criando um novo ou migrando um data lake existente). Para saber mais, consulte https://delta.io/ e junte-se à comunidade Delta Lake via Slack e Google Group. Você pode acompanhar todos os próximos lançamentos e recursos planejados em GitHub milestones. Você também pode experimentar o Delta Lake Gerenciado no Databricks com uma conta gratuita.
Créditos
Queremos agradecer aos seguintes contribuidores por atualizações, alterações de documentação e contribuições no Delta Lake 0.6.0: Ali Afroozeh, Andrew Fogarty, Anurag870, Burak Yavuz, Erik LaBianca, Gengliang Wang, IonutBoicuAms, Jakub Orłowski, Jose Torres, KevinKarlBob, Michael Armbrust, Pranav Anand, Rahul Govind, Rahul Mahadev, Shixiong Zhu, Steve Suh, Tathagata Das, Timothy Zhang, Tom van Bussel, Wesley Hoffman, Xiao Li, chet, Eugene Koifman, Herman van Hovell, hongdd, lswyyy, lys0716, Mahmoud Mahdi, Maryann Xue
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.