Parte 1: Implementando CI/CD no Databricks Usando Notebooks do Databricks e Azure DevOps
por Michael Shtelma e Piotr Majer
O código discutido pode ser encontrado aqui.
Esta é a primeira parte de uma série de dois posts que mostram como configurar e construir solu�ções de MLOps de ponta a ponta no Databricks com notebooks e a API de Repositórios. Este post apresenta um framework de CI/CD no Databricks, baseado em notebooks. O pipeline se integra ao ecossistema Microsoft Azure DevOps para a parte de Integração Contínua (CI) e à API de Repositórios para a Entrega Contínua (CD). No segundo post, mostraremos como alavancar a funcionalidade da API de Repositórios para implementar um ciclo de vida completo de CI/CD no Databricks e estendê-lo para uma solução MLOps completa.
CI/CD com Databricks Repos
Felizmente, com a nova funcionalidade fornecida pelo Databricks Repos e a API de Repositórios, estamos bem equipados para cobrir todos os aspectos chave de controle de versão, testes e pipelines que sustentam as abordagens de MLOps. O Databricks Repos permite clonar repositórios Git inteiros no Databricks e, com a ajuda da API de Repositórios, podemos automatizar esse processo, clonando primeiro um repositório Git e depois selecionando o branch de interesse. Os profissionais de ML agora podem usar uma estrutura de repositório bem conhecida de IDEs para estruturar seus projetos, confiando em notebooks ou arquivos .py para implementação de módulos (com suporte para formatos de arquivo arbitrários em Repos planejado no roadmap). Portanto, todo o projeto é versionado por uma ferramenta de sua escolha (Github, Gitlab, Azure Repos, para citar alguns) e se integra muito bem com pipelines comuns de CI/CD. A API do Databricks Repos nos permite atualizar um repositório (projeto Git selecionado como repositório no Databricks) para a versão mais recente de um branch Git específico.
As equipes podem seguir o ciclo clássico do Git flow ou GitHub flow durante o desenvolvimento. O repositório Git inteiro pode ser clonado com o Databricks Repos. Os usuários poderão usar e editar os notebooks, bem como arquivos Python puros ou outros tipos de arquivos de texto com suporte a arquivos arbitrários. Isso nos permite usar a estrutura clássica do projeto, importando módulos de arquivos Python e combinando-os com notebooks:
- Desenvolver funcionalidades individuais em um branch de funcionalidade e testar usando testes unitários (por exemplo, notebooks implementados).
- Enviar alterações para o branch de funcionalidade, onde o pipeline de CI/CD executará o teste de integração.
- Pipelines de CI/CD no Azure DevOps podem acionar a API do Databricks Repos para atualizar este projeto de teste para a versão mais recente.
- Pipelines de CI/CD acionam o job de teste de integração através da API de Jobs. Os testes de integração podem ser implementados como um notebook simples que primeiro executará os pipelines que gostaríamos de testar com configurações de teste. Isso pode ser feito simplesmente executando um notebook apropriado com a execução dos módulos correspondentes ou acionando o job real usando a API de Jobs.
- Examinar os resultados para marcar toda a execução do teste como aprovada ou reprovada.
Vamos agora examinar como podemos implementar a abordagem descrita acima. Como um fluxo de trabalho exemplar, focaremos nos dados provenientes da competição Kaggle Lending Club. Semelhante a muitas instituições financeiras, gostaríamos de entender e prever dados de renda individual, por exemplo, para avaliar o score de crédito de uma aplicação. Para isso, analisamos vários recursos e atributos do candidato, desde ocupação atual, propriedade de imóvel, educação até dados de localização, estado civil e idade. Esta é a informação que um banco coletou (por exemplo, em aplicações de crédito anteriores) e que agora é usada para treinar um modelo de regressão.
Além disso, sabemos que nosso negócio muda dinamicamente e há um alto volume de novas observações diariamente. Com a ingestão regular de novos dados, o retreinamento do modelo é crucial. Portanto, o foco está na automação completa dos jobs de retreinamento, bem como de todo o pipeline de implantação contínua. Para garantir resultados de alta qualidade e alto poder preditivo de um modelo recém-treinado, adicionamos uma etapa de avaliação após cada job treinado. Aqui, o modelo de ML é pontuado em um conjunto de dados curado e comparado com a versão de produção atualmente implantada. Portanto, a promoção do modelo só pode ocorrer se a nova iteração tiver alto poder preditivo.
Como um projeto está ativamente em desenvolvimento e sendo trabalhado, os testes totalmente automatizados de novo código e a promoção para o próximo estágio do ciclo de vida utilizam o framework Azure DevOps para avaliação unitária/de integração em requisições de push/pull. Os testes são orquestrados através do framework Azure DevOps e executados na plataforma Databricks. Isso cobre a parte de CI do processo, garantindo alta cobertura de testes em nossa base de código, minimizando a supervisão humana.
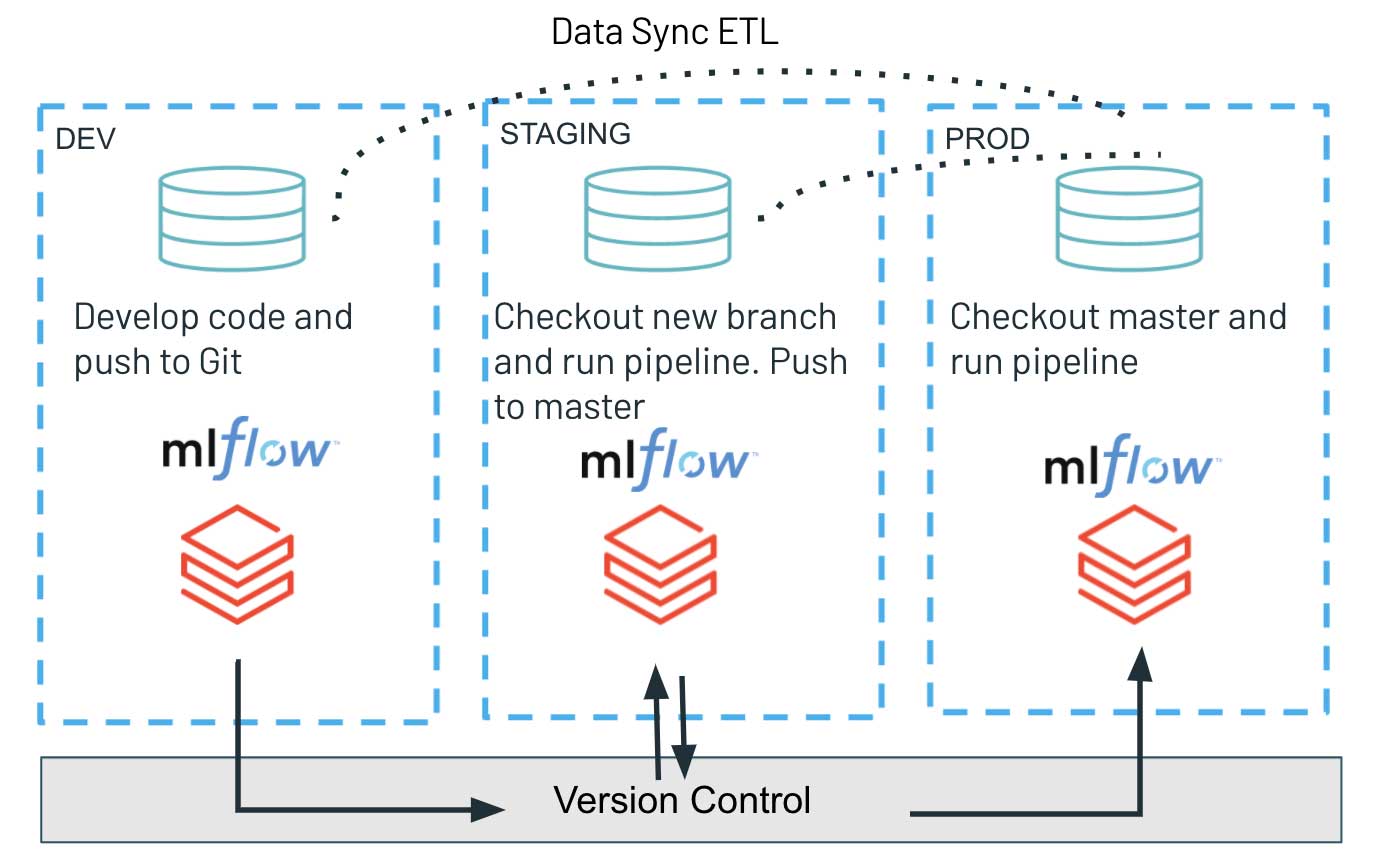
A parte de entrega contínua depende exclusivamente da API de Repositórios, onde usamos a interface programática para selecionar a versão mais recente de nosso código no branch Git e implantar os scripts mais recentes para executar a carga de trabalho. Isso nos permite simplificar o processo de implantação de artefatos e promover facilmente a versão de código testada de ambientes de desenvolvimento através de staging para produção. Tal arquitetura garante o isolamento completo de vários ambientes e é tipicamente favorecida em ambientes de segurança aumentada. Os diferentes estágios: dev, staging e prod compartilham apenas o sistema de controle de versão, minimizando interferências potenciais com cargas de trabalho de produção de alta criticidade. Ao mesmo tempo, o trabalho exploratório e a inovação são desacoplados, pois o ambiente de desenvolvimento pode ter controles de acesso mais flexíveis.
Implementar pipeline de CI/CD usando Azure DevOps e Databricks
No seguinte repositório de código, implementamos o projeto de ML com um pipeline de CI/CD alimentado pelo Azure DevOps. Neste projeto, usamos notebooks para preparação de dados e treinamento de modelos.
Vamos ver como podemos testar esses notebooks no Databricks. O Azure DevOps é um framework muito popular para fluxos de trabalho completos de CI/CD disponíveis no Azure. Para mais informações, por favor, consulte a visão geral das funcionalidades fornecidas e integrações contínuas com Databricks.
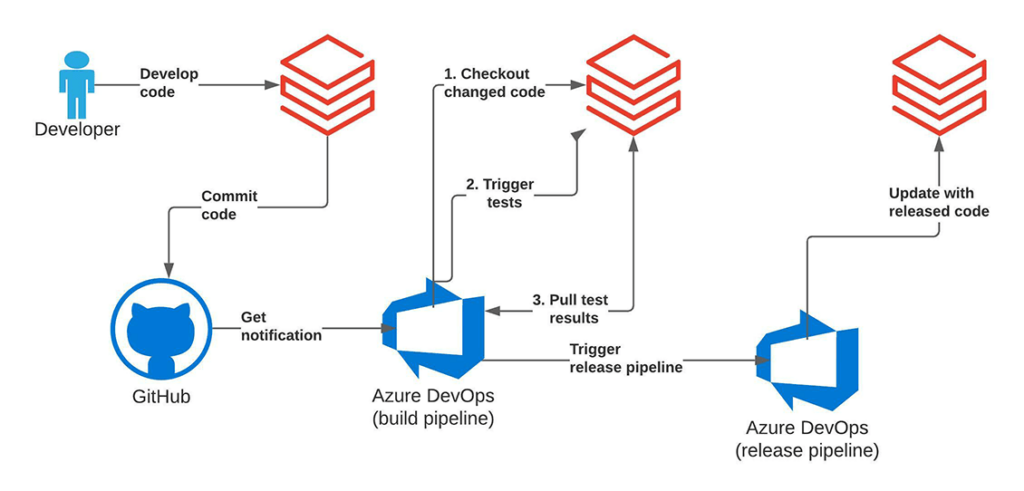
Estamos usando o pipeline do Azure DevOps como um arquivo YAML. O pipeline trata os notebooks do Databricks como arquivos Python simples, para que possamos executá-los dentro de nosso pipeline de CI/CD. Colocamos um arquivo YAML para nosso pipeline de CI/CD do Azure dentro de azure-pipelines.yml. A parte mais interessante deste arquivo é uma chamada para a API do Databricks Repos para atualizar o estado do projeto de CI/CD no Databricks e uma chamada para a API de Jobs do Databricks para acionar a execução do job de teste de integração. Desenvolvemos ambos esses itens no script/notebook deploy.py. Podemos chamá-lo da seguinte forma dentro do pipeline do Azure DevOps:
As variáveis de ambiente DATABRICKS_HOST e DATABRICKS_TOKEN são necessárias pelo pacote databricks_cli para nos autenticar no workspace Databricks que estamos usando. Essas variáveis podem ser gerenciadas através de grupos de variáveis do Azure DevOps.
Vamos examinar o script deploy.py agora. Dentro do script, estamos usando a API databricks_cli para trabalhar com a API de Jobs do Databricks. Primeiro, precisamos criar um cliente de API:
Depois disso, podemos criar um novo Repositório temporário no Databricks para nosso projeto e baixar a revisão mais recente de nosso Repositório recém-criado:
Em seguida, podemos iniciar a execução do job de teste de integração no Databricks:
Finalmente, esperamos o job concluir e examinamos o resultado:
Trabalhando com múltiplos workspaces
Usar a API Databricks Repos para CI/CD pode ser particularmente útil para equipes que buscam isolamento completo entre seus ambientes de desenvolvimento/staging e produção. O novo recurso permite que as equipes de dados, através do código-fonte no Databricks, implementem a base de código e os artefatos atualizados de uma carga de trabalho por meio de uma interface de comando simples em múltiplos ambientes. Ser capaz de fazer checkout programaticamente da base de código mais recente no sistema de controle de versão garante um processo de lançamento simples e dentro do prazo.
Para práticas de MLOps, existem inúmeras considerações importantes sobre a configuração arquitetural correta entre vários ambientes. Neste estudo, focamos apenas no paradigma de isolamento total, que também cobriria múltiplas instâncias de MLflow associadas a dev/staging/prod. Nesse sentido, os modelos treinados em um ambiente de desenvolvimento não seriam promovidos para o próximo estágio, pois os objetos serializados são carregados através de um único Model Registry comum. O único artefato implantado é a nova base de código do pipeline de treinamento que é lançada e executada no ambiente de STAGING, resultando em um novo modelo treinado e registrado com MLflow.
Este princípio de compartilhamento, juntamente com o gerenciamento rigoroso de permissões nos ambientes de produção/staging, mas com padrões de acesso mais flexíveis no ambiente de desenvolvimento, permite um desenvolvimento de software robusto e de alta qualidade. Simultaneamente, oferece um maior grau de liberdade na instância de desenvolvimento, acelerando a inovação e a experimentação em toda a equipe de dados.
Resumo
Neste post, apresentamos uma abordagem ponta a ponta para pipelines de CI/CD no Databricks usando projetos baseados em notebooks. Este fluxo de trabalho é baseado na funcionalidade da API Repos, que não só permite que as equipes de dados estruturem e controlem a versão de seus projetos de forma mais prática, mas também simplifica muito a implementação e execução das ferramentas de CI/CD. Demonstramos uma arquitetura na qual todos os ambientes operacionais são totalmente isolados, garantindo um alto grau de segurança para cargas de trabalho de produção impulsionadas por ML.
Os pipelines de CI/CD são alimentados por um framework de escolha e se integram perfeitamente à Plataforma de Análise Unificada do Databricks, acionando a execução do código e o provisionamento de infraestrutura de ponta a ponta. A API Repos simplifica radicalmente não apenas o gerenciamento de versões, a estruturação do código e a parte de desenvolvimento do ciclo de vida de um projeto, mas também a entrega contínua, permitindo implantar os artefatos de produção e o código entre ambientes. É uma melhoria importante que contribui para a eficiência e escalabilidade geral do Databricks e melhora muito a experiência do desenvolvedor de software.
O código discutido pode ser encontrado aqui.
Referências:
- https://www.databricks.com/blog/2021/06/23/need-for-data-centric-ml-platforms.html
- Continuous Delivery for Machine Learning, Martin Fowler, https://martinfowler.com/articles/cd4ml.html,
- Overview of MLOps, https://www.kdnuggets.com/2021/03/overview-mlops.htm Introducing Azure DevOps, https://azure.microsoft.com/en-us/blog/introducing-azure-devops/
- Continuous integration and delivery on Azure Databricks using Azure DevOps, https://docs.microsoft.com/en-us/azure/databricks/dev-tools/ci-cd/ci-cd-azure-devops
- Lending club Kaggle data set https://www.kaggle.com/wordsforthewise/lending-club
- Repos for Git integration https://docs.databricks.com/repos.html
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.