Escalonando cálculos SHAP com PySpark e Pandas UDF
por Sepideh Ebrahimi e P. Patel
Motivação
Com a proliferação de aplicações de modelos de Machine Learning (ML) e especialmente de aprendizagem profunda (DL) na tomada de decisões, está se tornando mais crucial ver através da caixa-preta e justificar as principais decisões de negócios com base nos resultados de tais modelos. Por exemplo, se um modelo de ML rejeita a solicitação de empréstimo de um cliente ou atribui um risco de crédito em empréstimos peer-to-peer a um determinado cliente, dar aos stakeholders de negócios uma explicação sobre o porquê dessa decisão ter sido tomada pode ser uma ferramenta poderosa para incentivar a adoção dos modelos. Em muitos casos, ML interpretável não é apenas um requisito de negócio, mas também um requisito regulatório para entender por que uma determinada decisão ou opção foi dada a um cliente. SHapley Additive exPlanations (SHAP) é uma ferramenta importante que pode ser aproveitada para uma AI explicável e para ajudar a estabelecer confiança no resultado de modelos de ML e redes neurais na solução de problemas de negócios.
SHAP é um framework de ponta para explicabilidade de modelos baseado em Teoria dos Jogos. A abordagem envolve encontrar uma relação linear entre os recursos de um modelo e a saída do modelo para cada ponto de dados em seu dataset. Usando este framework, você pode interpretar a saída do seu modelo global ou localmente. A interpretabilidade global ajuda a entender o quanto cada recurso contribui para os resultados, positiva ou negativamente. Por outro lado, a interpretabilidade local ajuda a entender o efeito de cada recurso para uma determinada observação.
As implementações SHAP mais comuns, amplamente adotadas na comunidade de ciência de dados, são executadas em máquinas de nó único, o que significa que executam todos os cálculos em um único núcleo, independentemente de quantos núcleos estejam disponíveis. Portanto, elas não aproveitam as capacidades de computação distribuída e são limitadas pelas restrições de um único núcleo.
Neste post, vamos demonstrar uma forma simples de paralelizar os cálculos de valor SHAP em várias máquinas, especificamente para interpretabilidade local. Em seguida, explicaremos como essa solução escala com o número crescente de linhas e colunas no dataset. Por fim, destacaremos algumas das nossas descobertas sobre o que funciona e o que evitar ao paralelizar os cálculos de SHAP com o Spark.
SHAP de nó único
Para obter a explicabilidade, o SHAP transforma um modelo em um Explainer; as previsões individuais do modelo são então explicadas aplicando o Explainer a elas. Existem várias implementações de cálculos de valor SHAP em diferentes linguagens de programação, incluindo uma popular em Python. Com essa implementação, para obter explicações para cada observação, você pode aplicar um Explainer apropriado para o seu modelo. O trecho de código a seguir ilustra como aplicar um TreeExplainer a um Classificador Random Forest.
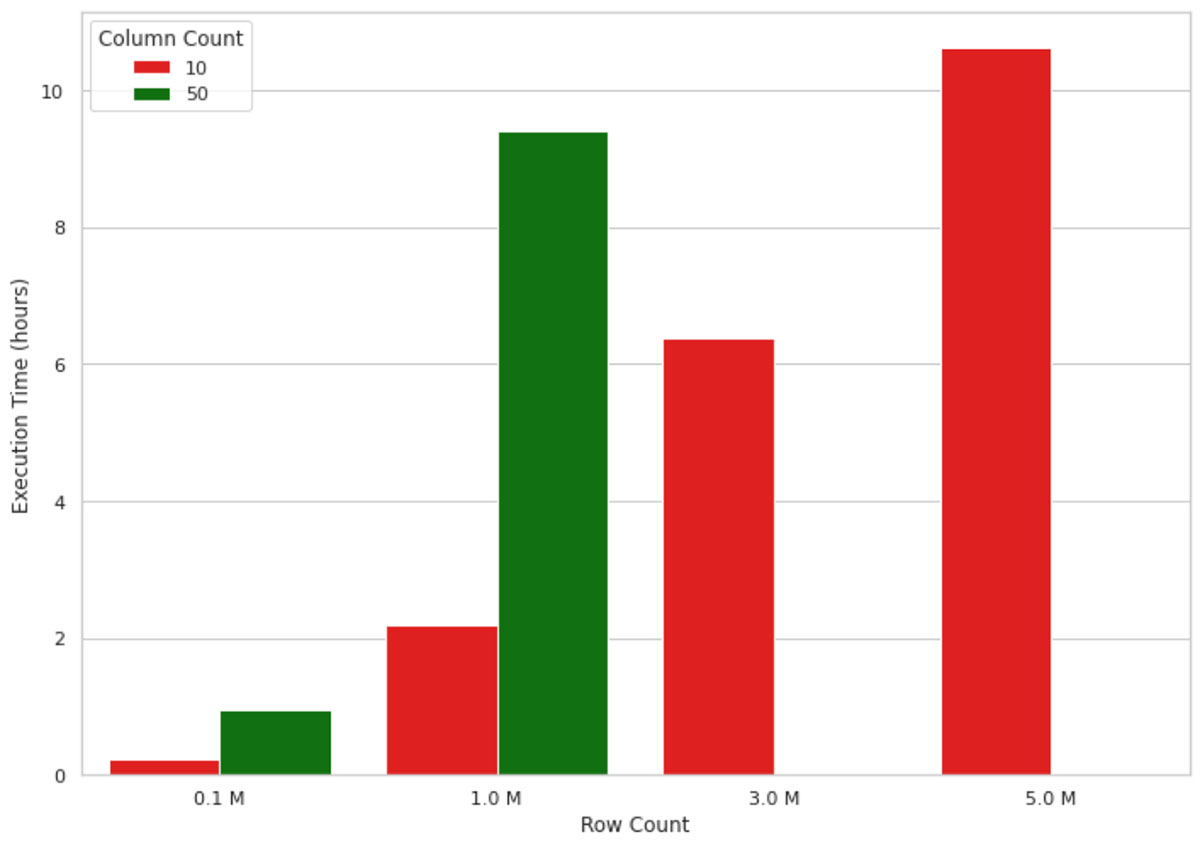
Este método funciona bem para pequenos volumes de dados, mas quando se trata de explicar a saída de um modelo de ML para milhões de registros, ele não escala bem devido à natureza de nó único da implementação. Por exemplo, a visualização na figura 1 abaixo mostra o crescimento no tempo de execução de um cálculo de valor SHAP em uma máquina de nó único (4 núcleos e 30,5 GB de memória) para um número crescente de registros. A máquina ficou sem memória para formatos de dados maiores que 1 milhão de linhas e 50 colunas, portanto, esses valores não aparecem na figura. Como você pode ver, o tempo de execução cresce quase linearmente com o número de registros, o que não é sustentável em cenários reais. Esperar, por exemplo, 10 horas para entender por que um modelo do machine learning fez uma previsão não é eficiente nem aceitável em muitos cenários de negócios.
Uma maneira de resolver esse problema é usar o cálculo aproximado. Você pode definir o argumento `approximate` como `True` no método `shap_values`. Dessa forma, as divisões mais baixas na árvore terão pesos maiores e não há garantia de que os valores SHAP sejam consistentes com o cálculo exato. Isso acelerará os cálculos, mas você pode acabar com uma explicação imprecisa da saída do seu modelo. Além disso, o argumento approximate está disponível apenas em TreeExplainers.
Uma abordagem alternativa seria aproveitar um framework de processamento distribuído, como o Apache Spark™, para paralelizar a aplicação do Explainer em múltiplos núcleos.
Escalonando cálculos SHAP com PySpark
Para distribuir os cálculos SHAP, estamos trabalhando com esta implementação em Python e Pandas UDFs em PySpark. Estamos usando o dataset kddcup99 para criar um detector de intrusão de rede, um modelo preditivo capaz de distinguir entre conexões ruins, chamadas de intrusões ou ataques, e conexões boas e normais. Este dataset é conhecido por ter falhas para fins de detecção de intrusão. No entanto, nesta postagem, estamos nos concentrando apenas nos cálculos do valor do SHAP e não na semântica do modelo de ML subjacente.
Os dois modelos que construímos para nossos experimentos são classificadores Random Forest simples, treinados em conjuntos de dados com 10 e 50 recursos para mostrar a escalabilidade da solução em diferentes tamanhos de coluna. Observe que o dataset original tem menos de 50 colunas, e replicamos algumas dessas colunas para alcançar o volume de dados desejado. Os volumes de dados com os quais experimentamos variam de 4 MB a 1,85 GB.
Antes de mergulharmos no código, vamos dar uma visão geral rápida de como os Dataframes e UDFs do Spark funcionam. Os Dataframes do Spark são distribuídos (por linhas) em um cluster, cada agrupamento de linhas é chamado de partição e cada partição (por default) pode ser operada por 1 núcleo. É assim que o Spark fundamentalmente alcança o processamento paralelo. As Pandas UDFs são uma escolha natural, já que o pandas pode facilmente alimentar o SHAP e tem um bom desempenho. Uma UDF do pandas, às vezes conhecida como UDF vetorizada, nos dá um desempenho melhor do que as UDFs do Python, usando o Apache Arrow para otimizar a transferência de dados.
O trecho de código abaixo demonstra como paralelizar a aplicação de um Explainer com uma UDF do Pandas no PySpark. Definimos uma UDF do Pandas chamada calculate_shap e, em seguida, passamos essa função para mapInPandas. Esse método é então usado para aplicar o método paralelizado ao dataframe do PySpark. Usaremos esta UDF para a execução dos nossos testes de desempenho do SHAP.
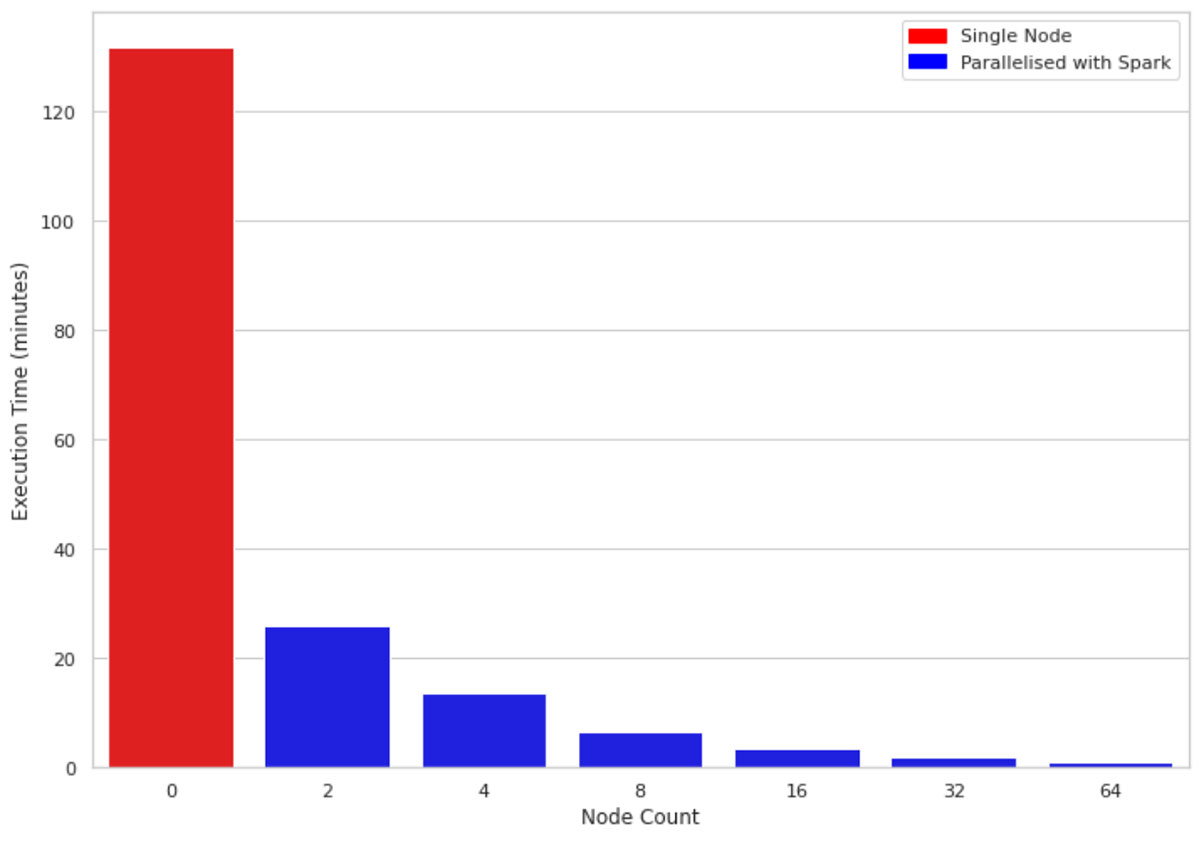
A Figura 2 compara o tempo de execução de 1 milhão de linhas e 10 colunas em uma máquina de nó único versus clusters de tamanhos 2, 4, 8, 16, 32 e 64, respectivamente. As máquinas subjacentes para todos os clusters são semelhantes (4 núcleos e 30,5 GB de memória). Uma observação interessante é que o código paralelizado aproveita todos os núcleos em todos os nós do cluster. Portanto, mesmo usando um cluster de tamanho 2, o desempenho melhora quase 5 vezes.
Escalonamento com o aumento do tamanho dos dados
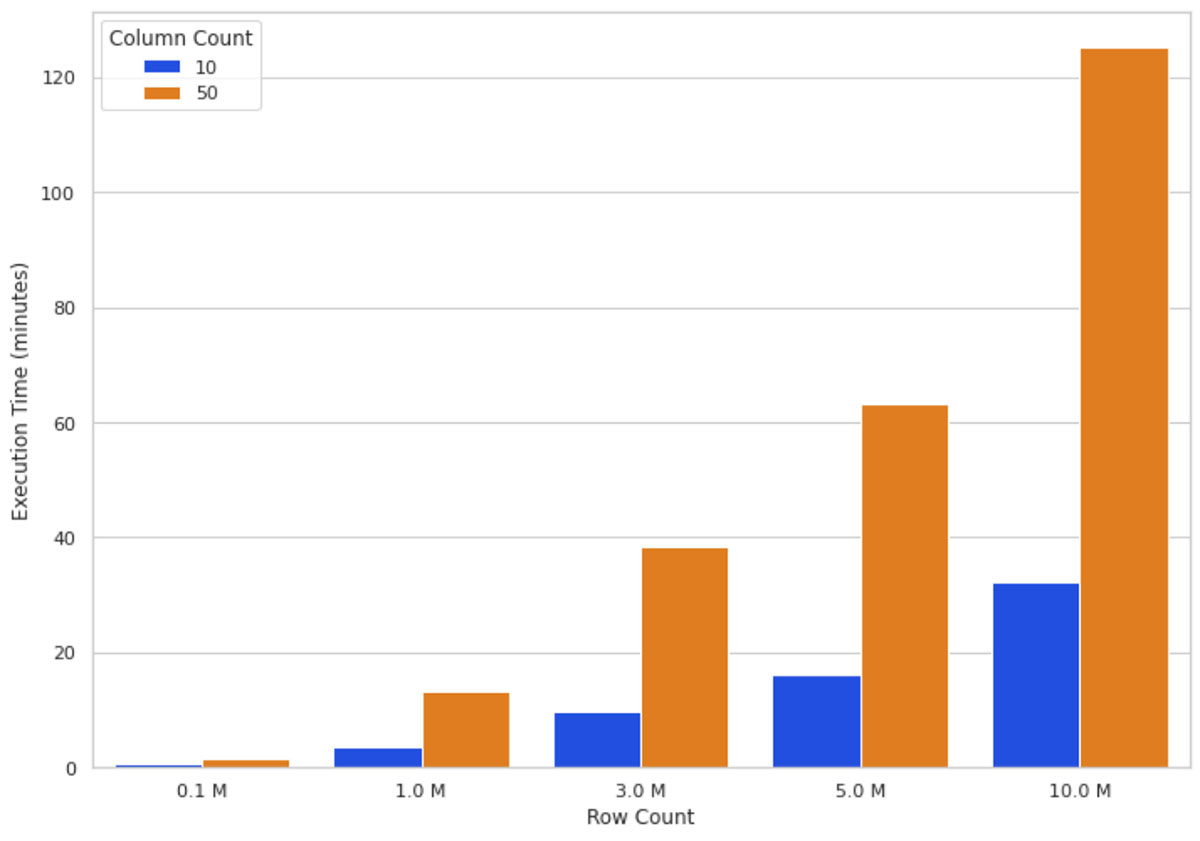
Devido à forma como o SHAP é implementado, recursos adicionais têm um impacto maior no desempenho do que linhas adicionais. Agora sabemos que os valores SHAP podem ser calculados mais rapidamente usando Spark e Pandas UDF. A seguir, veremos como o SHAP se comporta com recursos/colunas adicionais.
Intuitivamente, o aumento do tamanho dos dados significa mais cálculos a serem processados pelo algoritmo SHAP. A Figura 3 ilustra os tempos de execução dos valores SHAP em um cluster de 16 nós para diferentes números de linhas e colunas. Você pode ver que escalonar as linhas aumenta o tempo de execução de forma quase diretamente proporcional, ou seja, dobrar a contagem de linhas quase dobra o tempo de execução. Escalonar o número de colunas tem uma relação proporcional com o tempo de execução; adicionar uma coluna aumenta o tempo de execução em quase 80%.
Essas observações (Figura 2 e Figura 3) nos levaram a concluir que, quanto mais dados você tiver, mais poderá escalar sua computação horizontalmente (adicionando mais nós de worker) para manter o tempo de execução razoável.
Quando considerar a paralelização?
As perguntas que queríamos responder são: quando a paralelização vale a pena? Quando se deve começar a usar o PySpark para paralelizar os cálculos SHAP, mesmo sabendo que isso pode aumentar a computação? Montamos um experimento para medir o efeito de dobrar o tamanho do cluster na melhoria do tempo de execução do cálculo SHAP. O objetivo do experimento é descobrir qual tamanho de dados justifica a alocação de mais recursos horizontais (ou seja, adicionar mais nós worker) para o problema.
Executamos os cálculos SHAP para 10 colunas de dados e para contagens de linhas de 10, 100, 1000 e assim por diante, até 10 milhões. Para cada contagem de linhas, medimos o tempo de execução do cálculo SHAP 4 vezes para tamanhos de cluster de 2, 4, 32 e 64. A razão do tempo de execução é a razão entre o tempo de execução do cálculo do valor SHAP nos tamanhos de cluster maiores (4 e 64) e a execução do mesmo cálculo em um tamanho de cluster com metade do número de nós (2 e 32, respectivamente).
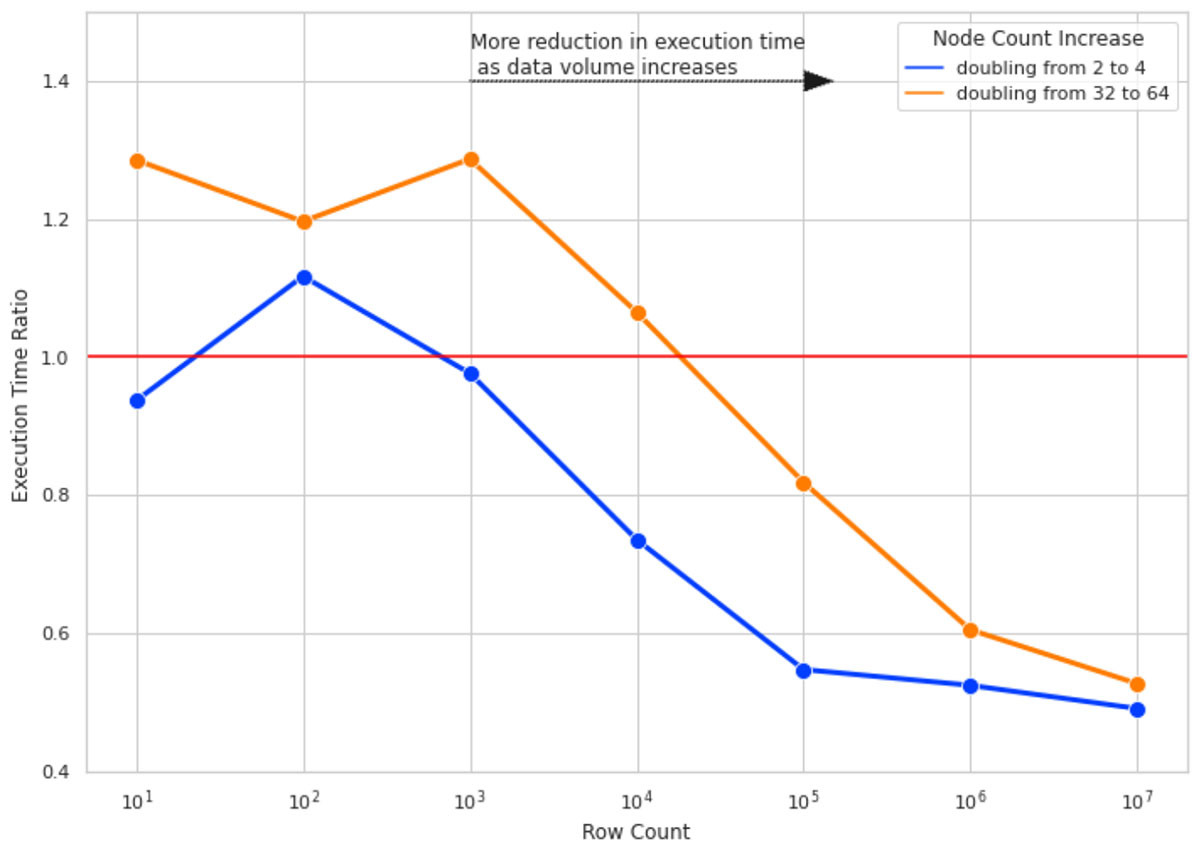
A Figura 4 ilustra o resultado deste experimento. Aqui estão as principais conclusões:
-
- Para contagens de linhas pequenas, dobrar o tamanho dos clusters não melhora o tempo de execução e, em alguns casos, o piora, devido à sobrecarga adicionada pelo gerenciamento de tarefas do Spark (daí a Razão de Tempo de Execução > 1).
- À medida que aumentamos o número de linhas, dobrar o tamanho do cluster se torna mais eficaz. Para 10 milhões de linhas de dados, dobrar o tamanho do cluster quase reduz o tempo de execução pela metade.
- Para todas as contagens de linhas, dobrar o tamanho do cluster de 2 para 4 é mais eficaz do que dobrar de 32 para 64 (observe a diferença entre as linhas azul e laranja). À medida que o tamanho do seu cluster aumenta, a sobrecarga de adicionar mais nós também aumenta. Isso se deve a termos tamanhos de partição onde o volume de dados por partição é muito pequeno, e isso adiciona mais sobrecarga para criar uma tarefa separada para processar a pequena quantidade de dados do que usar um tamanho de dados/partição mais otimizado.
Gotchas
Reparticionamento
Conforme mencionado acima, o Spark implementa o paralelismo por meio da noção de partições; os dados são particionados em blocos de linhas e cada partição é processada por um único núcleo por default. Quando os dados são lidos inicialmente pelo Apache Spark, ele pode não necessariamente criar partições que sejam ideais para a computação que você deseja executar em seu cluster. Especificamente, para calcular os valores SHAP, podemos obter um melhor desempenho reparticionando nosso dataset.
É importante encontrar um equilíbrio entre criar partições pequenas o suficiente e não tão pequenas a ponto de a sobrecarga de criá-las superar os benefícios de paralelizar os cálculos.
Para nosso teste de desempenho, decidimos usar todos os núcleos do cluster usando o seguinte código:
Para volumes de dados ainda maiores, você pode querer definir o número de partições como 2 ou 3 vezes o número de núcleos. A chave é experimentar e descobrir a melhor estratégia de particionamento para seus dados.
Uso de display()
Se você estiver trabalhando em um Databricks Notebook, talvez queira evitar o uso da função display() ao fazer o benchmarking dos tempos de execução. O uso de display() pode não necessariamente mostrar quanto tempo leva uma transformação completa; ele tem um limite de linha implícito, que é injetado na query e, dependendo da operação que você deseja medir, por exemplo, gravar em um arquivo, há uma sobrecarga adicional na coleta dos resultados de volta para o driver. Nossos tempos de execução foram medidos usando o método write do Spark com o formato “noop”.
Conclusão
Nesta postagem no blog, apresentamos uma solução para acelerar os cálculos SHAP, paralelizando-os com PySpark e UDFs do Pandas. Em seguida, avaliamos o desempenho da solução em volumes crescentes de dados, diferentes tipos de máquina e configurações variáveis. Aqui estão as principais conclusões:
-
-
- O cálculo SHAP de nó único cresce linearmente com o número de linhas e colunas.
- A paralelização de cálculos SHAP com o PySpark melhora o desempenho ao executar a computação em todas as CPUs do seu cluster.
- Aumentar o tamanho do cluster é mais eficaz quando você tem maiores volumes de dados. Para dados pequenos, este método não é eficaz.
-
Trabalhos futuros
Escalonamento vertical - O objetivo desta postagem no blog foi mostrar como o escalonamento horizontal com grandes datasets pode melhorar o desempenho do cálculo de valores SHAP. Partimos da premissa de que cada nó em nosso cluster tinha 4 núcleos e 30,5 GB. No futuro, seria interessante testar o desempenho do escalonamento vertical e também do horizontal; por exemplo, comparando o desempenho entre um cluster de 4 nós (4 núcleos, 30,5 GB cada) com um cluster de 2 nós (8 núcleos, 61 GB cada).
Serializar/Desserializar - Como mencionado, uma das principais razões para usar UDFs do Pandas em vez de UDFs do Python é que as UDFs do Pandas usam o Apache Arrow para melhorar a serialização/desserialização de dados entre a JVM e o processo Python. Pode haver algumas otimizações em potencial ao converter partições de dados do Spark em lotes de registros do Arrow; experimentar com o tamanho do lote do Arrow poderia levar a mais ganhos de desempenho.
Comparação com implementações SHAP distribuídas - Seria interessante comparar os resultados de nossa solução com implementações distribuídas de SHAP, como o Shparkley. Ao conduzir tal estudo comparativo, seria importante garantir que os resultados de ambas as soluções sejam comparáveis em primeiro lugar.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.