Organização Funcional do Workspace no Databricks
Essenciais para Administradores Databricks: Blog 1/5
por Anindita Mahapatra e Greg Wood
Introdução
Este blog é a primeira parte da nossa série Admin Essentials, onde abordaremos tópicos importantes para quem gerencia e mantém ambientes Databricks. Fique atento para blogs adicionais sobre governança de dados, operações e automação, gerenciamento de usuários e acessibilidade, e rastreamento e gerenciamento de custos em breve!
Em 2020, a Databricks começou a lançar prévias privadas de vários recursos da plataforma, conhecidos coletivamente como Enterprise 2.0 (ou E2); esses recursos forneceram a próxima iteração da plataforma Lakehouse, criando a escalabilidade e a segurança para corresponder à potência e velocidade já disponíveis no Databricks. Quando o Enterprise 2.0 foi disponibilizado publicamente, uma das adições mais aguardadas foi a capacidade de criar vários workspaces a partir de uma única conta. Esse recurso abriu novas possibilidades de colaboração, alinhamento organizacional e simplificação. No entanto, como descobrimos desde então, ele também levantou uma série de questões. Com base em nossa experiência com clientes corporativos de todos os tamanhos, formatos e setores, este blog apresentará respostas e melhores práticas para as perguntas mais comuns sobre gerenciamento de workspaces no Databricks; em um nível fundamental, isso se resume a uma pergunta simples: exatamente quando um novo workspace deve ser criado? Especificamente, destacaremos as principais estratégias para organizar seus workspaces e as melhores práticas de cada uma.
Noções básicas de organização de workspace
Embora cada provedor de nuvem (AWS, Azure e GCP) tenha uma arquitetura subjacente diferente, a organização dos workspaces Databricks entre as nuvens é semelhante. A construção lógica de nível superior é uma conta mestre E2 (AWS) ou um objeto de assinatura (Azure Databricks/GCP). Na AWS, provisionamos uma única conta E2 por organização que fornece um painel unificado de visibilidade e controle para todos os workspaces. Dessa forma, sua atividade de administração é centralizada, com a capacidade de habilitar SSO, Logs de Auditoria e Unity Catalog. O Azure tem relativamente menos restrições na criação de objetos de assinatura de nível superior; no entanto, ainda recomendamos que o número de assinaturas de nível superior usadas para criar workspaces Databricks seja controlado o máximo possível. Referiremos à construção de nível superior como uma conta ao longo deste blog, seja uma conta E2 da AWS ou uma assinatura GCP/Azure.
Dentro de uma conta de nível superior, vários workspaces podem ser criados. O máximo recomendado de workspaces por conta é entre 20 e 50 no Azure, com um limite rígido na AWS. Esse limite decorre da sobrecarga administrativa que advém de um número crescente de workspaces: gerenciar colaboração, acesso e segurança em centenas de workspaces pode se tornar uma tarefa extremamente difícil, mesmo com processos de automação excepcionais. Abaixo, apresentamos um modelo de objeto de alto nível de uma conta Databricks.
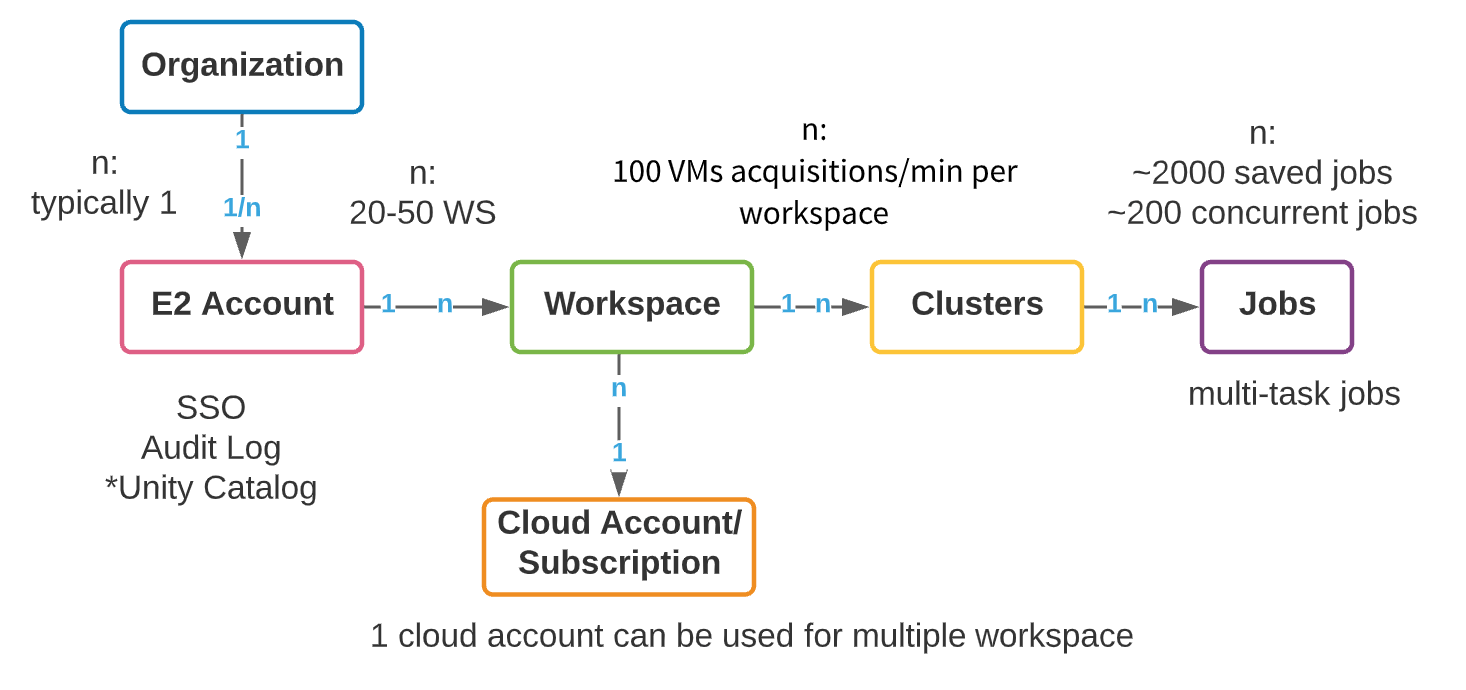
As empresas precisam criar recursos em suas contas de nuvem para dar suporte a requisitos de multilocação. A criação de contas de nuvem e workspaces separados para cada novo caso de uso tem algumas vantagens claras: facilidade de rastreamento de custos, isolamento de dados e usuários, e um raio de explosão menor em caso de incidentes de segurança. No entanto, a proliferação de contas traz seu próprio conjunto de complexidades – governança, gerenciamento de metadados e sobrecarga de colaboração crescem junto com o número de contas. A chave, é claro, é o equilíbrio. Abaixo, abordaremos primeiro algumas considerações gerais para a organização de workspaces corporativos; em seguida, abordaremos duas estratégias comuns de isolamento de workspaces que vemos entre nossos clientes: baseada em LOB (Linha de Negócios) e baseada em produto. Cada uma tem pontos fortes, fracos e complexidades que discutiremos antes de fornecer as melhores práticas.
Considerações gerais de organização de workspace
Ao projetar sua estratégia de workspace, a primeira coisa que vemos os clientes fazerem é pular para as escolhas organizacionais de macro-nível; no entanto, existem muitas decisões de nível inferior que são igualmente importantes! Compilamos as mais pertinentes abaixo.
Uma abordagem simples de três workspaces
Embora dediquemos a maior parte deste blog falando sobre como dividir seus workspaces para obter o máximo de eficácia, há uma classe inteira de clientes Databricks para os quais um único workspace unificado por ambiente é mais do que suficiente! De fato, isso se tornou cada vez mais prático com o surgimento de recursos como Repos, Unity Catalog, páginas de destino baseadas em persona, etc. Nesses casos, ainda recomendamos a separação de workspaces de Desenvolvimento, Staging e Produção para fins de validação e QA. Isso cria um ambiente ideal para pequenas empresas ou equipes que valorizam a agilidade em detrimento da complexidade.
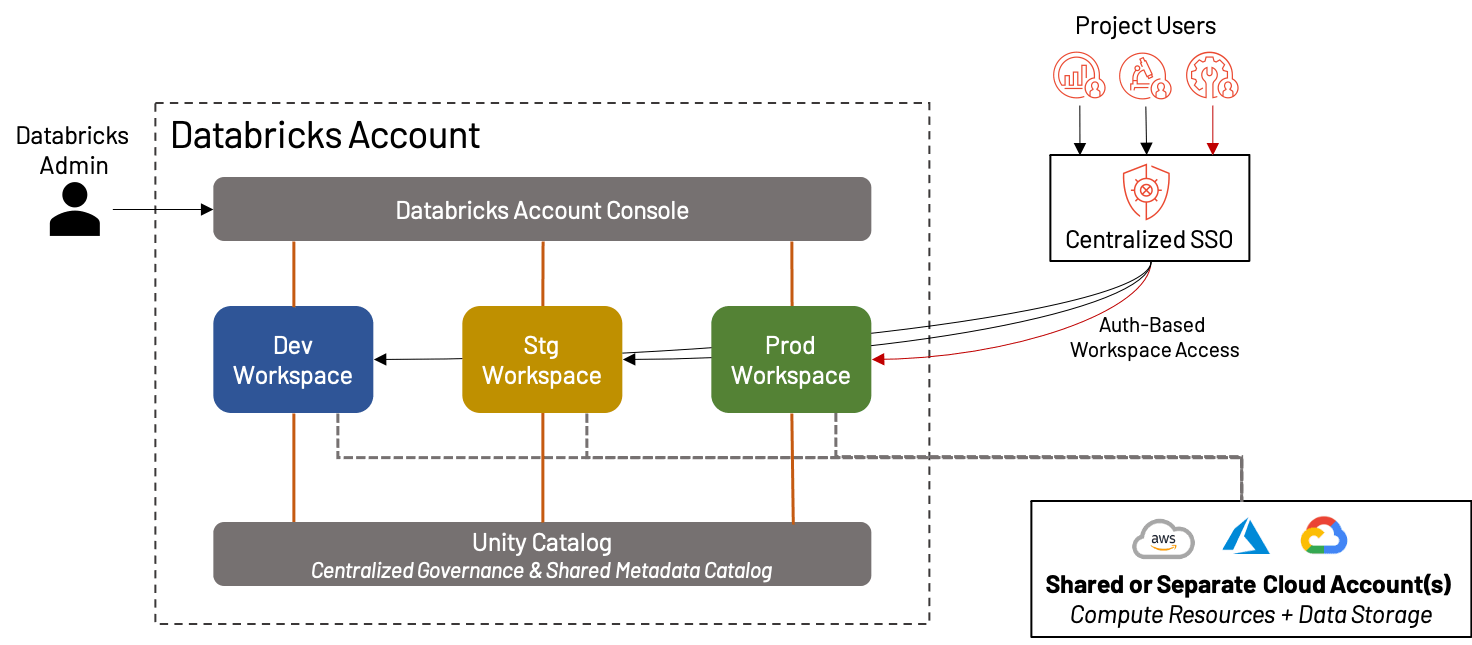
Os benefícios e desvantagens de criar um único conjunto de workspaces são:
+ Não há preocupação em poluir o workspace internamente, misturar ativos ou diluir custos/uso entre vários projetos/equipes; tudo está no mesmo ambiente
+ A simplicidade da organização significa menor sobrecarga administrativa
- Para organizações maiores, um único workspace de desenvolvimento/staging/produção é insustentável devido a limites da plataforma, poluição, incapacidade de isolar dados e preocupações com governança
Se um único conjunto de workspaces parece ser a abordagem certa para você, as seguintes melhores práticas ajudarão a manter sua Lakehouse operando sem problemas:
- Defina um processo padronizado para mover código entre os vários ambientes; como há apenas um conjunto de ambientes, isso pode ser mais simples do que com outras abordagens. Aproveite recursos como Repos e Secrets e ferramentas externas que promovem bons processos de CI/CD para garantir que suas transições ocorram de forma automática e tranquila.
- Estabeleça e revise regularmente grupos do Provedor de Identidade que são mapeados para ativos Databricks; como esses grupos são o principal impulsionador da autorização do usuário nesta estratégia, é crucial que eles sejam precisos e que mapeiem para os dados e recursos de computação subjacentes apropriados. Por exemplo, a maioria dos usuários provavelmente não precisa de acesso ao workspace de produção; apenas um pequeno número de engenheiros ou administradores pode ter as permissões.
- Fique de olho no seu uso e conheça os Limites de Recursos do Databricks; se o uso do seu workspace ou o número de usuários começar a crescer, você pode precisar considerar a adoção de uma estratégia de organização de workspace mais elaborada para evitar limites por workspace. Utilize tags de recursos sempre que possível para rastrear custos e métricas de uso.
Aproveitando workspaces sandbox
Em qualquer uma das estratégias mencionadas neste artigo, um ambiente sandbox é uma boa prática para permitir que os usuários incubem e desenvolvam trabalhos menos formais, mas ainda assim potencialmente valiosos. Criticamente, esses ambientes sandbox precisam equilibrar a liberdade de explorar dados reais com a proteção contra impactos não intencionais (ou intencionais) nas cargas de trabalho de produção. Uma prática recomendada comum para tais workspaces é hospedá-los em uma conta de nuvem totalmente separada; isso limita muito o raio de impacto dos usuários no workspace. Ao mesmo tempo, a configuração de salvaguardas simples (como Políticas de Cluster, limitando o acesso a dados a conjuntos de dados de "brincadeira" ou limpos, e fechando a conectividade de saída sempre que possível) significa que os usuários podem ter liberdade relativa para fazer (quase) o que quiserem sem precisar de supervisão constante do administrador. Finalmente, a comunicação interna é igualmente importante; se os usuários criarem inadvertidamente um aplicativo incrível no Sandbox que atraia milhares de usuários, ou esperarem suporte de nível de produção para seu trabalho neste ambiente, essas economias administrativas evaporarão rapidamente.
As melhores práticas para workspaces sandbox incluem:
- Use uma conta de nuvem separada que não contenha dados confidenciais ou de produção.
- Configure salvaguardas simples para que os usuários tenham liberdade relativa sobre o ambiente sem precisar de supervisão administrativa.
- Comunique claramente que o ambiente sandbox é "self-service".
Isolamento e sensibilidade de dados
Dados confidenciais estão ganhando proeminência entre nossos clientes em todos os setores; dados que antes eram limitados a provedores de saúde ou processadores de cartão de crédito agora se tornam fonte para entender a análise de pacientes ou o sentimento do cliente, analisar mercados emergentes, posicionar novos produtos e quase tudo mais que você possa imaginar. Essa riqueza de dados vem com alto risco potencial, com ameaças cada vez maiores de violações de dados; por esse motivo, manter dados confidenciais segregados e protegidos é importante, independentemente da estratégia organizacional que você escolher. O Databricks oferece vários meios para proteger dados confidenciais (como ACLs e compartilhamento seguro), e combinado com ferramentas do provedor de nuvem, pode tornar o Lakehouse que você constrói o mais baixo risco possível. Algumas das melhores práticas em torno de Isolamento e Sensibilidade de Dados incluem:
- Entenda suas necessidades exclusivas de segurança de dados; este é o ponto mais importante. Cada negócio tem dados diferentes, e seus dados impulsionarão sua governança.
- Aplique políticas e controles tanto no nível de armazenamento quanto no metastore. As políticas S3 e as ACLs do ADLS devem sempre ser aplicadas usando o princípio do menor privilégio. Utilize o Unity Catalog para aplicar uma camada adicional de controle sobre o acesso aos dados.
- Separe seus dados confidenciais de dados não confidenciais, tanto lógica quanto fisicamente; muitos clientes usam contas de nuvem totalmente separadas (e workspaces Databricks) para dados confidenciais e não confidenciais.
DR e backup regional
Recuperação de Desastres (DR) é um tópico amplo que é importante, quer você use AWS, Azure ou GCP; não cobriremos tudo neste blog, mas focaremos em como as considerações de DR e Regionais se encaixam no design do workspace. Neste contexto, DR implica a criação e manutenção de um workspace em uma região separada do workspace de Produção padrão.
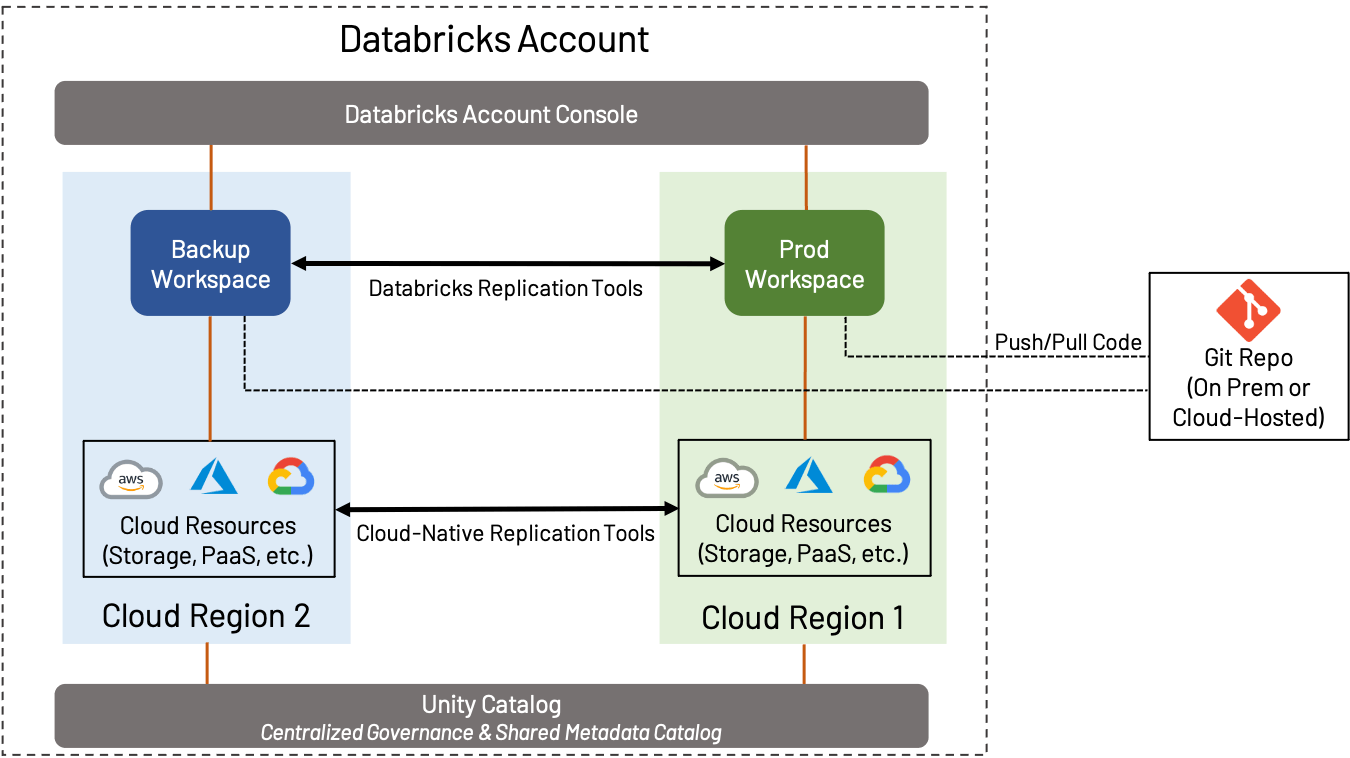
A estratégia de DR pode variar amplamente dependendo das necessidades do negócio. Por exemplo, alguns clientes preferem manter uma configuração ativa-ativa, onde todos os ativos de um workspace são constantemente replicados para um workspace secundário; isso fornece a quantidade máxima de redundância, mas também implica complexidade e custo (transferir dados constantemente entre regiões e realizar replicação e desduplicação de objetos é um processo complicado). Por outro lado, alguns clientes preferem fazer o mínimo necessário para garantir a continuidade dos negócios; um workspace secundário pode conter muito pouco até que ocorra o failover, ou pode ser copiado apenas ocasionalmente. Determinar o nível certo de failover é crucial.
Independentemente do nível de DR que você escolher implementar, recomendamos o seguinte:
- Armazene o código em um repositório Git de sua escolha, seja on-premise ou na nuvem, e use recursos como Repos para sincronizá-lo com o Databricks sempre que possível.
- Sempre que possível, use o Delta Lake em conjunto com o Deep Clone para replicar dados; isso fornece uma maneira fácil e de código aberto para fazer backup eficiente de dados.
- Use as ferramentas nativas da nuvem fornecidas pelo seu provedor de nuvem para fazer backup de coisas como dados não armazenados no Delta Lake, bancos de dados externos, configurações, etc.
- Use ferramentas como Terraform para fazer backup de objetos como notebooks, jobs, secrets, clusters e outros objetos do workspace.
Lembre-se: o Databricks é responsável por manter a infraestrutura regional do workspace no Control Plane, mas você é responsável pelos seus ativos específicos do workspace, bem como pela infraestrutura de nuvem da qual seus jobs de produção dependem.
Isolamento por linha de negócio (LOB)
Agora mergulhamos na organização real dos workspaces em um contexto empresarial. O isolamento de projetos baseado em LOB surge da forma tradicional de olhar para os recursos de TI com foco empresarial – ele também carrega muitas forças (e fraquezas) tradicionais do alinhamento centrado em LOB. Como tal, para muitas grandes empresas, essa abordagem de gerenciamento de workspace virá naturalmente.
Em uma estratégia de workspace baseada em LOB, cada unidade funcional de um negócio receberá um conjunto de workspaces; tradicionalmente, isso incluirá workspaces de desenvolvimento, staging e produção, embora tenhamos visto clientes com até 10 estágios intermediários, cada um com seu próprio workspace (não recomendado)! O código é escrito e testado em DEV, depois promovido (via automação CI/CD) para STG e, finalmente, chega a PRD, onde é executado como um job agendado até ser descontinuado. O tipo de ambiente e a LOB independente são as principais razões para iniciar um novo workspace neste modelo; fazer isso para cada caso de uso ou produto de dados pode ser excessivo.
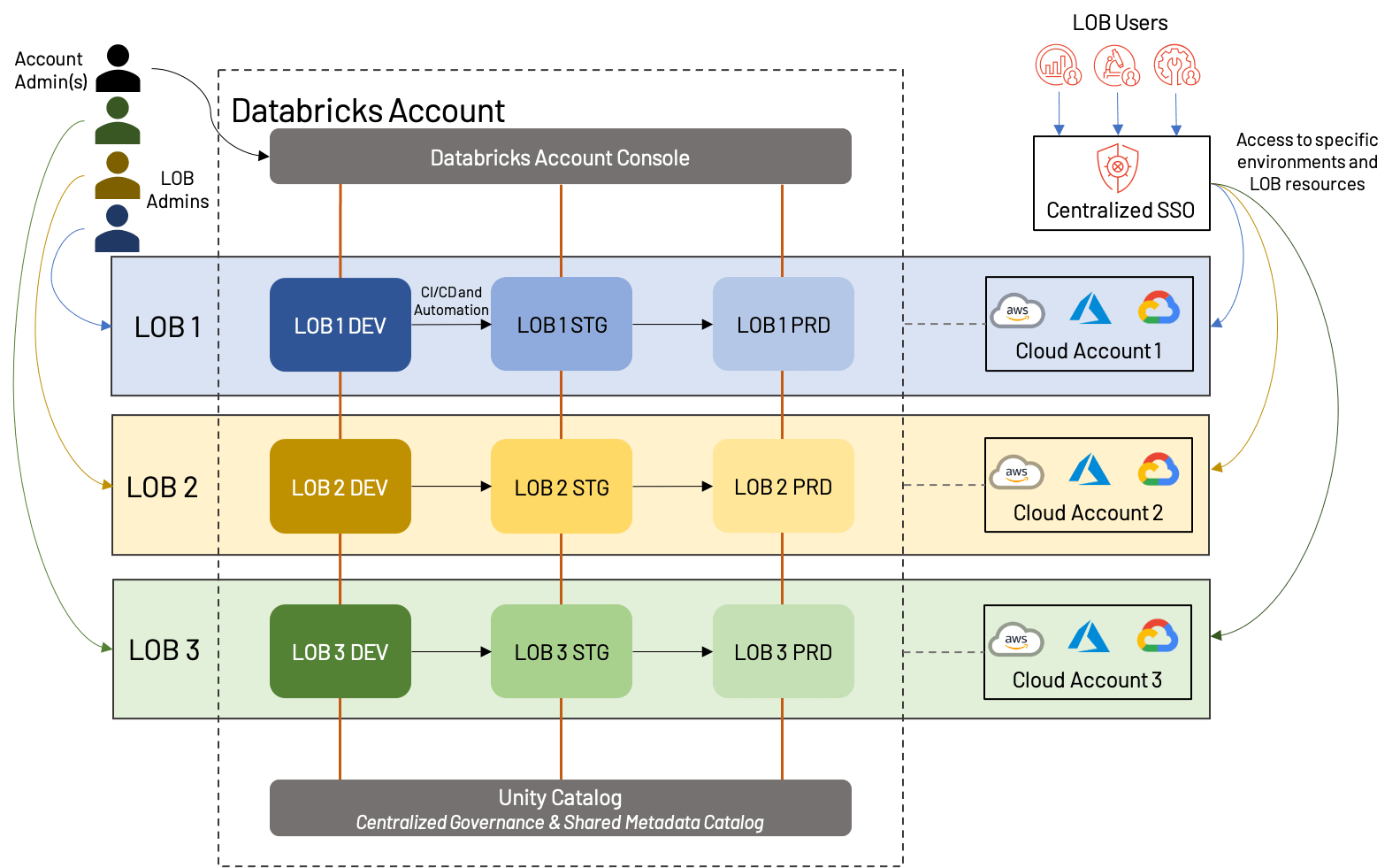
O diagrama acima mostra uma maneira potencial de como o workspace baseado em LOB pode ser estruturado; neste caso, cada LOB tem uma conta de nuvem separada com um workspace em cada ambiente (dev/stg/prd) e também tem um administrador dedicado. Importante, todos esses workspaces estão sob a mesma conta Databricks e utilizam o mesmo Unity Catalog. Algumas variações incluiriam o compartilhamento de contas de nuvem (e potencialmente recursos subjacentes como VPCs e serviços de nuvem), o uso de uma conta de nuvem dev/stg/prd separada ou a criação de metastores externos separados para cada LOB. Todas essas são abordagens razoáveis que dependem muito das necessidades do negócio.
No geral, há uma série de benefícios, bem como algumas desvantagens para a abordagem LOB:
+Os ativos de cada LOB podem ser isolados, tanto da perspectiva da nuvem quanto da perspectiva do workspace; isso facilita relatórios/análise de custos simples, além de um workspace menos confuso.
+A divisão clara de usuários e funções melhora a governança geral do Lakehouse e reduz o risco geral.
+A automação da promoção entre ambientes cria um processo eficiente e de baixa sobrecarga.
-O planejamento antecipado é necessário para garantir que os processos entre LOBs sejam padronizados e que a conta Databricks geral não atinja os limites da plataforma.
-A automação e os processos administrativos exigem especialistas para configuração e manutenção.
Como melhores práticas, recomendamos o seguinte para quem está construindo Lakehouses baseados em LOB:
- Empregue um modelo de acesso de privilégio mínimo usando controle de acesso granular para usuários e ambientes; em geral, poucos usuários devem ter acesso de produção, e as interações com este ambiente devem ser automatizadas e altamente controladas. Capture esses usuários e grupos em seu provedor de identidade e sincronize-os com o Lakehouse.
- Entenda e planeje os limites do provedor de nuvem e da plataforma Databricks; estes incluem, por exemplo, o número de workspaces, limitação de taxa de API no ADLS, throttling em streams Kinesis, etc.
- Use um metastore/catálogo padronizado com fortes controles de acesso sempre que possível; isso permite a reutilização de ativos sem comprometer o isolamento. O Unity Catalog permite controles granulares sobre tabelas e ativos do workspace, que incluem objetos como experimentos do MLflow.
- Aproveite o compartilhamento de dados sempre que possível para compartilhar dados com segurança entre LOBs sem a necessidade de duplicar esforços.
Isolamento de produto de dados
O que fazemos quando os LOBs precisam colaborar interfuncionalmente, ou quando um modelo simples de dev/stg/prd não se encaixa nos casos de uso do nosso LOB? Podemos abandonar parte da formalidade de uma estrutura estrita de Lakehouse baseada em LOB e abraçar uma abordagem um pouco mais moderna; chamamos isso de isolamento de workspace por Produto de Dados. O conceito é que, em vez de isolar estritamente por LOB, isolamos por projetos de nível superior, dando a cada um um ambiente de produção. Também misturamos ambientes de desenvolvimento compartilhados para evitar a proliferação de workspaces e tornar a reutilização de ativos mais simples.
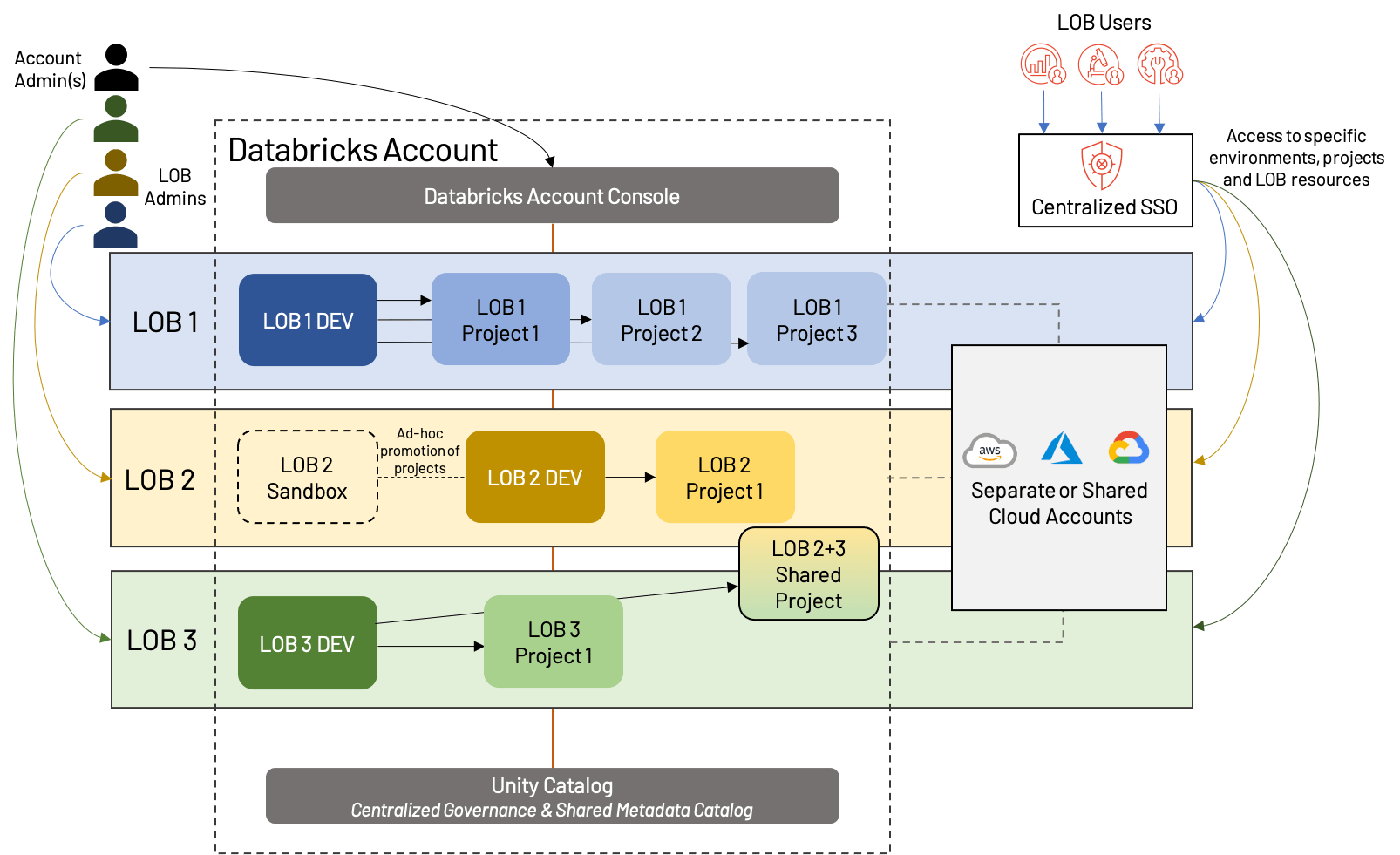
À primeira vista, isso parece semelhante ao isolamento baseado em LOB acima, mas há algumas distinções importantes:
- Um workspace de desenvolvimento compartilhado, com workspaces separados para cada projeto de nível superior (o que significa que cada LOB pode ter um número diferente de workspaces no total)
- A presença de workspaces sandbox, que são específicos de um LOB e oferecem mais liberdade e menos automação do que os workspaces de desenvolvimento tradicionais
- Compartilhamento de recursos e/ou workspaces; isso também é possível em arquiteturas baseadas em LOB, mas muitas vezes é complicado por uma separação mais rígida
Essa abordagem compartilha muitos dos mesmos pontos fortes e fracos do isolamento baseado em LOB, mas oferece mais flexibilidade e enfatiza o valor dos projetos no Lakehouse moderno. Cada vez mais, vemos isso se tornando o “padrão ouro” de organização de workspaces, correspondendo ao movimento da tecnologia de ser primariamente um impulsionador de custos para um gerador de valor. Como sempre, as necessidades de negócios podem levar a pequenos desvios desta arquitetura de exemplo, como dev/stg/prd dedicados para projetos particularmente grandes, projetos inter-LOBs, mais ou menos segregação de recursos de nuvem, etc. Independentemente da estrutura exata, sugerimos as seguintes melhores práticas:
- Compartilhe dados e recursos sempre que poss�ível; embora a segregação de infraestrutura e workspaces seja útil para governança e rastreamento, a proliferação de recursos rapidamente se torna um fardo. Uma análise cuidadosa antecipada ajudará a identificar áreas de reutilização.
- Mesmo quando não estiver compartilhando extensivamente entre projetos, use um metastore compartilhado como o Unity Catalog e bases de código compartilhadas (via, por exemplo, Repos) sempre que possível.
- Use Terraform (ou ferramentas semelhantes) para automatizar o processo de criação, gerenciamento e exclusão de workspaces e infraestrutura de nuvem.
- Ofereça flexibilidade aos usuários por meio de ambientes sandbox, mas garanta que eles tenham os devidos mecanismos de proteção configurados para limitar tamanhos de cluster, acesso a dados, etc.
Resumo
Para aproveitar totalmente todos os benefícios do Lakehouse e apoiar o crescimento e a gerenciabilidade futuros, deve-se ter o cuidado de planejar o layout do workspace. Outros artefatos associados que precisam ser considerados durante este projeto incluem um registro de modelo centralizado, base de código e catálogo para auxiliar na colaboração sem comprometer a segurança. Para resumir algumas das melhores práticas destacadas neste artigo, nossas principais conclusões estão listadas abaixo:
Melhor Prática #1: Minimize o número de contas de nível superior (tanto no nível do provedor de nuvem quanto no Databricks), sempre que possível, e crie um workspace apenas quando a separação for necessária por motivos de conformidade, isolamento ou restrições geográficas. Na dúvida, mantenha a simplicidade!
Melhor Prática #2: Decida sobre uma estratégia de isolamento que lhe proporcionará flexibilidade de longo prazo sem complexidade indevida. Seja realista sobre suas necessidades e implemente diretrizes rigorosas antes de começar a migrar cargas de trabalho para seu Lakehouse; em outras palavras, meça duas vezes, corte uma vez!
Melhor Prática #3: Automatize seus processos de nuvem. Isso abrange todos os aspectos de sua infraestrutura (muitos dos quais serão abordados em blogs futuros!), incluindo SSO/SCIM, Infraestrutura como Código com uma ferramenta como Terraform, pipelines de CI/CD e Repos, backup na nuvem e monitoramento (usando ferramentas nativas da nuvem e de terceiros).
Melhor Prática #4: Considere estabelecer uma equipe de COE (Centro de Excelência) para governança central de uma estratégia corporativa, onde aspectos repetíveis de um pipeline de dados e machine learning são templatizados e automatizados para que diferentes equipes de dados possam usar recursos de autoatendimento com salvaguardas suficientes. A equipe de COE é frequentemente um hub leve, mas crítico, para equipes de dados e deve se ver como um facilitador, mantendo documentação, SOPs, guias e FAQs para educar outros usuários.
Melhor Prática #5: O Lakehouse fornece um nível de governança que o Data Lake não oferece; aproveite! Avalie suas necessidades de conformidade e governança como uma das primeiras etapas para estabelecer seu Lakehouse e utilize os recursos que o Databricks oferece para garantir que o risco seja minimizado. Isso inclui entrega de logs de auditoria, HIPAA e PCI (quando aplicável), controles adequados de exfiltração, uso de ACLs e controles de usuário, e revisão regular de todos os itens acima.
Forneceremos mais blogs de melhores práticas de administração em breve, sobre tópicos de Governança de Dados a Gerenciamento de Usuários. Enquanto isso, entre em contato com sua equipe de conta Databricks com perguntas sobre gerenciamento de workspace, ou se desejar saber mais sobre as melhores práticas na Databricks Lakehouse Platform!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.