Avaliação de Modelos no MLflow
por Mark Zhang
Muitos cientistas de dados e engenheiros de ML usam o MLflow hoje para gerenciar seus modelos. O MLflow é uma plataforma open-source que permite aos usuários governar todos os aspectos do ciclo de vida de ML, incluindo, mas não se limitando a, experimentação, reprodutibilidade, implantação e registro de modelos. Uma etapa crítica durante o desenvolvimento de modelos de ML é a avaliação de seu desempenho em novos conjuntos de dados.
Motivação
Por que avaliamos modelos?
A avaliação de modelos é parte integrante do ciclo de vida de ML. Ela permite que os cientistas de dados meçam, interpretem e expliquem o desempenho de seus modelos. Acelera o tempo de desenvolvimento do modelo, fornecendo insights sobre como e por que os modelos estão performando da maneira que estão. Especialmente com o aumento da complexidade dos modelos de ML, ser capaz de observar e entender rapidamente o desempenho dos modelos de ML é essencial em uma jornada de desenvolvimento de ML bem-sucedida.
Estado da Avaliação de Modelos no MLflow
Atualmente, muitos usuários avaliam o desempenho do seu modelo MLflow do flavor de modelo python_function (pyfunc) através da API mlflow.evaluate, que suporta a avaliação de modelos de classificação e regressão. Ela calcula e registra um conjunto de métricas de desempenho específicas da tarefa, gráficos de desempenho do modelo e explicações do modelo no servidor de MLflow Tracking.
Para avaliar modelos MLflow contra métricas personalizadas não incluídas no conjunto de métricas de avaliação integradas, os usuários teriam que definir um plugin de avaliador de modelo personalizado. Isso envolveria a criação de uma classe avaliadora personalizada que implementa a interface ModelEvaluator, e então registrar um ponto de entrada do avaliador como parte de um plugin MLflow. Essa rigidez e complexidade podem ser proibitivas para os usuários.
De acordo com uma pesquisa interna com clientes, 75% dos entrevistados dizem que usam frequentemente ou sempre métricas especializadas e focadas em negócios, além das básicas como acurácia e perda. Cientistas de dados frequentemente utilizam essas métricas personalizadas, pois elas são mais descritivas dos objetivos de negócios (por exemplo, taxa de conversão) e contêm heurísticas adicionais não capturadas pela própria previsão do modelo.
Neste blog, apresentamos uma maneira fácil e conveniente de avaliar modelos MLflow em métricas personalizadas definidas pelo usuário. Com essa funcionalidade, um cientista de dados pode facilmente incorporar essa lógica na etapa de avaliação do modelo e determinar rapidamente o modelo com melhor desempenho sem análises downstream adicionais.
*Nota: Em MLflow 2.4, o mlflow.evaluate foi expandido para suportar modelos de LLM de texto, sumarização de texto e perguntas e respostas
Uso
Métricas Integradas
O MLflow inclui um conjunto de métricas de desempenho e explicabilidade de modelo comumente usadas para modelos de classificador e regressor. Avaliar modelos nessas métricas é simples. Tudo o que precisamos é criar um conjunto de dados de avaliação contendo os dados de teste e os alvos e fazer uma chamada para mlflow.evaluate.
Dependendo do tipo de modelo, diferentes métricas são calculadas. Consulte a seção Comportamento do Avaliador Padrão na documentação da API de mlflow.evaluate para obter as informações mais atualizadas sobre métricas integradas.
Exemplo
Abaixo está um exemplo simples de como um modelo MLflow classificador é avaliado com métricas integradas.
Primeiro, importe as bibliotecas necessárias
Em seguida, dividimos o conjunto de dados, ajustamos o modelo e criamos nosso conjunto de dados de avaliação
Finalmente, iniciamos uma execução do MLflow e chamamos mlflow.evaluate
Podemos encontrar as métricas e artefatos registrados na UI do MLflow:
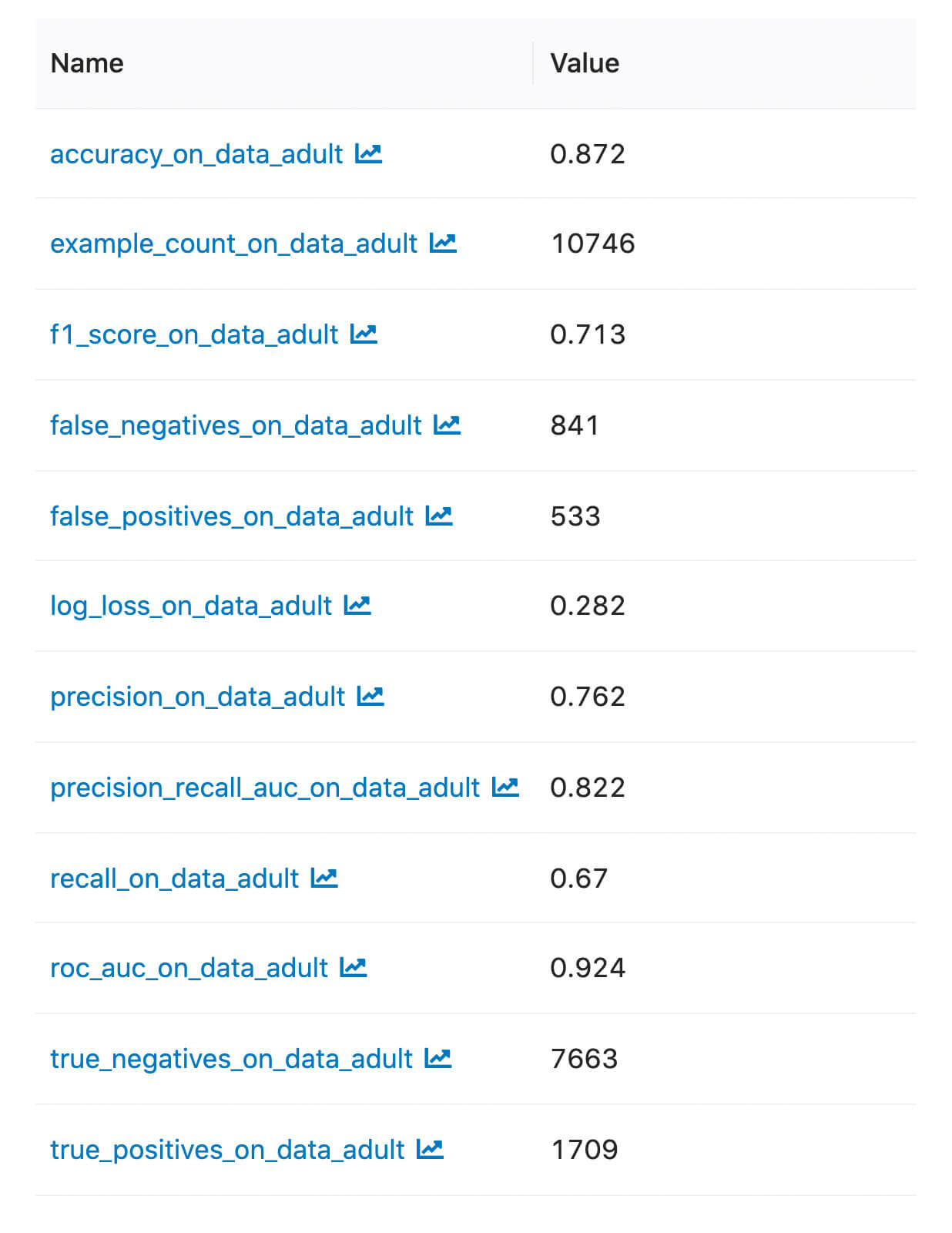
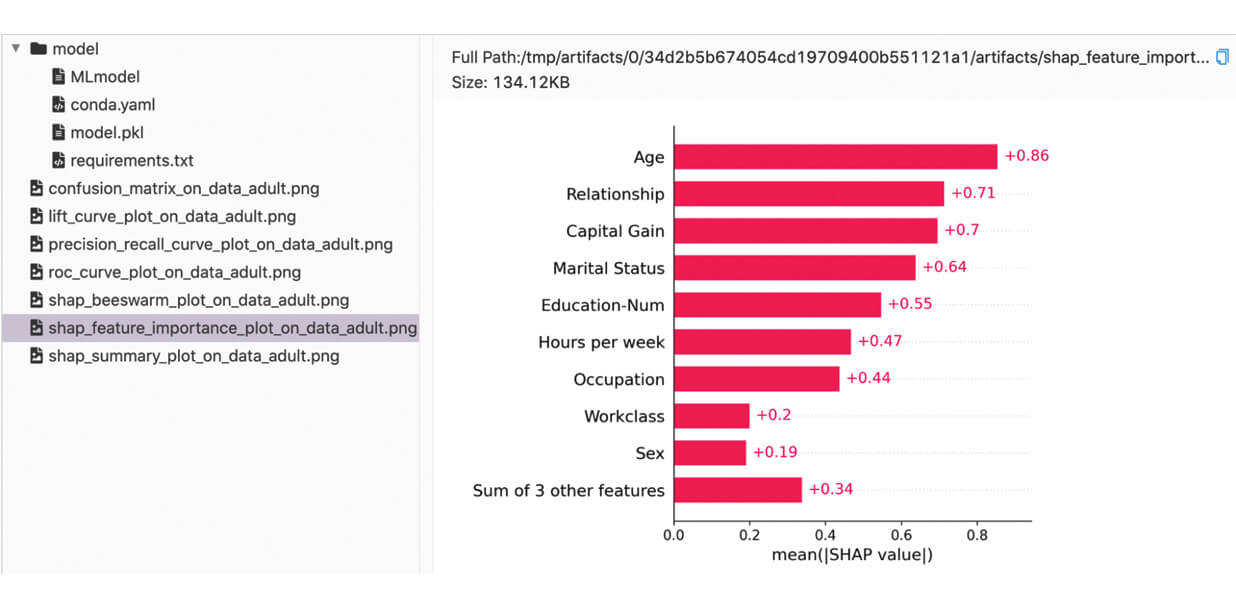
Métricas Personalizadas
Para avaliar um modelo contra métricas personalizadas, simplesmente passamos uma lista de funções de métricas personalizadas para a API mlflow.evaluate.
Requisitos de Definição de Função
As funções de métricas personalizadas devem aceitar dois parâmetros obrigatórios e um opcional na seguinte ordem:
eval_df: um DataFrame Pandas ou Spark contendo uma coluna depredictione uma coluna detarget.Exemplo: Se a saída do modelo for um vetor de três números, o DataFrame
eval_dfse pareceria com algo assim: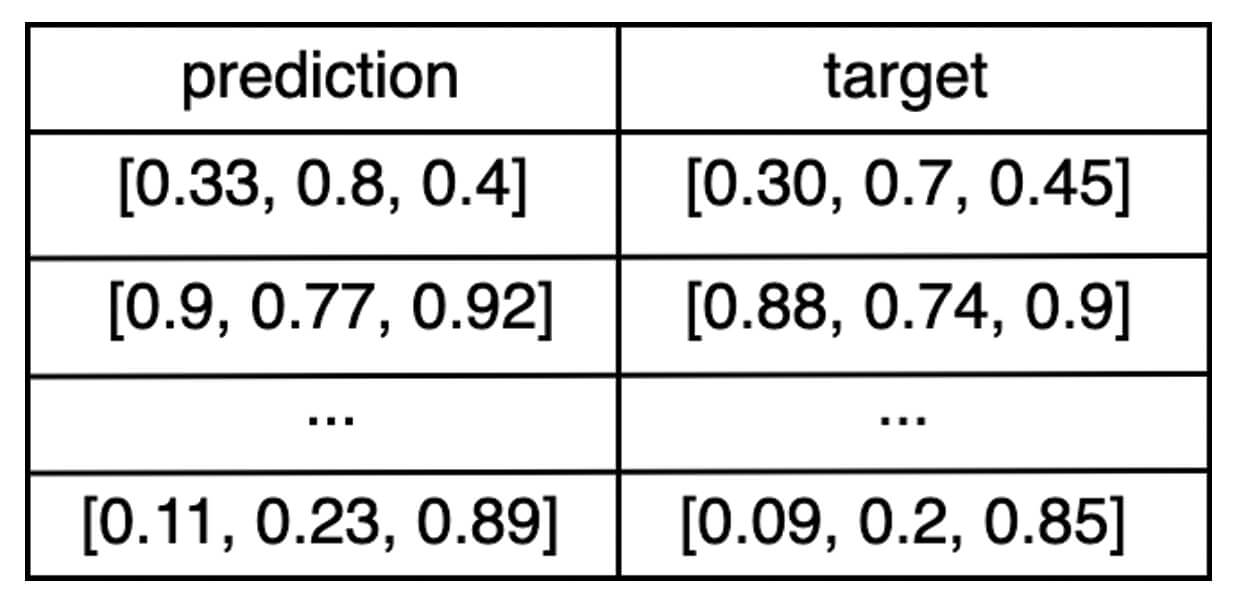
builtin_metrics: um dicionário contendo as métricas integradasExemplo: Para um modelo regressor,
builtin_metricsse pareceria com algo assim:- (Opcional)
artifacts_dir: caminho para um diretório temporário que pode ser usado pela função de métrica personalizada para armazenar temporariamente artefatos produzidos antes de registrar no MLflow.Exemplo: Observe que isso parecerá diferente dependendo da configuração específica do ambiente. Por exemplo, no MacOS, pode parecer algo assim:
Se os artefatos de arquivo forem armazenados em outro local que não
artifacts_dir, certifique-se de que eles persistam até após a execução completa demlflow.evaluate.
Requisitos de Valor de Retorno
A função deve retornar um dicionário representando as métricas produzidas e pode opcionalmente retornar um segundo dicionário representando os artefatos produzidos. Para ambos os dicionários, a chave para cada entrada representa o nome da métrica ou artefato correspondente.
Enquanto cada métrica deve ser um escalar, existem várias maneiras de definir artefatos:
- O caminho para um arquivo de artefato
- A representação em string de um objeto JSON
- Um DataFrame pandas
- Um array numpy
- Uma figura matplotlib
- Outros objetos serão tentados a serem serializados com o protocolo padrão
Consulte a documentação de mlflow.evaluate para obter detalhes mais aprofundados sobre a definição.
Exemplo
Vamos analisar um exemplo concreto que usa métricas personalizadas. Para isso, criaremos um modelo de teste do conjunto de dados California Housing.
Em seguida, configuraremos nosso conjunto de dados e modelo
Aqui vem a parte interessante: definindo nossa função de métricas personalizadas, e um artefato personalizado!!
Finalmente, para juntar tudo isso, iniciaremos uma execução do MLflow e chamaremos mlflow.evaluate:
As métricas e artefatos personalizados registrados podem ser encontrados ao lado das métricas e artefatos padrão. As regiões em caixa vermelha mostram as métricas e artefatos personalizados registrados na página de execução.
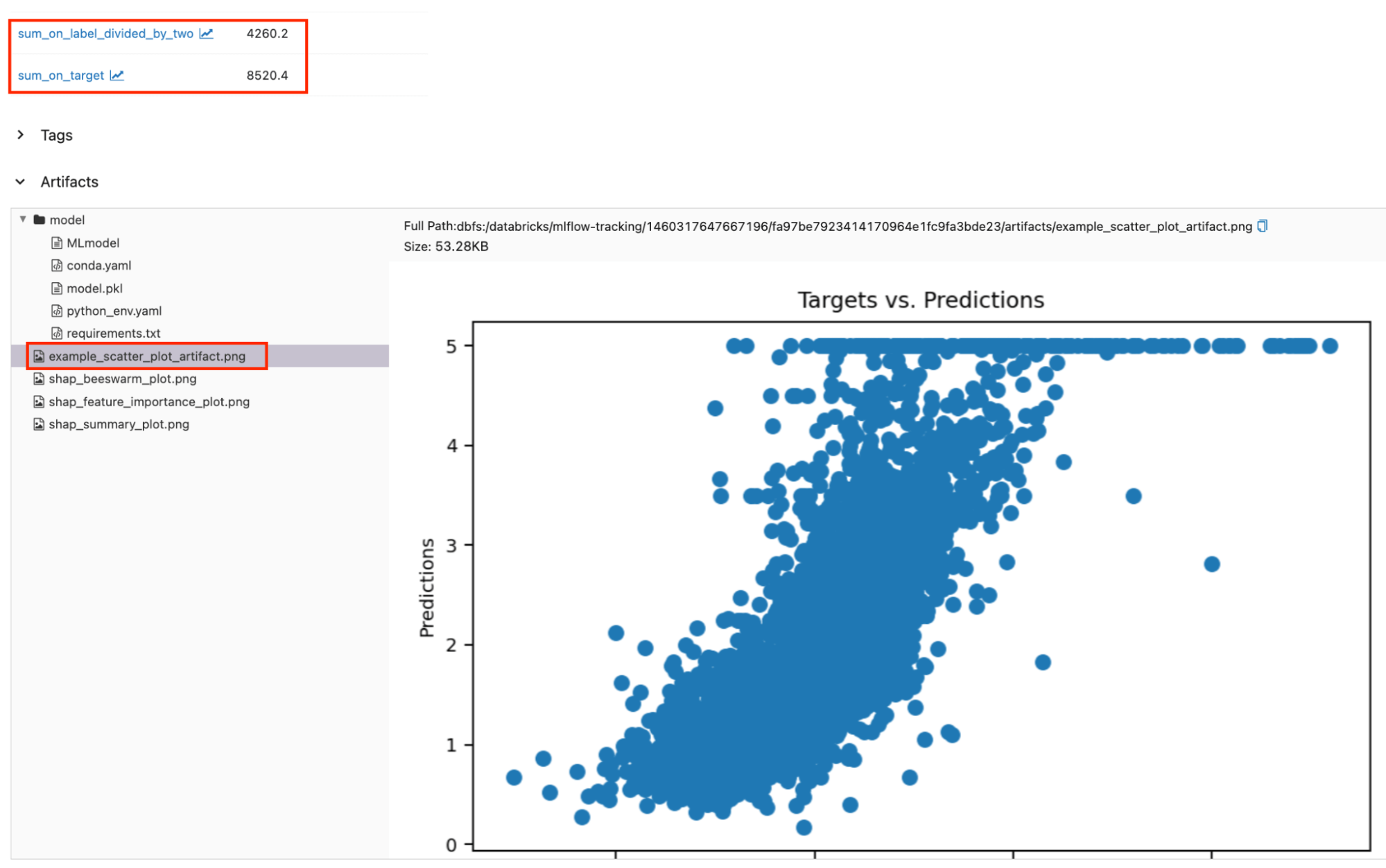
Acessando Resultados de Avaliação Programaticamente
Até agora, exploramos os resultados de avaliação para métricas internas e personalizadas na interface do MLflow. No entanto, também podemos acessá-los programaticamente através do objeto EvaluationResult retornado por mlflow.evaluate. Vamos continuar nosso exemplo de métricas personalizadas acima e ver como podemos acessar seus resultados de avaliação programaticamente. (Assumindo que result é nossa instância de EvaluationResult a partir daqui).
Podemos acessar o conjunto de métricas computadas através do dicionário result.metrics, que contém o nome e os valores escalares das métricas. O conteúdo de result.metrics deve se parecer com isto:
Da mesma forma, o conjunto de artefatos é acessível através do dicionário result.artifacts. Os valores de cada entrada são um objeto EvaluationArtifact. result.artifacts deve se parecer com isto:
Notebooks de Exemplo
Por Dentro
O diagrama abaixo ilustra como tudo isso funciona internamente:
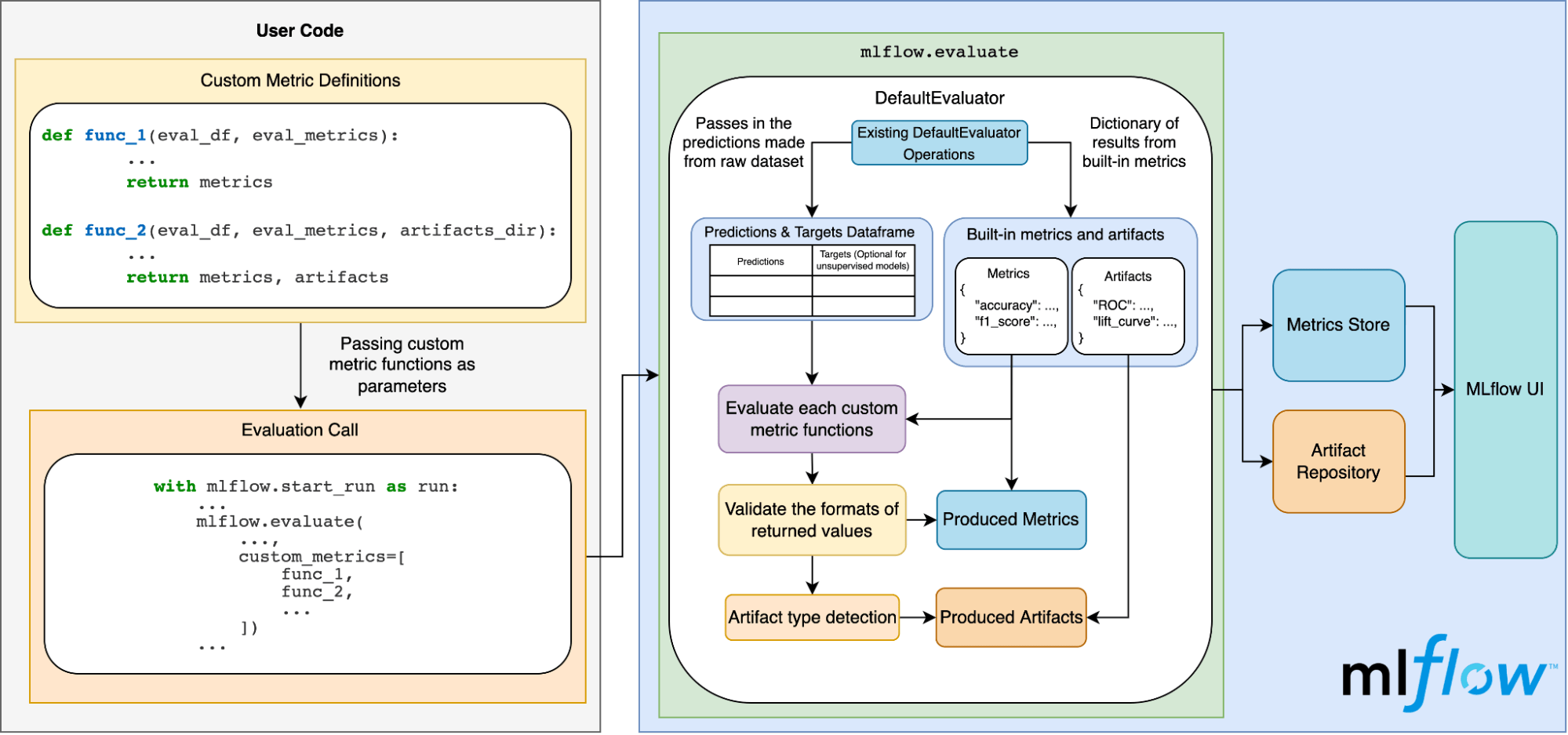
Conclusão
Neste post, abordamos:
- A importância da avaliação de modelos e o que está atualmente suportado no MLflow.
- Por que ter uma maneira fácil para os usuários do MLflow incorporarem métricas personalizadas em seus modelos MLflow é importante.
- Como avaliar modelos com métricas padrão.
- Como avaliar modelos com métricas personalizadas.
- Como o MLflow lida com a avaliação de modelos nos bastidores.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.