Simplificando a Captura de Dados de Alteração com Databricks Delta Live Tables
por Mojgan Mazouchi
Este guia demonstrará como você pode aproveitar a Captura de Dados de Alteração (Change Data Capture - CDC) em pipelines do Delta Live Tables para identificar novos registros e capturar alterações feitas no conjunto de dados no seu data lake. Os pipelines do Delta Live Tables permitem que você desenvolva pipelines de dados escaláveis, confiáveis e de baixa latência, enquanto realiza a Captura de Dados de Alteração no seu data lake com recursos computacionais mínimos necessários e tratamento de dados fora de ordem sem interrupções.
Contexto sobre Captura de Dados de Alteração
A Captura de Dados de Alteração (Change Data Capture - CDC) é um processo que identifica e captura alterações incrementais (exclusões, inserções e atualizações de dados) em bancos de dados, como rastrear o status de clientes, pedidos ou produtos para aplicações de dados em tempo quase real. A CDC fornece evolução de dados em tempo real processando dados de forma incremental contínua à medida que novos eventos ocorrem.
Como mais de 80% das organizações planejam implementar estratégias multinuvem até 2025, escolher a abordagem certa para o seu negócio que permita a centralização em tempo real e sem interrupções de todas as alterações de dados no seu pipeline de ETL em múltiplos ambientes é crucial.
Ao capturar eventos de CDC, os usuários do Databricks podem rematerializar a tabela de origem como uma Delta Table no Lakehouse e executar suas análises sobre ela, enquanto conseguem combinar dados com sistemas externos. O comando MERGE INTO no Delta Lake no Databricks permite que os clientes insiram e excluam registros de forma eficiente em seus data lakes – você pode conferir nossa análise aprofundada anterior sobre o tópico aqui. Este é um caso de uso comum que observamos muitos clientes Databricks aproveitando o Delta Lake para realizar, e mantendo seus data lakes atualizados com dados de negócios em tempo real.
Embora o Delta Lake forneça uma solução completa para sincronização de CDC em tempo real em um data lake, agora estamos animados em anunciar o recurso de Captura de Dados de Alteração no Delta Live Tables que torna sua arquitetura ainda mais simples, eficiente e escalável. O DLT permite que os usuários ingiram dados de CDC de forma transparente usando SQL e Python.
Soluções anteriores de CDC com tabelas Delta usavam a operação MERGE INTO, que requer a ordenação manual dos dados para evitar falhas quando várias linhas do conjunto de dados de origem correspondem ao tentar atualizar as mesmas linhas da tabela Delta de destino. Para lidar com dados fora de ordem, era necessária uma etapa extra para pré-processar a tabela de origem usando uma implementação foreachBatch para eliminar a possibilidade de múltiplas correspondências, retendo apenas a alteração mais recente para cada chave (Veja o exemplo de captura de dados de alteração). A nova operação APPLY CHANGES INTO em pipelines DLT lida automática e transparentemente com dados fora de ordem, sem necessidade de intervenção manual de engenharia de dados.
CDC com Databricks Delta Live Tables
Neste blog, demonstraremos como usar o comando APPLY CHANGES INTO em pipelines do Delta Live Tables para um caso de uso comum de CDC onde os dados de CDC vêm de um sistema externo. Uma variedade de ferramentas de CDC está disponível, como Debezium, Fivetran, Qlik Replicate, Talend e StreamSets. Embora as implementações específicas difiram, essas ferramentas geralmente capturam e registram o histórico de alterações de dados em logs; aplicações downstream consomem esses logs de CDC. Em nosso exemplo, os dados são carregados no armazenamento de objetos na nuvem a partir de uma ferramenta de CDC como Debezium, Fivetran, etc.
Temos dados de várias ferramentas de CDC chegando a um armazenamento de objetos na nuvem ou a uma fila de mensagens como Apache Kafka. Normalmente, vemos CDC sendo usado em uma ingestão para o que chamamos de arquitetura Medallion. Uma arquitetura Medallion é um padrão de design de dados usado para organizar logicamente os dados em um Lakehouse, com o objetivo de melhorar incremental e progressivamente a estrutura e a qualidade dos dados à medida que eles fluem por cada camada da arquitetura. O Delta Live Tables permite que você aplique alterações de feeds de CDC de forma transparente às tabelas em seu Lakehouse; combinar essa funcionalidade com a arquitetura Medallion permite que as alterações incrementais fluam facilmente através de cargas de trabalho analíticas em escala. Usar CDC em conjunto com a arquitetura Medallion oferece múltiplos benefícios aos usuários, pois apenas os dados alterados ou adicionados precisam ser processados. Assim, permite que os usuários mantenham de forma econômica as tabelas gold atualizadas com os dados de negócios mais recentes.
OBSERVAÇÃO: O exemplo aqui se aplica às versões SQL e Python de CDC e também a uma maneira específica de usar as operações. Para avaliar variações, consulte a documentação oficial aqui.
Pré-requisitos
Para aproveitar ao máximo este guia, você deve ter familiaridade básica com:
- SQL ou Python
- Delta Live Tables
- Desenvolvimento de pipelines ETL e/ou trabalho com sistemas de Big Data
- Notebooks interativos e clusters Databricks
- Você deve ter acesso a um Workspace Databricks com permissões para criar novos clusters, executar jobs e salvar dados em um local no armazenamento de objetos externo na nuvem ou no DBFS.
- Para o pipeline que estamos criando neste blog, a edição do produto "Advanced", que suporta a aplicação de restrições de qualidade de dados, precisa ser selecionada.
O Conjunto de Dados
Aqui estamos consumindo dados de CDC com aparência realista de um banco de dados externo. Neste pipeline, usaremos a biblioteca Faker para gerar o conjunto de dados que uma ferramenta de CDC como Debezium pode produzir e trazer para o armazenamento na nuvem para a ingestão inicial no Databricks. Usando o Auto Loader, carregamos incrementalmente as mensagens do armazenamento de objetos na nuvem e as armazenamos na tabela Bronze, pois ela armazena as mensagens brutas. As tabelas Bronze são destinadas à ingestão de dados, permitindo acesso rápido a uma única fonte da verdade. Em seguida, realizamos APPLY CHANGES INTO da tabela Bronze limpa para propagar as atualizações downstream para a Tabela Silver. À medida que os dados fluem para as tabelas Silver, geralmente eles se tornam mais refinados e otimizados ("just-enough") para fornecer a uma empresa uma visão de todas as suas principais entidades de negócios. Veja o diagrama abaixo.
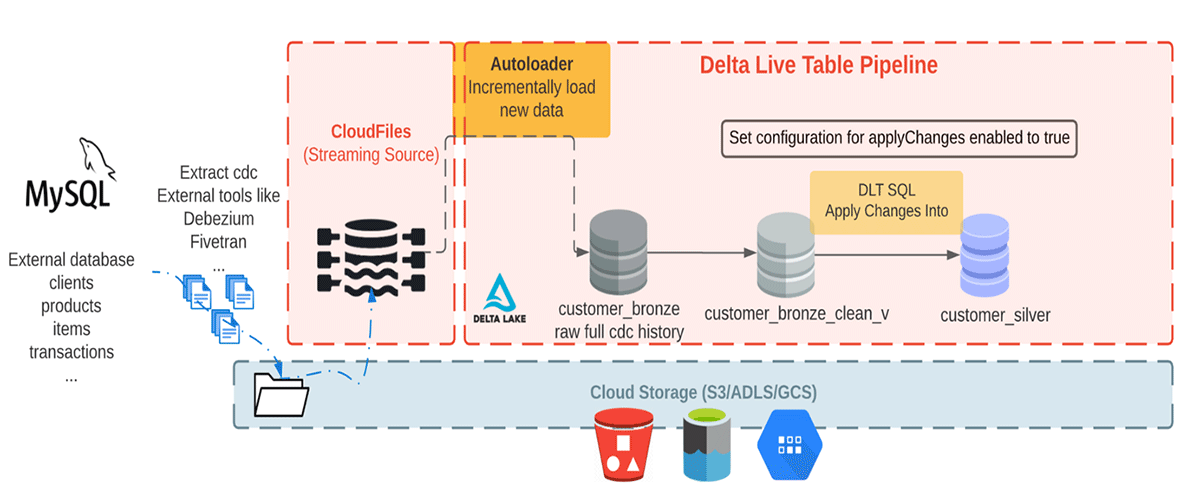
Este blog foca em um exemplo simples que requer uma mensagem JSON com quatro campos: nome do cliente, e-mail, endereço e id, juntamente com dois campos: operation (que armazena o código da operação (DELETE, APPEND, UPDATE, CREATE) e operation_date (que armazena a data e hora em que o registro chegou para cada ação de operação) para descrever os dados alterados.
Para gerar um conjunto de dados de exemplo com os campos acima, estamos usando um pacote Python que gera dados falsos, o Faker. Você pode encontrar o notebook relacionado a esta seção de geração de dados aqui. Neste notebook, fornecemos o nome e o local de armazenamento para escrever os dados gerados lá. Estamos usando a funcionalidade DBFS do Databricks, veja a documentação do DBFS para saber mais sobre como funciona. Em seguida, usamos uma User-Defined-Function (UDF) PySpark para gerar o conjunto de dados sintético para cada campo e escrevemos os dados de volta no local de armazenamento definido, que usaremos em outros notebooks para acessar o conjunto de dados sintético.
Ingestão do conjunto de dados bruto usando Auto Loader
De acordo com o paradigma da arquitetura Medallion, a camada bronze contém a qualidade de dados mais bruta. Neste estágio, podemos ler incrementalmente novos dados usando o Autoloader de um local no armazenamento em nuvem. Aqui estamos adicionando o caminho para nosso conjunto de dados gerado à seção de configuração nas configurações do pipeline, o que nos permite carregar o caminho de origem como uma variável. Assim, nossa configuração nas configurações do pipeline agora se parece com isto:
Em seguida, carregamos essa propriedade de configuração em nossos notebooks.
Vamos dar uma olhada na tabela Bronze que vamos ingerir: a. Em SQL e b. Usando Python
a. SQL
b. Python
As declarações acima usam o Auto Loader para criar uma tabela Streaming Live chamada customer_bronze a partir de arquivos JSON. Ao usar o Autoloader no Delta Live Tables, você não precisa fornecer um local para o esquema ou checkpoint, pois esses locais serão gerenciados automaticamente pelo seu pipeline DLT.
O Auto Loader fornece uma fonte Structured Streaming chamada cloud_files em SQL e cloudFiles em Python, que aceita um caminho de armazenamento em nuvem e formato como parâmetros.
Para reduzir custos de computação, recomendamos executar o pipeline DLT no modo Triggered como um micro-batch, assumindo que você não tem requisitos de latência muito baixos.
Expectations and high-quality data
Na próxima etapa para criar um conjunto de dados de alta qualidade, diversificado e acessível, impomos critérios de expectativa de verificação de qualidade usando Constraints. Atualmente, uma constraint pode ser reter, descartar ou falhar. Para mais detalhes, veja aqui. Todas as constraints são registradas para permitir o monitoramento simplificado da qualidade.
a. SQL
b. Python
Using APPLY CHANGES INTO statement to propagate changes to downstream target table
Antes de executar a consulta Apply Changes Into, devemos garantir que uma tabela de destino de streaming que conterá os dados mais atualizados exista. Se ela não existir, precisamos criá-la. As células abaixo são exemplos de criação de uma tabela de destino de streaming. Observe que, no momento da publicação deste blog, a instrução de criação da tabela de destino de streaming é necessária junto com a consulta Apply Changes Into, e ambas precisam estar presentes no pipeline, caso contrário, sua consulta de criação de tabela falhará.
a. SQL
b. Python
Agora que temos uma tabela de destino de streaming, podemos propagar as alterações para a tabela de destino downstream usando a consulta Apply Changes Into. Enquanto o feed CDC vem com eventos INSERT, UPDATE e DELETE, o comportamento padrão do DLT é aplicar eventos INSERT e UPDATE de qualquer registro no conjunto de dados de origem correspondente às chaves primárias, e sequenciado por um campo que identifica a ordem dos eventos. Mais especificamente, ele atualiza qualquer linha na tabela de destino existente que corresponda à(s) chave(s) primária(s) ou insere uma nova linha quando um registro correspondente não existe na tabela de destino de streaming. Podemos usar APPLY AS DELETE WHEN em SQL, ou seu equivalente apply_as_deletes em Python para lidar com eventos DELETE.
Neste exemplo, usamos "id" como minha chave primária, que identifica exclusivamente os clientes e permite que os eventos CDC sejam aplicados aos registros de clientes identificados na tabela de destino de streaming. Como "operation_date" mantém a ordem lógica dos eventos CDC no conjunto de dados de origem, usamos "SEQUENCE BY operation_date" em SQL, ou seu equivalente "sequence_by = col("operation_date")" em Python para lidar com eventos de alteração que chegam fora de ordem. Lembre-se de que o valor do campo que usamos com SEQUENCE BY (ou sequence_by) deve ser exclusivo entre todas as atualizações para a mesma chave. Na maioria dos casos, a coluna sequence by será uma coluna com informações de timestamp.
Finalmente, usamos "COLUMNS * EXCEPT (operation, operation_date, _rescued_data)" em SQL, ou seu equivalente "except_column_list"= ["operation", "operation_date", "_rescued_data"] em Python para excluir três colunas de "operation", "operation_date", "_rescued_data" da tabela de destino de streaming. Por padrão, todas as colunas são incluídas na tabela de destino de streaming, quando não especificamos a cláusula "COLUMNS".
a. SQL
b. Python
Para conferir a lista completa de cláusulas disponíveis, veja aqui.
Por favor, note que, no momento da publicação deste blog, uma tabela que lê do destino de uma consulta APPLY CHANGES INTO ou função apply_changes deve ser uma tabela live e não pode ser uma tabela streaming live.
Um notebook SQL e Python está disponível como referência para esta seção. Agora que temos todas as células prontas, vamos criar um Pipeline para ingerir dados do armazenamento de objetos na nuvem. Abra Jobs em uma nova aba ou janela no seu workspace e selecione "Delta Live Tables".
O pipeline associado a este blog tem as seguintes configurações de pipeline DLT:
- Selecione "Create Pipeline" para criar um novo pipeline
- Especifique um nome como "Retail CDC Pipeline"
- Especifique os Caminhos dos Notebooks que você já criou anteriormente, um para o conjunto de dados gerado usando o pacote Faker e outro caminho para a ingestão dos dados gerados em DLT. O segundo caminho do notebook pode se referir ao notebook escrito em SQL ou Python, dependendo da sua escolha de linguagem.
- Para acessar os dados gerados no primeiro notebook, adicione o caminho do conjunto de dados na configuração. Aqui, armazenamos os dados em "/tmp/demo/cdc_raw/customers", então definimos "source" como "/tmp/demo/cdc_raw/" para referenciar "source/customers" em nosso segundo notebook.
- Especifique o Destino (que é opcional e se refere ao banco de dados de destino), onde você pode consultar as tabelas resultantes do seu pipeline.
- Especifique o Local de Armazenamento em seu armazenamento de objetos (que é opcional), para acessar seus conjuntos de dados produzidos pelo DLT e logs de metadados para seu pipeline.
- Defina o Modo do Pipeline como Disparado. No modo Disparado, o pipeline DLT consumirá novos dados na origem de uma vez, e assim que o processamento for concluído, ele encerrará o recurso de computação automaticamente. Você pode alternar entre os modos Disparado e Contínuo ao editar as configurações do seu pipeline. Definir "continuous": false no JSON é equivalente a definir o pipeline para o modo Disparado.
- Para esta carga de trabalho, você pode desabilitar a escalabilidade automática em Opções do Autopilot e usar apenas 1 cluster de worker. Para cargas de trabalho de produção, recomendamos habilitar a escalabilidade automática e definir o número máximo de workers necessários para o tamanho do cluster.
- Selecione "Iniciar"
- Seu pipeline foi criado e está em execução agora!
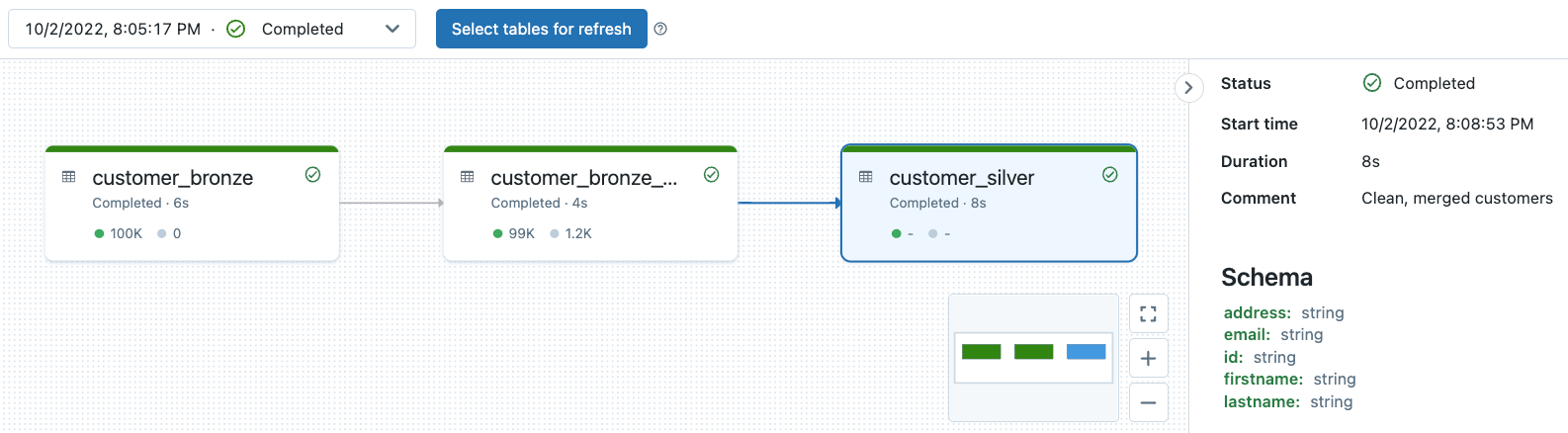
Observabilidade de Linhagem e Monitoramento de Qualidade de Dados do Pipeline DLT
Todos os logs do pipeline DLT são armazenados no local de armazenamento do pipeline. Você pode especificar seu local de armazenamento apenas ao criar seu pipeline. Observe que, uma vez criado o pipeline, você não poderá mais modificar o local de armazenamento.
Você pode conferir nosso mergulho profundo anterior no tópico aqui. Experimente este notebook para ver a observabilidade do pipeline e o monitoramento da qualidade de dados no pipeline DLT de exemplo associado a este blog.
Conclusão
Neste blog, mostramos como tornamos simples para os usuários implementar eficientemente a captura de dados de alteração (CDC) em sua plataforma Lakehouse com o Delta Live Tables (DLT). O DLT fornece controles de qualidade integrados com visibilidade profunda nas operações do pipeline, observando a linhagem do pipeline, monitorando o esquema e verificações de qualidade em cada etapa do pipeline. O DLT suporta tratamento automático de erros e a melhor capacidade de escalabilidade automática para cargas de trabalho de streaming, o que permite aos usuários ter dados de qualidade com recursos ideais necessários para sua carga de trabalho.
Os engenheiros de dados agora podem implementar facilmente o CDC com a nova API declarativa APPLY CHANGES INTO com DLT em SQL ou Python. Essa nova capacidade permite que seus pipelines de ETL identifiquem facilmente alterações e apliquem essas alterações em dezenas de milhares de tabelas com suporte de baixa latência.
Assista a este webinar para aprender como o Delta Live Tables simplifica a complexidade da transformação de dados e ETL, e confira nosso documento Captura de dados de alteração com Delta Live Tables, o github oficial e siga as etapas neste vídeo para criar seu pipeline!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.