Colunas de Identidade para Gerar Chaves Substituto Agora Disponíveis Perto de Você!
por Franco Patano
O que é uma coluna de identidade?
Uma coluna de identidade é uma coluna em um banco de dados que gera automaticamente um número de ID exclusivo para cada nova linha de dados. Esse número não está relacionado ao conteúdo da linha.
Colunas de identidade são uma forma de chaves substitutas. Em data warehouses, é comum usar uma chave adicional, chamada chave substituta, para identificar exclusivamente cada linha e acompanhar as alterações nos dados ao longo do tempo. Além disso, é recomendado usar chaves substitutas em vez de chaves naturais. Chaves substitutas são geradas pelo sistema e não dependem de vários campos para identificar a exclusividade da linha.
Portanto, colunas de identidade são usadas para criar chaves substitutas, que podem servir como chaves primárias e estrangeiras em modelos dimensionais para data warehouses e data marts. Como visto abaixo, essas chaves são as colunas que conectam diferentes tabelas umas às outras em um modelo dimensional tradicional como um esquema estrela.
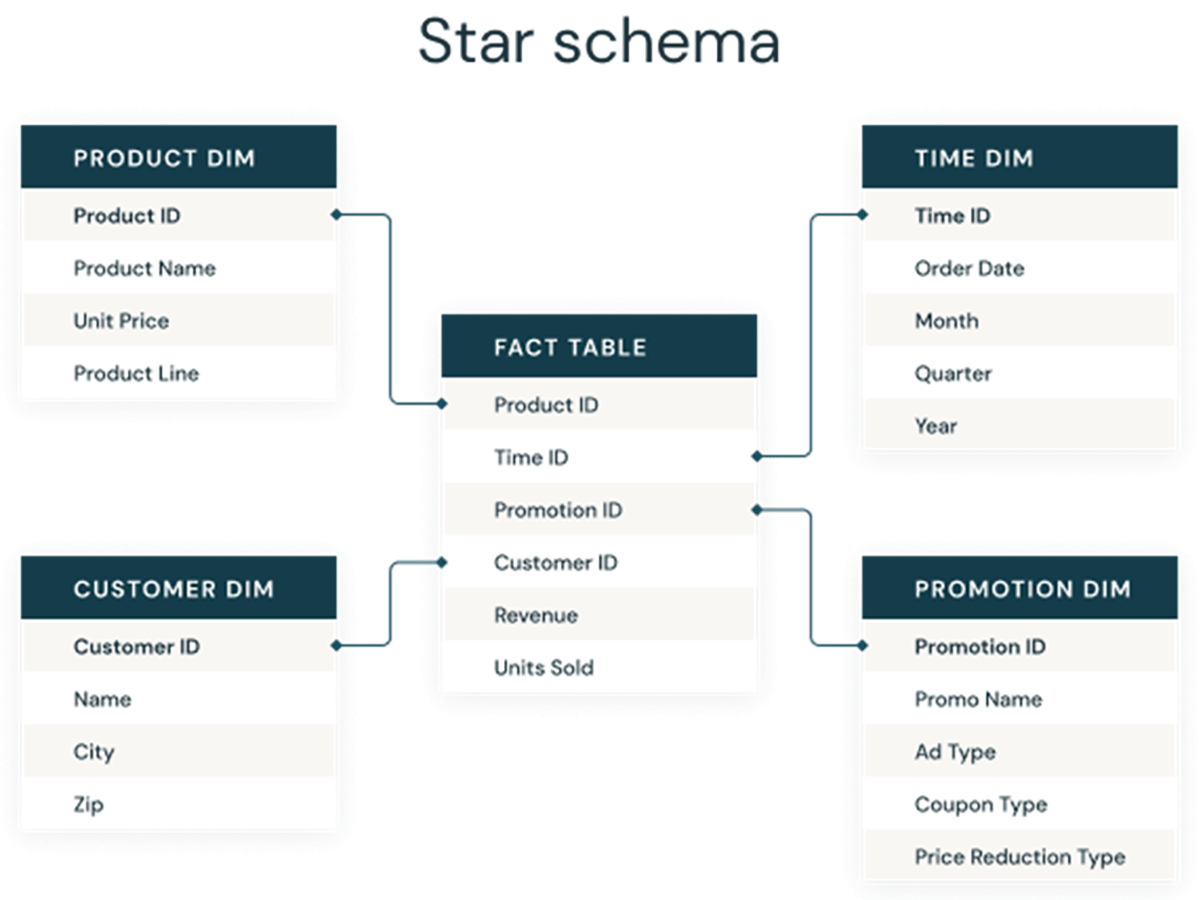
Abordagens tradicionais para gerar chaves substitutas em data lakes
A maioria das tecnologias de big data usa paralelismo, ou a capacidade de dividir uma tarefa em partes menores que podem ser concluídas ao mesmo tempo, para melhorar o desempenho. Nos primórdios dos data lakes, não havia uma maneira fácil de criar sequências exclusivas em um grupo de máquinas. Isso levou alguns engenheiros de dados a usar métodos menos confiáveis para gerar chaves substitutas sem um recurso adequado, como:
monotonically_increasing_id(),row_number(),Rank OVER,ZipWithIndex(),ZipWithUniqueIndex(),- Hash de Linha com
hash(),e - Hash de Linha com
md5().
Embora essas funções sejam capazes de realizar o trabalho em certas circunstâncias, elas geralmente vêm com muitos avisos e ressalvas sobre o preenchimento esparso das sequências, problemas de desempenho em escala e problemas de transações concorrentes.
Bancos de dados têm sido capazes de gerar sequências desde os primórdios, para gerar chaves substitutas para identificar exclusivamente uma linha de dados com a ajuda de um gerenciador de transações centralizado. No entanto, implementações típicas exigem bloqueios e commits transacionais, que podem ser difíceis de gerenciar.
Colunas de identidade no Delta Lake facilitam a geração de chaves substitutas
Colunas de identidade resolvem os problemas mencionados acima e fornecem uma solução simples e performática para gerar chaves substitutas. Delta Lake é o primeiro protocolo de data lake a habilitar colunas de identidade para geração de chaves substitutas.
O Delta Lake agora suporta a criação de colunas IDENTITY que podem gerar automaticamente números de ID exclusivos e auto-incrementais quando novas linhas são carregadas. Embora esses números de ID possam não ser consecutivos, o Delta faz o melhor esforço para manter a lacuna o menor possível. Você pode usar este recurso para criar chaves substitutas para suas cargas de trabalho de data warehousing facilmente.
Como criar uma chave substituta com uma coluna de identidade usando SQL e Delta Lake
[Recomendado] Gerar Sempre Como Identidade
Criar uma coluna de identidade em SQL é tão simples quanto criar uma tabela Delta Lake. Ao declarar suas colunas, adicione um nome de coluna chamado id, ou o que você preferir, com um tipo de dados BIGINT, e insira GENERATED ALWAYS AS IDENTITY.
Agora, toda vez que você realizar uma operação nesta tabela onde insere dados, omita esta coluna da inserção, e o Delta Lake gerará automaticamente um valor exclusivo para a coluna IDENTITY para cada linha inserida na tabela Delta Lake.
Aqui está um exemplo simples de como usar colunas de identidade no Delta Lake:
Daqui em diante, a coluna de identidade intitulada "id" será auto-incrementada sempre que você inserir novos registros na tabela. Você pode então inserir novos dados assim:
Observe como a coluna de chave substituta intitulada "id" está ausente da parte INSERT da instrução. O Delta Lake preencherá as chaves substitutas quando gravar a tabela no armazenamento de objetos na nuvem (por exemplo, AWS S3, Azure Data Lake Storage ou Google Cloud Storage). Saiba mais na documentação.
Gerar por PADRÃO
Existe também a opção GENERATED BY DEFAULT AS IDENTITY, que permite que a inserção de identidade seja substituída, enquanto a opção ALWAYS não pode ser substituída.
Existem algumas ressalvas que você deve ter em mente ao adotar este novo recurso. Colunas de identidade não podem ser adicionadas a tabelas existentes; as tabelas precisarão ser recriadas com a nova coluna de identidade adicionada. Para fazer isso, basta criar um novo DDL de tabela com a coluna de identidade e inserir as colunas existentes na nova tabela, e as chaves substitutas serão geradas para a nova tabela.
Comece hoje mesmo com Colunas de Identidade no Delta Lake no Databricks SQL
Colunas de Identidade estão agora em GA (Geralmente Disponíveis) no Databricks Runtime 10.4+ e no Databricks SQL 2022.17+. Com colunas de identidade, você pode agora habilitar todas as suas cargas de trabalho de data warehousing para ter todos os benefícios de uma arquitetura Lakehouse, acelerada pelo Photon. Experimente as colunas de identidade no Databricks SQL hoje mesmo.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.