Apache Spark Connect disponível no Apache Spark 3.4
Execute Aplicações Spark em Qualquer Lugar
por Allan Folting, Hyukjin Kwon, Xiao Li, Herman van Hövell, Stefania Leone, Martin Grund, Reynold Xin e Kris Mo
No ano passado, o Spark Connect foi apresentado no Data and AI Summit. Como parte do Apache SparkTM 3.4, recém-lançado, o Spark Connect está agora geralmente disponível. Nós também reestruturamos recentemente o Databricks Connect para ser baseado no Spark Connect. Este post do blog detalha o que é o Spark Connect, como ele funciona e como usá-lo.
Os usuários agora podem conectar IDEs, Notebooks e aplicações de dados modernas diretamente a clusters Spark
O Spark Connect introduz uma arquitetura cliente-servidor desacoplada que permite conectividade remota a clusters Spark de qualquer aplicação, rodando em qualquer lugar. Essa separação de cliente e servidor permite que aplicações de dados modernas, IDEs, Notebooks e linguagens de programação acessem o Spark interativamente.
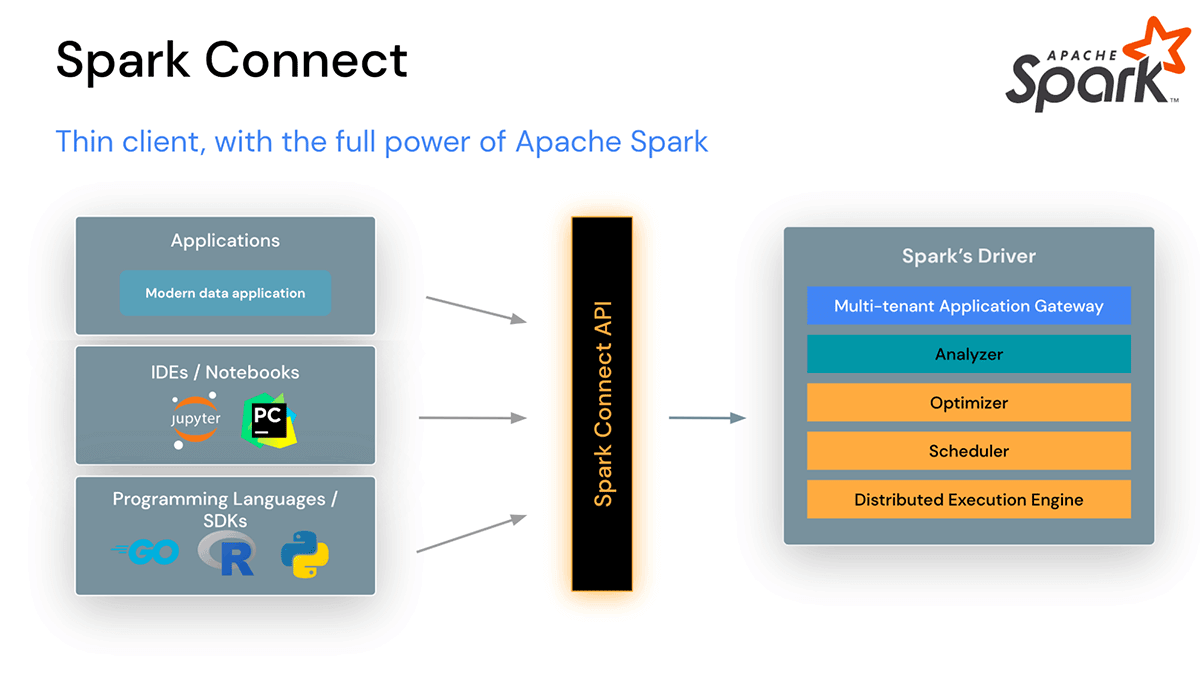
Spark Connect melhora Estabilidade, Atualizações, Depuração e Observabilidade
Com esta nova arquitetura, o Spark Connect também mitiga problemas operacionais comuns:
Estabilidade: Aplicações que usam muita memória agora impactarão apenas seu próprio ambiente, pois podem rodar em seus próprios processos fora do cluster Spark. Os usuários podem definir suas próprias dependências no ambiente cliente e não precisam se preocupar com possíveis conflitos de dependência no driver Spark.
Por exemplo, se você tem uma aplicação cliente que recupera um grande conjunto de dados do Spark para análise ou para fazer transformações, essa aplicação não rodará mais no driver Spark. Isso significa que, se a aplicação usar muita memória ou ciclos de CPU, ela não competirá por recursos com outras aplicações no driver Spark, potencialmente fazendo com que essas outras aplicações diminuam a velocidade ou falhem, pois ela agora roda em seu próprio ambiente separado e dedicado.
Atualizabilidade: No passado, era extremamente complicado atualizar o Spark, pois todas as aplicações no mesmo cluster Spark precisavam ser atualizadas junto com o cluster ao mesmo tempo. Com o Spark Connect, as aplicações podem ser atualizadas independentemente do servidor, devido à separação de cliente e servidor. Isso torna a atualização muito mais fácil, pois as organizações não precisam fazer nenhuma alteração em suas aplicações cliente ao atualizar o Spark.
Depuração e observabilidade: O Spark Connect permite a depuração interativa passo a passo durante o desenvolvimento diretamente do seu IDE favorito. Da mesma forma, as aplicações podem ser monitoradas usando as métricas nativas e bibliotecas de log do framework da aplicação.
Por exemplo, você pode depurar interativamente uma aplicação cliente Spark Connect no Visual Studio Code, inspecionar objetos e executar comandos de depuração para testar e corrigir problemas em seu código.
Como o Spark Connect funciona
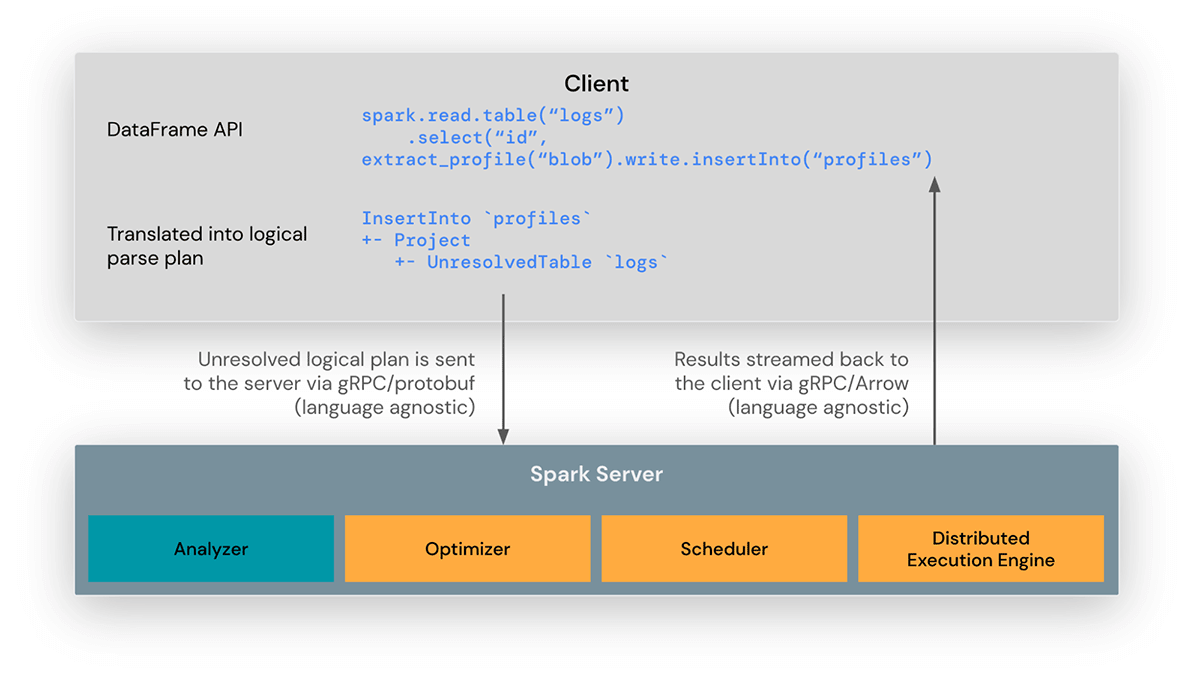
A biblioteca cliente Spark Connect foi projetada para simplificar o desenvolvimento de aplicações Spark. É uma API leve que pode ser incorporada em qualquer lugar: em servidores de aplicação, IDEs, notebooks e linguagens de programação. A API Spark Connect baseia-se na API DataFrame do Spark, usando planos lógicos não resolvidos como um protocolo agnóstico de linguagem entre o cliente e o driver Spark.
O cliente Spark Connect traduz operações de DataFrame em planos lógicos não resolvidos que são codificados usando protocol buffers. Estes são enviados ao servidor usando o framework gRPC.
O endpoint Spark Connect incorporado no driver Spark recebe e traduz planos lógicos não resolvidos em operadores de plano lógico do Spark. Isso é semelhante a analisar uma consulta SQL, onde atributos e relações são analisados e um plano de análise inicial é construído. A partir daí, o processo de execução padrão do Spark entra em ação, garantindo que o Spark Connect aproveite todas as otimizações e melhorias do Spark. Os resultados são transmitidos de volta para o cliente através do gRPC como lotes de resultados codificados em Apache Arrow.
Como usar o Spark Connect
A partir do Spark 3.4, o Spark Connect está disponível e suporta aplicações PySpark e Scala. Vamos percorrer um exemplo de conexão a um servidor Apache Spark com Spark Connect a partir de uma aplicação cliente usando a biblioteca cliente Spark Connect.
Ao escrever aplicações Spark, a única vez que você precisa considerar o Spark Connect é ao criar sessões Spark. Todo o resto do seu código é exatamente o mesmo de antes.
Para usar o Spark Connect, você pode simplesmente definir uma variável de ambiente (SPARK_REMOTE) para sua aplicação usar, sem fazer nenhuma alteração no código, ou pode incluir explicitamente o Spark Connect em seu código ao criar sessões Spark.
Vamos dar uma olhada em um exemplo de notebook Jupyter. Neste notebook, criamos uma sessão Spark Connect para um cluster Spark local, criamos um DataFrame PySpark e mostramos os 10 principais artistas de música por número de ouvintes.
Neste exemplo, estamos especificando explicitamente que queremos usar o Spark Connect definindo a propriedade remota ao criar nossa sessão Spark (SparkSession.builder.remote...).
Código do notebook Jupyter usando Spark Connect
Você pode baixar o conjunto de dados usado no exemplo aqui: Popularidade de artistas de música | Kaggle
Como ilustrado no exemplo a seguir, o Spark Connect também facilita a alternância entre diferentes clusters Spark, por exemplo, ao desenvolver e testar em um cluster Spark local e, em seguida, mover seu código para produção em um cluster remoto.
Neste exemplo, definimos a variável de ambiente TEST_ENV para direcionar qual cluster Spark e local de dados nossa aplicação usará, para que não precisemos fazer nenhuma alteração no código para alternar entre nossos clusters de teste, staging e produção.
Alternando entre diferentes clusters Spark usando uma variável de ambiente
Para saber mais sobre como usar o Spark Connect, visite as páginas Visão Geral do Spark Connect e Guia Rápido do Spark Connect.
Databricks Connect é construído sobre Spark Connect
A partir do Databricks Runtime 13.0, o Databricks Connect agora é construído sobre o Spark Connect de código aberto. Com esta arquitetura “v2”, o Databricks Connect se torna um cliente leve que é simples e fácil de usar. Ele pode ser incorporado em qualquer lugar para se conectar ao Databricks: em IDEs, Notebooks e qualquer aplicação, permitindo que clientes e parceiros criem novas experiências de usuário (interativas) baseadas no seu Databricks Lakehouse. É muito fácil de usar: os usuários simplesmente incorporam a biblioteca Databricks Connect em suas aplicações e se conectam ao seu Databricks Lakehouse.
APIs suportadas no Apache Spark 3.4
PySpark: No Spark 3.4, o Spark Connect suporta a maioria das APIs PySpark, incluindo DataFrame, Functions e Column. As APIs PySpark suportadas são rotuladas como “Supports Spark Connect” na documentação de referência da API, para que você possa verificar se as APIs que está usando estão disponíveis antes de migrar o código existente para o Spark Connect.
Scala: No Spark 3.4, o Spark Connect suporta a maioria das APIs Scala, incluindo Dataset, functions e Column.
O suporte para streaming estará disponível em breve e esperamos trabalhar com a comunidade para entregar mais APIs para o Spark Connect nas próximas versões do Spark.
O Spark Connect no Apache Spark 3.4 abre o acesso ao Spark de qualquer aplicativo baseado em DataFrames/DataSets em PySpark e Scala, e estabelece a base para o suporte a outras linguagens de programação no futuro.
Com desenvolvimento simplificado de aplicativos cliente, contenção de memória mitigada no driver do Spark, gerenciamento de dependências separado para aplicativos cliente, atualizações independentes de cliente e servidor, depuração IDE passo a passo, e logging e métricas de cliente leve, o Spark Connect torna o acesso ao Spark ubíquo.
Para saber mais sobre o Spark Connect e começar, visite as páginas Visão Geral do Spark Connect e Guia de Início Rápido do Spark Connect.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.