Segurança de IA Agente: Novos Riscos e Controles no Framework de Segurança de IA da Databricks (DASF v3.0)
35 novos riscos de IA agentic e 6 controles de mitigação para agentes que acessam dados, chamam ferramentas e executam ações
por David Veuve, Omar Khawaja, Arun Pamulapati, Nishith Sinha e Caelin Kaplan
- O Databricks AI Security Framework (DASF) agora cobre IA Agentic como seu 13º componente de sistema, adicionando 35 novos riscos técnicos de segurança e 6 novos controles de mitigação para ajudar as organizações a implantar agentes autônomos com confiança.
- Esta extensão aborda os riscos únicos de memória, planejamento e uso de ferramentas de agentes, incluindo ameaças introduzidas pelo Model Context Protocol (MCP), o padrão emergente para conectar agentes a ferramentas corporativas.
- O whitepaper da Extensão de IA Agentic do DASF e o compêndio atualizado já estão disponíveis. Baixe-os para avaliar suas arquiteturas de agentes, mapear seus ecossistemas de ferramentas e implementar controles de defesa em profundidade projetados especificamente para autonomia.
Estamos animados em anunciar o lançamento do whitepaper Databricks AI Security Framework (DASF) Agentic AI Extension! Os clientes Databricks já estão implantando agentes de IA que consultam bancos de dados, chamam APIs externas, executam código e coordenam com outros agentes. Ouvimos constantemente que as equipes responsáveis por essas implantações estão fazendo perguntas difíceis: o que acontece quando a IA pode fazer coisas, não apenas dizer coisas? É por isso que estendemos o DASF.
Com esta atualização, introduzimos novas orientações para proteger agentes autônomos de IA:
- 35 novos riscos de segurança de IA agentic cobrindo raciocínio, memória e uso de ferramentas do agente
- 6 novos controles de mitigação incluindo privilégio mínimo, sandboxing e supervisão humana
- Orientação de segurança para servidores e clientes de ferramentas do Model Context Protocol (MCP)
- Cobertura para riscos de sistemas multiagentes e ameaças de comunicação entre agentes
Juntas, essas adições ajudam as organizações a implantar agentes de IA com segurança, mantendo a governança, a observabilidade e os controles de segurança de defesa em profundidade.
Isso eleva o framework completo para 97 riscos e 73 controles. Atualizamos o compêndio DASF (Google sheet, Excel) para incluir esses novos riscos e controles, mapeando-os para padrões da indústria para facilitar a operacionalização imediata. Essas adições são catalogadas como DASF v3.0 na coluna "DASF Revision".
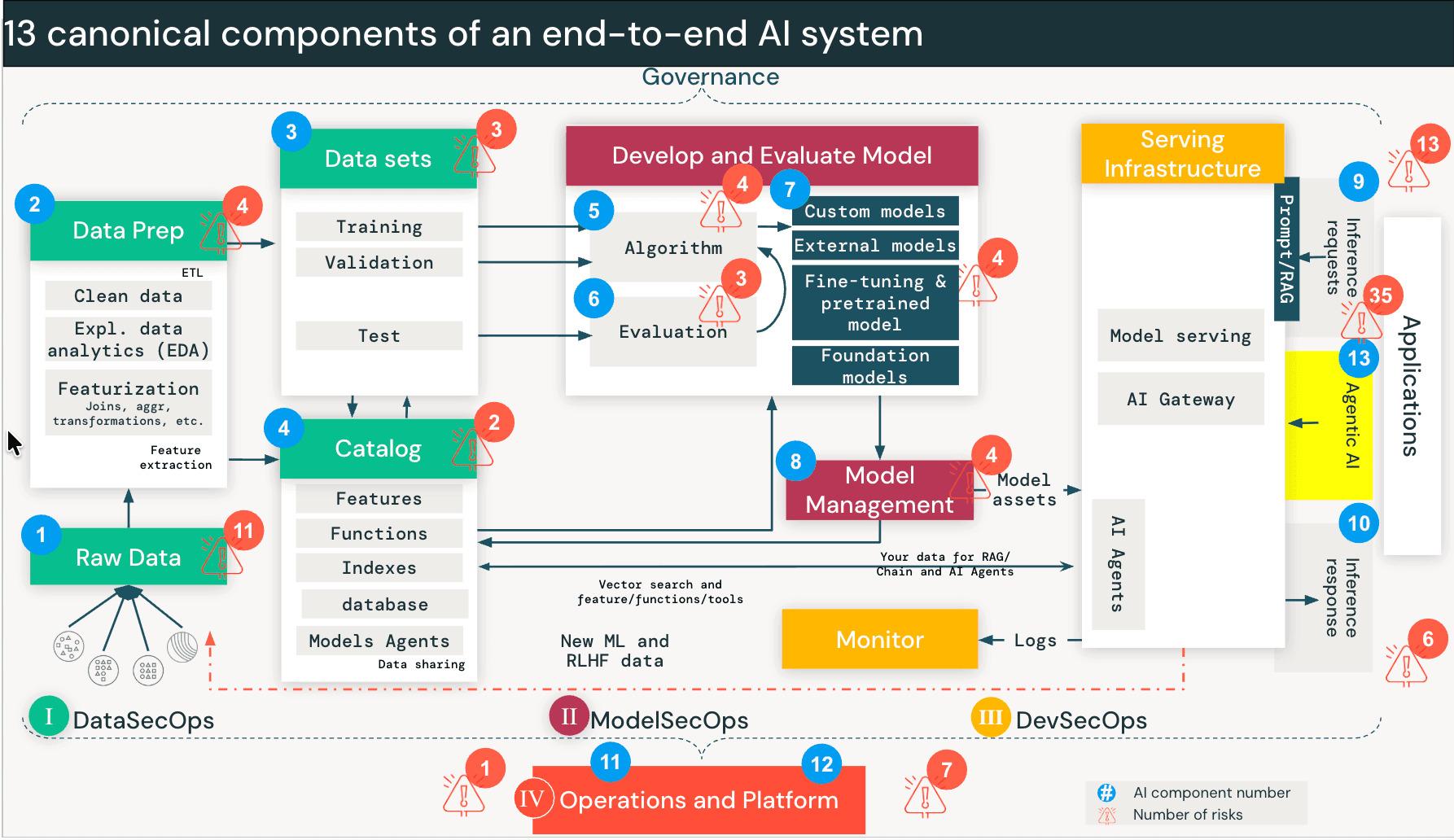
{kind=link}
Riscos de segurança quando agentes de IA podem tomar ações
Sistemas tradicionais de IA como RAG operam principalmente em modo somente leitura. Mas agentes de IA podem tomar ações como consultar bancos de dados, chamar APIs, executar código e interagir com ferramentas externas.
Agentes funcionam de maneira diferente. Quando um usuário interage com um agente, o modelo inicia um loop: ele divide a solicitação em subtarefas, escolhe uma ferramenta (por exemplo, "Consultar Banco de Dados de Vendas"), a executa, avalia o resultado e decide se deve chamar outra ferramenta em seguida. Isso continua até que a tarefa seja concluída. O agente está tomando decisões em tempo real sobre quais dados acessar e quais ferramentas invocar — decisões que antes eram tomadas por humanos ou codificadas na lógica do aplicativo.
Isso cria uma nova classe de risco que chamamos de Descoberta e Travessia. Um agente projetado para encontrar soluções percorrerá caminhos de dados e interfaces de ferramentas que nunca foram destinados ao usuário solicitante. Não é uma exploração de um bug. É exatamente o que foi construído para fazer. Mas sem os controles adequados, o usuário efetivamente herda as permissões do agente em vez das suas.
A Tríade Letal. Pesquisas recentes da indústria, incluindo o “Agents Rule of Two” da Meta e modelos semelhantes como o “Lethal Trifecta” de Simon Willison, destacam as condições sob as quais isso se torna perigoso. O perfil de risco aumenta quando três condições estão presentes simultaneamente:
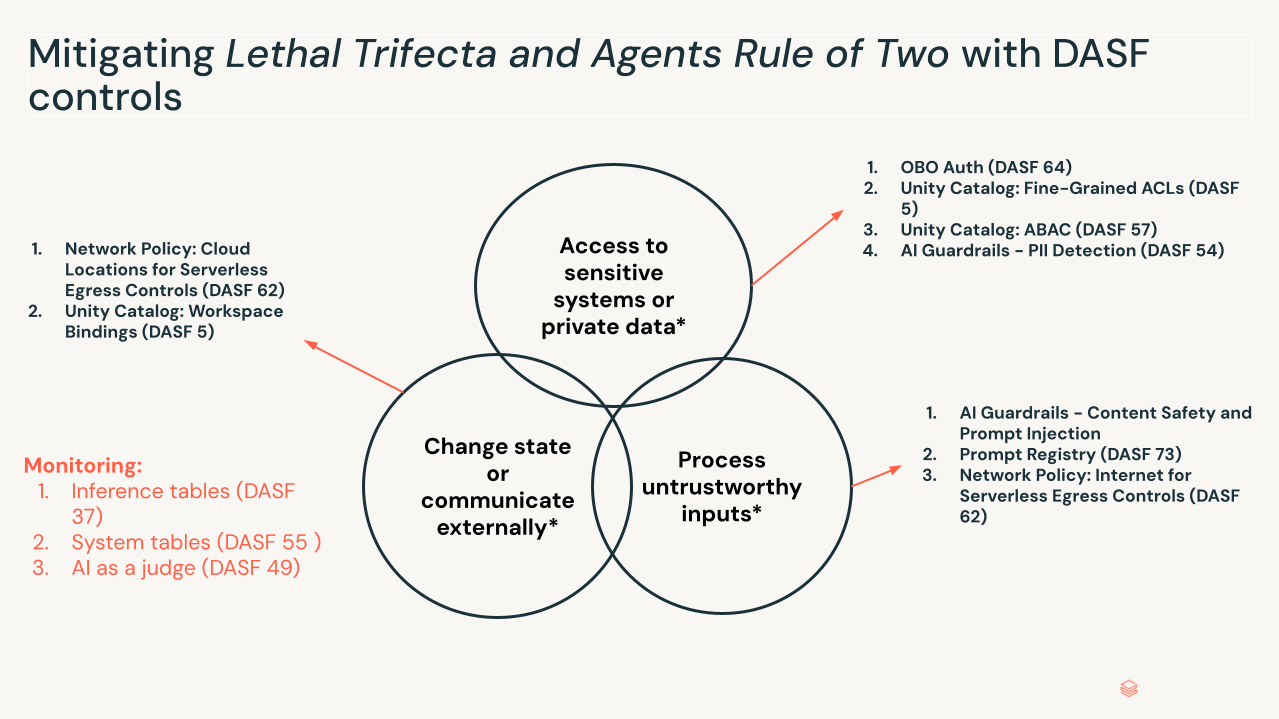
- Acesso a sistemas sensíveis ou dados privados: O agente pode recuperar dados privados ou restritos.
- Processar entradas não confiáveis: O agente processa dados de fora do limite de confiança — prompts do usuário, sites externos, e-mails recebidos.
- Alterar estado ou comunicar externamente: O agente pode modificar o estado por meio de ferramentas ou conexões MCP — enviando e-mails, executando SQL, modificando código.
Com todas as três em vigor, uma injeção de prompt indireta incorporada em dados não confiáveis pode sequestrar todo o conjunto de capacidades do agente, transformando-o em um "deputado confuso" que executa ações autorizadas com intenção maliciosa. Remova qualquer um dos três elementos, limitando as permissões, adicionando um ponto de verificação humano, validando a intenção antes da seleção da ferramenta e quebrando a cadeia de ataque.
Como a extensão é organizada
Os 35 novos riscos e 6 controles são organizados em torno de três subcomponentes que mapeiam como os agentes realmente funcionam:
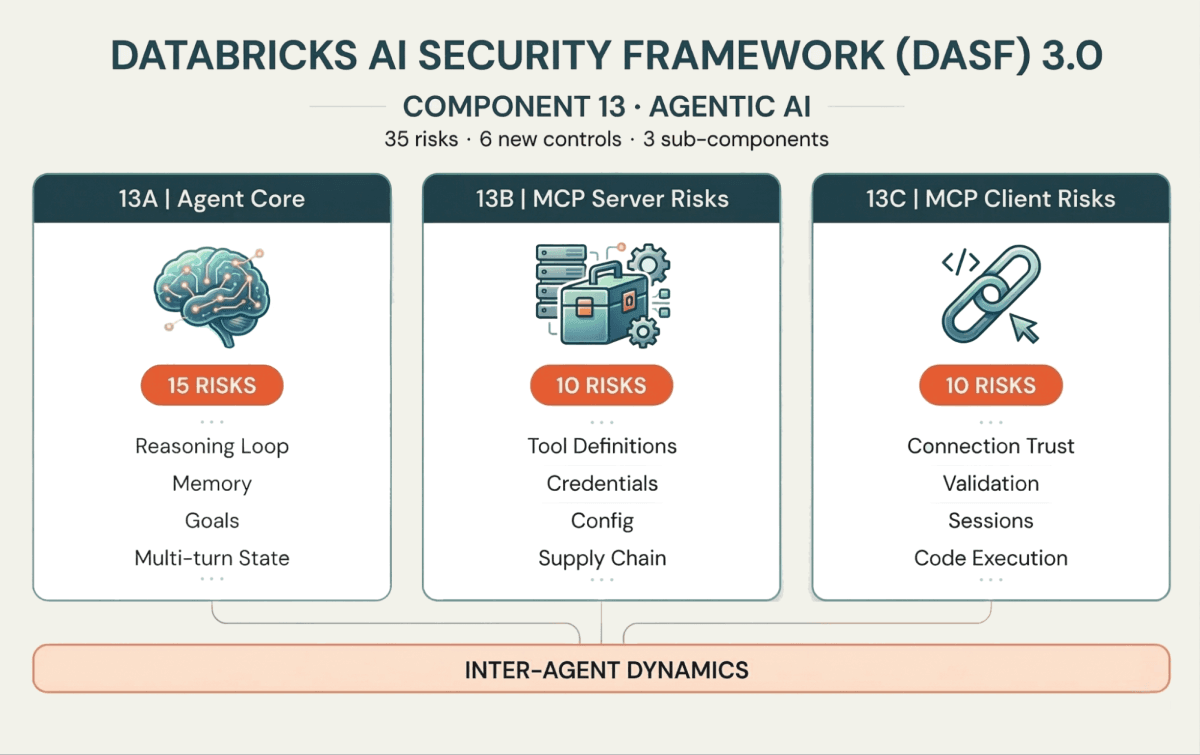
13A: O Núcleo do Agente (cérebro e memória)
Esses riscos visam o loop de raciocínio do agente. Envenenamento de Memória (Risco 13.1) introduz contexto falso que altera decisões atuais ou futuras. Quebra de Intenção e Manipulação de Objetivos (Risco 13.6) força o agente a se desviar de seu objetivo. E como os agentes operam em loops multi-turn, Ataques de Alucinação em Cascata (Risco 13.5) podem agravar um pequeno erro ao longo das iterações em uma ação destrutiva.
13B: Riscos do Servidor MCP (a interface da ferramenta)
Agentes interagem com sistemas externos por meio de ferramentas, cada vez mais padronizadas via Model Context Protocol (MCP). No lado do servidor, os atacantes podem implantar Envenenamento de Ferramentas (Risco 13.18) — injetando comportamento malicioso nas definições de ferramentas — ou explorar Injeção de Prompt (Risco 13.16) dentro das descrições de ferramentas para contornar os controles de segurança.
13C: Riscos do Cliente MCP (a camada de conexão)
No lado do cliente, se o agente se conectar a um Servidor Malicioso (Risco 13.26) ou falhar em validar as respostas do servidor, ele corre o risco de Execução de Código no Lado do Cliente (Risco 13.32) ou Vazamento de Dados (Risco 13.30). À medida que a adoção do MCP cresce, proteger a fronteira cliente-servidor é tão importante quanto proteger o raciocínio do agente.
Dinâmica entre agentes
Agentes se comunicarão cada vez mais com outros agentes. Isso cria riscos de Envenenamento de Comunicação de Agentes (Risco 13.12) e Agentes Invasores em Sistemas Multiagentes (Risco 13.13) — agentes que operam fora dos limites de monitoramento, um problema que se agrava com a escala.
Controles para proteger agentes de IA e sistemas autônomos
O DASF sempre foi sobre defesa em profundidade. Mas quando um sistema de IA pode tomar ações, controles de acesso somente leitura não são suficientes. Os novos controles abordam isso diretamente:
- Privilégio mínimo para ferramentas (DASF 5, DASF 57, DASF 64): Agentes precisam de permissões granulares com escopo para sua tarefa imediata, limitando o raio de explosão da mesma forma que RBAC e ABAC limitam um humano. Só porque um agente pode chamar a Ferramenta de Métricas de RH não significa que ele deva ao responder a uma consulta de vendas.
- Supervisão humana no loop (DASF 66): Para ações de alto risco, exija verificação humana antes da execução da ferramenta. O design do controle considera a fadiga de aprovação — se você sobrecarregar o revisor humano, criou uma nova vulnerabilidade, não resolveu uma.
- Sandboxing e isolamento (DASF 34, DASF 62): O código gerado pelo agente é executado em ambientes efêmeros e isolados. Se um agente decidir escrever e executar um script, essa execução não deve ter acesso ao sistema mais amplo e às conexões de saída para destinos desconhecidos.
- Gateway de IA e Guardrails (DASF 54): Agentes precisam de proteções contra cenários em que um agente está sendo manipulado para exibir dados que não deveria. As interações dos agentes via gateway e guardrails, como monitoramento, filtragem de segurança e detecção de PII, precisam ser aplicadas. Esses guardrails podem ser aplicados à entrada ou saída de um agente (ou ambos). Também é igualmente importante monitorar o que está sendo retornado pelo agente.
- Observabilidade do pensamento (DASF 65): O registro padrão informa o que aconteceu. O rastreamento agentic captura por que — as etapas de planejamento, o raciocínio da seleção de ferramentas, a cadeia de pensamento que levou a uma ação. Sem isso, você não pode auditar as decisões de um agente ou detectar quando seu raciocínio foi comprometido.
Para clientes Databricks, o compêndio mapeia esses controles para capacidades da plataforma, incluindo a governança do Unity Catalog para acesso a dados de agentes, o Agent Bricks Framework, os mecanismos de proteção do AI Gateway e as configurações de segurança do AI Search.
Construído com a comunidade
Esta extensão reflete o feedback de revisores e colaboradores da Databricks e da comunidade de segurança, incluindo equipes da Atlassian, Experian e ComplyLeft. Também nos baseamos fortemente no trabalho da MITRE ATLAS, OWASP, NIST e Cloud Security Alliance — o compêndio atualizado mapeia todos os 97 riscos e 73 controles para esses padrões da indústria.
Comece agora
Baixe o whitepaper do DASF Agentic AI Extension para o tratamento completo de todos os 35 novos riscos de IA agentic e 6 novos controles, e pegue o compêndio atualizado (Google Sheet, Excel) que agora mapeia riscos e controles agentic ao lado do DASF original. Use esses recursos para:
- Avaliar suas arquiteturas de agentes atuais em relação ao modelo de risco de IA de agentes.
- Mapear seus ecossistemas de ferramentas — incluindo servidores e clientes MCP — para os vetores de ameaça identificados.
- Implementar os controles recomendados para garantir que seus agentes operem dentro de limites seguros e governados.
Para um contexto mais aprofundado, leia o whitepaper completo do DASF e explore a documentação do Agent Bricks Framework para ver como esses controles funcionam na plataforma.
Entre em contato com sua equipe de contas Databricks ou envie um e-mail para dasf@databricks.com com feedback — este framework pertence à comunidade tanto quanto a nós.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.