Uma Introdução à Previsão de Séries Temporais com IA Generativa
por Ryuta Yoshimatsu , Puneet Jain e Bryan Smith
Uma Introdução à Previsão de Séries Temporais com IA Generativa
A previsão de séries temporais tem sido um pilar do planejamento de recursos empresariais por décadas. Previsões sobre a demanda futura orientam decisões críticas, como a quantidade de unidades a serem estocadas, a mão de obra a ser contratada, investimentos de capital em infraestrutura de produção e logística, e a precificação de bens e serviços. Previsões de demanda precisas são essenciais para essas e muitas outras decisões de negócios.
No entanto, as previsões raramente são perfeitas. Em meados da década de 2010, muitas organizações, lidando com limitações computacionais e acesso restrito a capacidades avançadas de previsão, relatavam acurácias de previsão de apenas 50-60%. Mas com a adoção mais ampla da nuvem, a introdução de tecnologias muito mais acessíveis e a melhoria no acesso a fontes de dados externas, como dados meteorológicos e de eventos, as organizações estão começando a ver melhorias.
À medida que entramos na era da IA generativa, uma nova classe de modelos, referida como transformadores de séries temporais, parece capaz de ajudar as organizações a entregar ainda mais melhorias. Semelhante aos modelos de linguagem grandes (como o ChatGPT), que se destacam na previsão da próxima palavra em uma frase, os transformadores de séries temporais preveem o próximo valor em uma sequência numérica. Com exposição a grandes volumes de dados de séries temporais, esses modelos se tornam especialistas em captar padrões sutis de relacionamento entre os valores dessas séries, com sucesso demonstrado em uma variedade de domínios.
Neste blog, forneceremos uma introdução de alto nível a essa classe de modelos de previsão, destinada a ajudar gerentes, analistas e cientistas de dados a desenvolver uma compreensão básica de como eles funcionam. Em seguida, forneceremos acesso a uma série de notebooks criados em torno de conjuntos de dados publicamente disponíveis, demonstrando como as organizações que armazenam seus dados no Databricks podem facilmente acessar vários dos modelos mais populares para suas necessidades de previsão. Esperamos que isso ajude as organizações a aproveitar o potencial da IA generativa para impulsionar melhores acurácias de previsão.
Entendendo os Transformadores de Séries Temporais
Modelos de IA generativa são uma forma de rede neural profunda, um modelo complexo de machine learning no qual um grande número de entradas é combinado de várias maneiras para chegar a um valor previsto. A mecânica de como o modelo aprende a combinar entradas para chegar a uma previsão precisa é referida como a arquitetura de um modelo.
O avanço nas redes neurais profundas que deu origem à IA generativa foi o design de uma arquitetura de modelo especializada chamada transformador. Embora os detalhes exatos de como os transformadores diferem de outras arquiteturas de redes neurais profundas sejam bastante complexos, a questão simples é que o transformador é muito bom em captar os relacionamentos complexos entre valores em sequências longas.
Para treinar um transformador de séries temporais, uma rede neural profunda adequadamente arquitetada é exposta a um grande volume de dados de séries temporais. Após ter tido a oportunidade de treinar em milhões, senão bilhões, de valores de séries temporais, ela aprende os padrões complexos de relacionamento encontrados nesses conjuntos de dados. Quando é então exposta a uma série temporal nunca vista antes, ela pode usar esse conhecimento fundamental para identificar onde padrões semelhantes de relacionamento existem dentro da série temporal e prever novos valores na sequência.
Esse processo de aprendizado de relacionamentos a partir de grandes volumes de dados é referido como pré-treinamento. Como o conhecimento adquirido pelo modelo durante o pré-treinamento é altamente generalizável, modelos pré-treinados referidos como modelos de fundação podem ser empregados em séries temporais nunca vistas antes sem treinamento adicional. Dito isso, treinamento adicional nos dados proprietários de uma organização, um processo referido como fine-tuning, pode em alguns casos ajudar a organização a alcançar uma precisão de previsão ainda melhor. De qualquer forma, uma vez que o modelo é considerado em um estado satisfatório, a organização simplesmente precisa apresentá-lo com uma série temporal e perguntar: o que vem a seguir?
Abordando Desafios Comuns de Séries Temporais
Embora essa compreensão de alto nível de um transformador de séries temporais possa fazer sentido, a maioria dos praticantes de previsão provavelmente terá três perguntas imediatas. Primeiro, embora duas séries temporais possam seguir um padrão semelhante, elas podem operar em escalas completamente diferentes; como um transformador supera esse problema? Segundo, dentro da maioria dos modelos de séries temporais existem padrões diários, semanais e anuais de sazonalidade que precisam ser considerados; como os modelos sabem procurar por esses padrões? Terceiro, muitas séries temporais são influenciadas por fatores externos; como esses dados podem ser incorporados ao processo de geração de previsões?
O primeiro desses desafios é abordado pela padronização matemática de todos os dados de séries temporais usando um conjunto de técnicas referidas como scaling. A mecânica disso é interna à arquitetura de cada modelo, mas essencialmente os valores de entrada da série temporal são convertidos para uma escala padrão que permite ao modelo reconhecer padrões nos dados com base em seu conhecimento fundamental. As previsões são feitas e, em seguida, essas previsões são retornadas à escala original dos dados originais.
Em relação aos padrões sazonais, no coração da arquitetura do transformador está um processo chamado self-attention. Embora esse processo seja bastante complexo, fundamentalmente esse mecanismo permite que o modelo aprenda o grau em que valores anteriores específicos influenciam um determinado valor futuro.
Embora isso pareça a solução para sazonalidade, é importante entender que os modelos diferem em sua capacidade de captar padrões de sazonalidade de baixo nível com base em como eles dividem as entradas de séries temporais. Através de um processo chamado tokenization, os valores em uma série temporal são divididos em unidades chamadas tokens. Um token pode ser um único valor de série temporal ou uma sequência curta de valores (frequentemente referida como um patch).
O tamanho do token determina o nível mais baixo de granularidade em que os padrões sazonais podem ser detectados. (A tokenização também define a lógica para lidar com valores ausentes.) Ao explorar um modelo específico, é importante ler as informações, às vezes técnicas, sobre tokenização para entender se o modelo é apropriado para seus dados.
Finalmente, em relação às variáveis externas, os transformadores de séries temporais empregam uma variedade de abordagens. Em alguns, os modelos são treinados tanto em dados de séries temporais quanto em variáveis externas relacionadas. Em outros, os modelos são arquitetados para entender que uma única série temporal pode ser composta por múltiplas sequências paralelas e relacionadas. Independentemente da técnica precisa empregada, algum suporte limitado para variáveis externas pode ser encontrado com esses modelos.
Uma Breve Visão Geral de Quatro Transformadores Populares de Séries Temporais
Com uma compreensão de alto nível dos transformadores de séries temporais em mãos, vamos reservar um momento para analisar quatro modelos populares de transformadores de séries temporais de fundação:
Chronos
Chronos é uma família de modelos de previsão de séries temporais de código aberto e pré-treinados da Amazon. Esses modelos adotam uma abordagem relativamente ingênua para previsão, interpretando uma série temporal como apenas uma linguagem especializada com seus próprios padrões de relacionamento entre tokens. Apesar dessa abordagem relativamente simplista, que inclui suporte para valores ausentes, mas não para variáveis externas, a família de modelos Chronos demonstrou resultados impressionantes como uma solução de previsão de propósito geral (Figura 1).

Figura 1. Métricas de avaliação para Chronos e vários outros modelos de previsão aplicados a 27 conjuntos de dados de benchmarking (de https://github.com/amazon-science/chronos-forecasting)
TimesFM
TimesFM é um modelo de fundação de código aberto desenvolvido pelo Google Research, pré-treinado em mais de 100 bilhões de pontos de séries temporais do mundo real. Ao contrário do Chronos, o TimesFM inclui alguns mecanismos específicos de séries temporais em sua arquitetura que permitem ao usuário exercer controle granular sobre como as entradas e saídas são organizadas. Isso tem um impacto em como os padrões sazonais são detectados, mas também nos tempos de computação associados ao modelo. O TimesFM provou ser uma ferramenta de previsão de séries temporais muito poderosa e flexível (Figura 2).
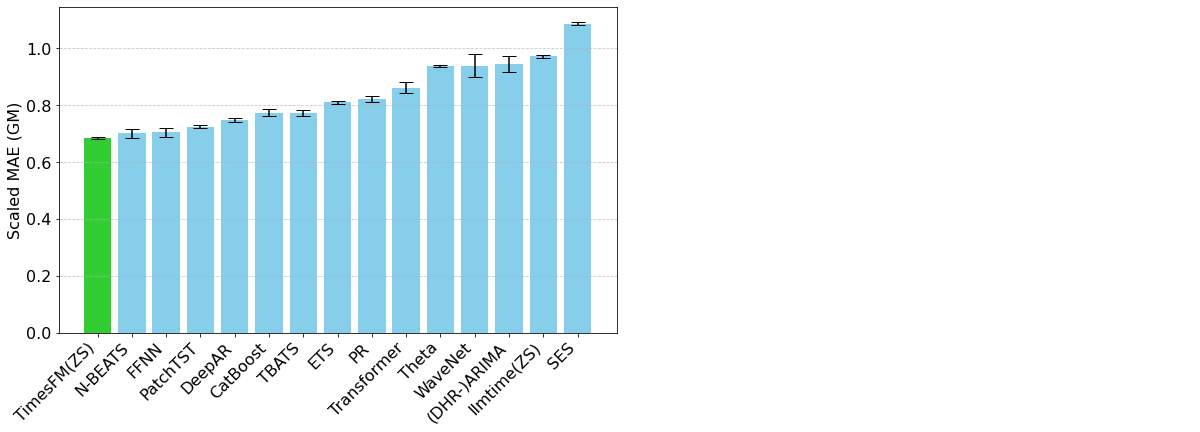
Figura 2. Métricas de avaliação para TimesFM e vários outros modelos em comparação com o conjunto de dados Monash Forecasting Archive (de https://research.google/blog/a-decoder-only-foundation-model-for-time-series-forecasting/)
Moirai
Moirai, desenvolvido pela Salesforce AI Research, é outro modelo fundamental de código aberto para previsão de séries temporais. Treinado com "27 bilhões de observações abrangendo 9 domínios distintos", Moirai é apresentado como um previsor universal capaz de suportar valores ausentes e variáveis externas. Tamanhos de patch variáveis permitem que as organizações ajustem o modelo aos padrões sazonais em seus conjuntos de dados e, quando aplicados corretamente, demonstraram ter um bom desempenho em comparação com outros modelos (Figura 3).

Figura 3. Métricas de avaliação para Moirai e vários outros modelos em comparação com o Monash Time Series Forecasting Benchmark (de https://blog.salesforceairesearch.com/moirai/)
TimeGPT
TimeGPT é um modelo proprietário com suporte para variáveis externas (exógenas), mas não para valores ausentes. Focado na facilidade de uso, o TimeGPT é hospedado através de uma API pública que permite às organizações gerar previsões com apenas uma linha de código. Ao comparar o modelo com 300.000 séries exclusivas em diferentes níveis de granularidade temporal, o modelo demonstrou produzir resultados impressionantes com latência de previsão muito baixa (Figura 4).
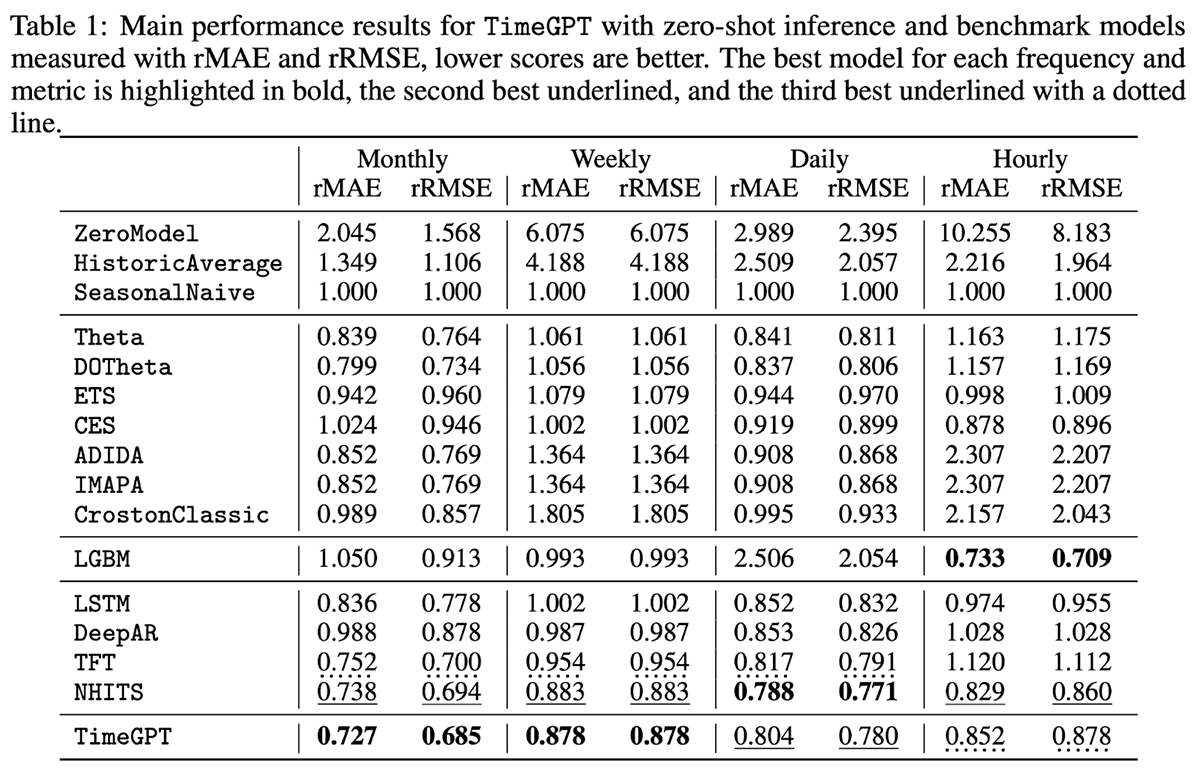
Figura 4. Métricas de avaliação para TimeGPT e vários outros modelos em comparação com 300.000 séries exclusivas (de https://arxiv.org/pdf/2310.03589)
Começando com Previsão Transformer no Databricks
Com tantas opções de modelos e mais por vir, a principal questão para a maioria das organizações é: como começar a avaliar esses modelos usando seus próprios dados proprietários? Assim como em qualquer outra abordagem de previsão, as organizações que usam modelos de previsão de séries temporais devem apresentar seus dados históricos ao modelo para criar previsões, e essas previsões devem ser cuidadosamente avaliadas e, eventualmente, implantadas em sistemas downstream para torná-las acionáveis.
Devido à escalabilidade do Databricks e ao uso eficiente de recursos na nuvem, muitas organizações o utilizam há muito tempo como base para seu trabalho de previsão, produzindo dezenas de milhões de previsões diariamente e com frequência ainda maior para executar suas operações comerciais. A introdução de uma nova classe de modelos de previsão não altera a natureza desse trabalho, apenas oferece a essas organizações mais opções para realizá-lo dentro desse ambiente.
Isso não quer dizer que não existam algumas novidades com esses modelos. Construídos em uma arquitetura de rede neural profunda, muitos desses modelos funcionam melhor quando empregados em uma GPU e, no caso do TimeGPT, eles podem exigir chamadas de API para uma infraestrutura externa como parte do processo de geração de previsões. Mas, fundamentalmente, o padrão de armazenar os dados de séries temporais de uma organização, apresentar esses dados a um modelo e capturar a saída em uma tabela consultável permanece inalterado.
Para ajudar as organizações a entender como elas podem usar esses modelos dentro de um ambiente Databricks, reunimos uma série de notebooks demonstrando como as previsões podem ser geradas com cada um dos quatro modelos descritos acima. Os profissionais podem baixar gratuitamente esses notebooks e utilizá-los em seu ambiente Databricks para se familiarizarem com seu uso. O código apresentado pode então ser adaptado para outros modelos semelhantes, fornecendo às organizações que usam o Databricks como base para seus esforços de previsão opções adicionais para usar IA generativa em seus processos de planejamento de recursos.
Comece hoje mesmo com o Databricks para modelagem de previsão com esta série de notebooks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.