Expandindo as Fronteiras para Agentes de Dados com Genie
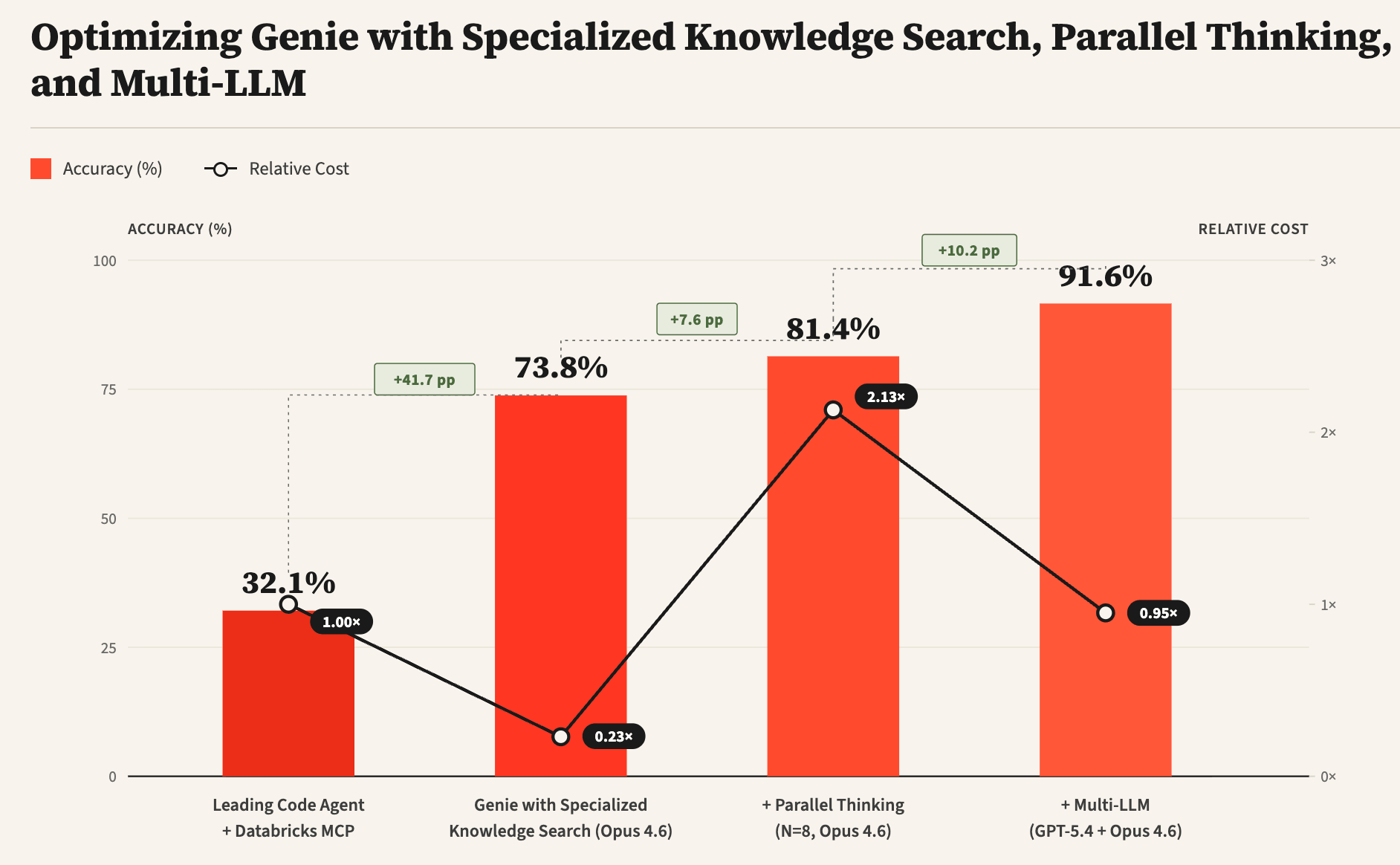
Genie é o agente de dados de ponta da Databricks, projetado para responder a perguntas complexas sobre dados corporativos, consistindo em fontes de dados estruturadas (tabelas, dashboards, notebooks, etc.) e não estruturadas (arquivos do workspace, Google Drive, Sharepoint, etc.). Este blog descreve alguns dos desafios únicos enfrentados por agentes de dados e introduz técnicas para abordá-los, incluindo o uso de pesquisa de conhecimento especializada, pensamento paralelo e designs Multi-LLM. A partir de nossos experimentos em um benchmark interno de tarefas de análise de dados do mundo real, observamos que essas técnicas podem melhorar significativamente a precisão geral do Genie em comparação com um agente de codificação líder (de 32% para mais de 90%), ao mesmo tempo em que reduzem significativamente os custos e a latência.
Principais Desafios para Agentes de Dados
Agentes de codificação demonstraram que um LLM poderoso pode fazer coisas incríveis autonomamente quando equipado com ferramentas que o ajudam a entender o contexto do código. Enquanto os agentes de codificação operam efetivamente em ambientes estáticos e determinísticos, como o sistema de arquivos de um disco, agentes de *dados* introduzem um paradigma totalmente novo. Agentes de dados trabalham dentro de um lakehouse de dados dinâmico e em constante evolução, que abrange uma riqueza de contexto semântico em centenas de milhares de tabelas, notebooks, dashboards e documentos.
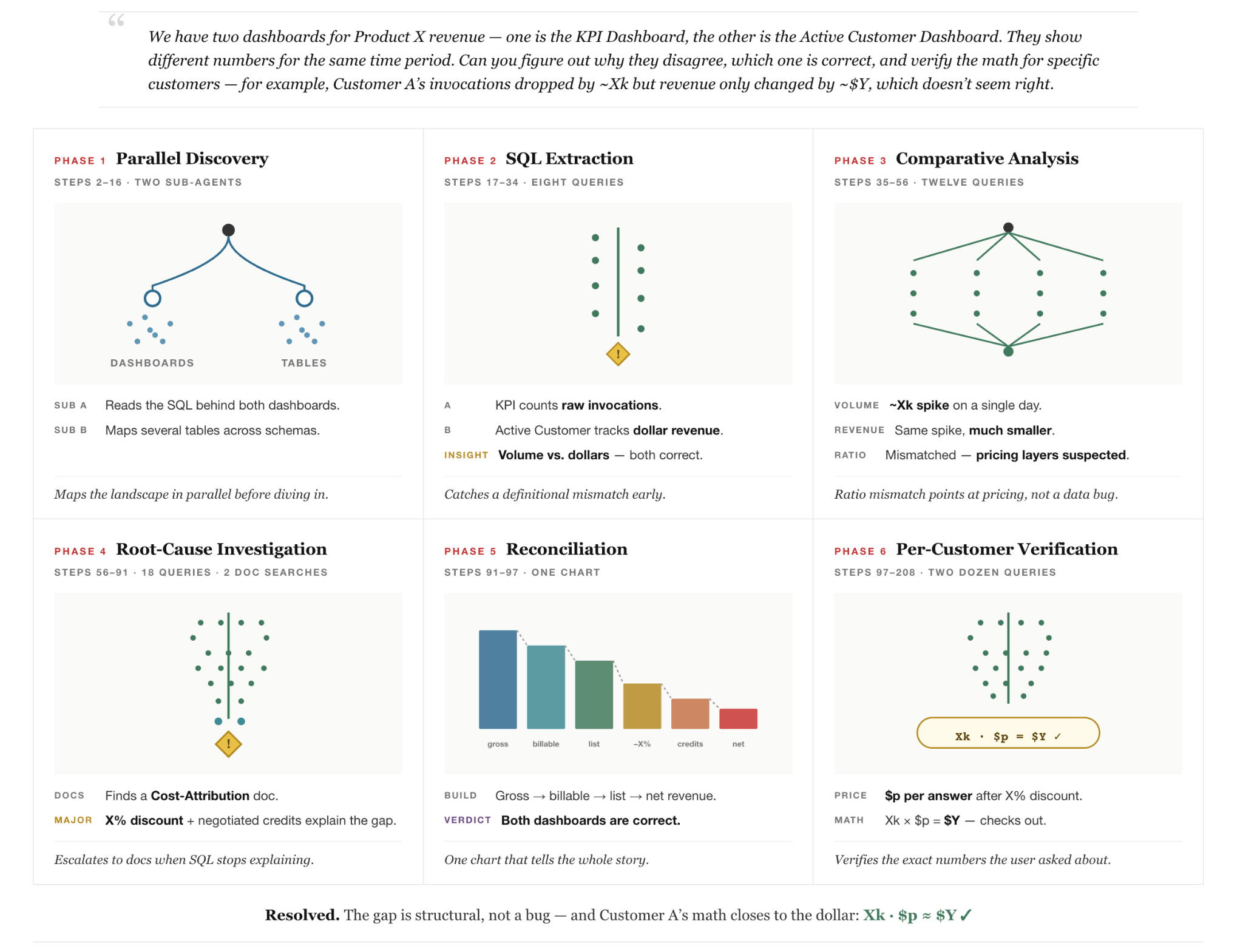
Por exemplo, considere uma consulta real (anonimizada) feita por um usuário interno na Figura 2: o usuário percebe que dois dashboards corporativos que relatam a receita do mesmo produto mostram picos contraditórios em datas diferentes e pede ao agente para explicar o porquê. Essa pergunta razoável é enganosamente difícil porque nenhuma fonte de dados única contém a resposta e a resolução da pergunta requer descoberta entre sistemas em tabelas, documentos internos e dashboards, e raciocínio sobre como os relatórios de vários dias são configurados. Além disso, requer que o agente investigue detalhes de preços corporativos para encontrar taxas de contrato. Finalmente, requer que o agente tenha a capacidade de se corrigir automaticamente quando cálculos intermediários revelarem suposições iniciais incorretas. A figura mostra como o agente consegue resolver a tarefa com sucesso, procedendo em diferentes fases: (1) descoberta paralela de dados multiagentes, (2) investigação de dados, (3) loop de autocorreção e (4) verificação.
Comparado aos Agentes de Codificação, os Agentes de Dados têm três desafios únicos principais:
- Escala de Descoberta de Dados: Encontrar as fontes de dados corretas para responder à consulta do usuário é um dos maiores desafios, com clientes corporativos tendo milhões de fontes estruturadas e não estruturadas (como tabelas, dashboards e documentos), uma escala que quebra métodos de busca convencionais.
- Determinação do Conhecimento de Negócios "Fonte da Verdade": Responder a perguntas de negócios requer conhecimento profundo e específico extraído de muitas fontes (por exemplo, metadados de tabelas, documentos da empresa, mensagens internas) que muitas vezes estão desatualizadas, contraditórias ou substituídas, forçando o agente a determinar as informações mais autoritativas.
- Falta de Testes Verificáveis: Ao contrário dos agentes de codificação que podem usar testes determinísticos e verificáveis para refinar iterativamente o código, os agentes de dados não têm testes correspondentes porque a "especificação" é apenas a consulta de alto nível do usuário, sem uma noção da resposta correta esperada. Além disso, as consultas podem nem sempre ser respondíveis devido à incompletude dos dados, e é importante que os agentes de dados sejam capazes de identificar esses casos e comunicá-los de volta aos usuários.
Principais Avanços Técnicos
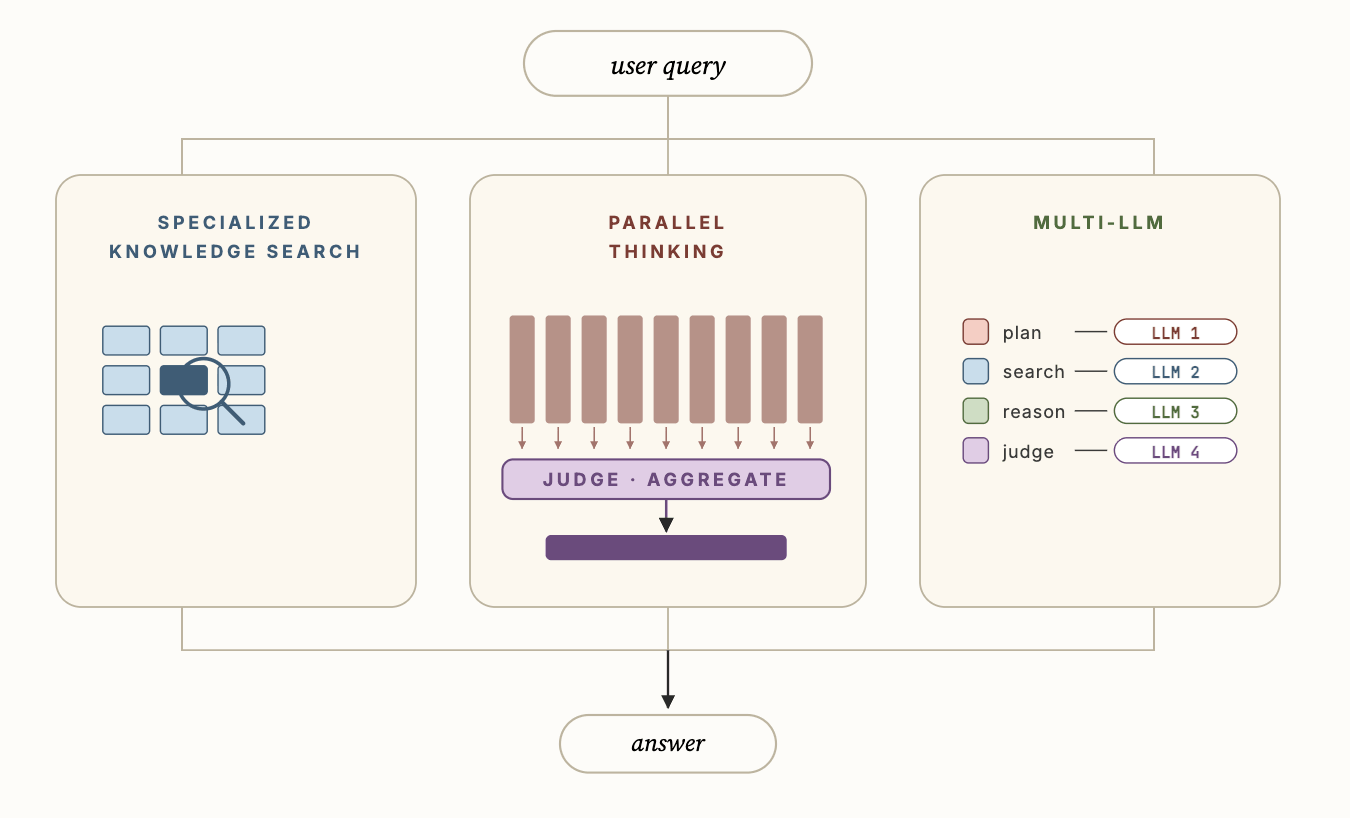
A Figura 3 mostra algumas das principais inovações técnicas no Genie que permitem que ele tenha um desempenho significativamente melhor do que agentes de codificação genéricos, nomeadamente: i) Pesquisa de Conhecimento Especializado, ii) Pensamento Paralelo e iii) Multi-LLM. A pesquisa de conhecimento especializado usa dados contextuais semânticos para fundamentar os subagentes de descoberta de ativos e melhorar significativamente a qualidade da pesquisa. O pensamento paralelo permite que o agente amostre múltiplas trajetórias diferentes e, em seguida, agregue os resultados de várias trajetórias para calcular a resposta final. Finalmente, o Multi-LLM permite que o agente use diferentes LLMs para cada um dos subagentes, juntamente com seus prompts otimizados, para melhorar ainda mais a precisão geral e a latência.
Pesquisa de Conhecimento Especializado
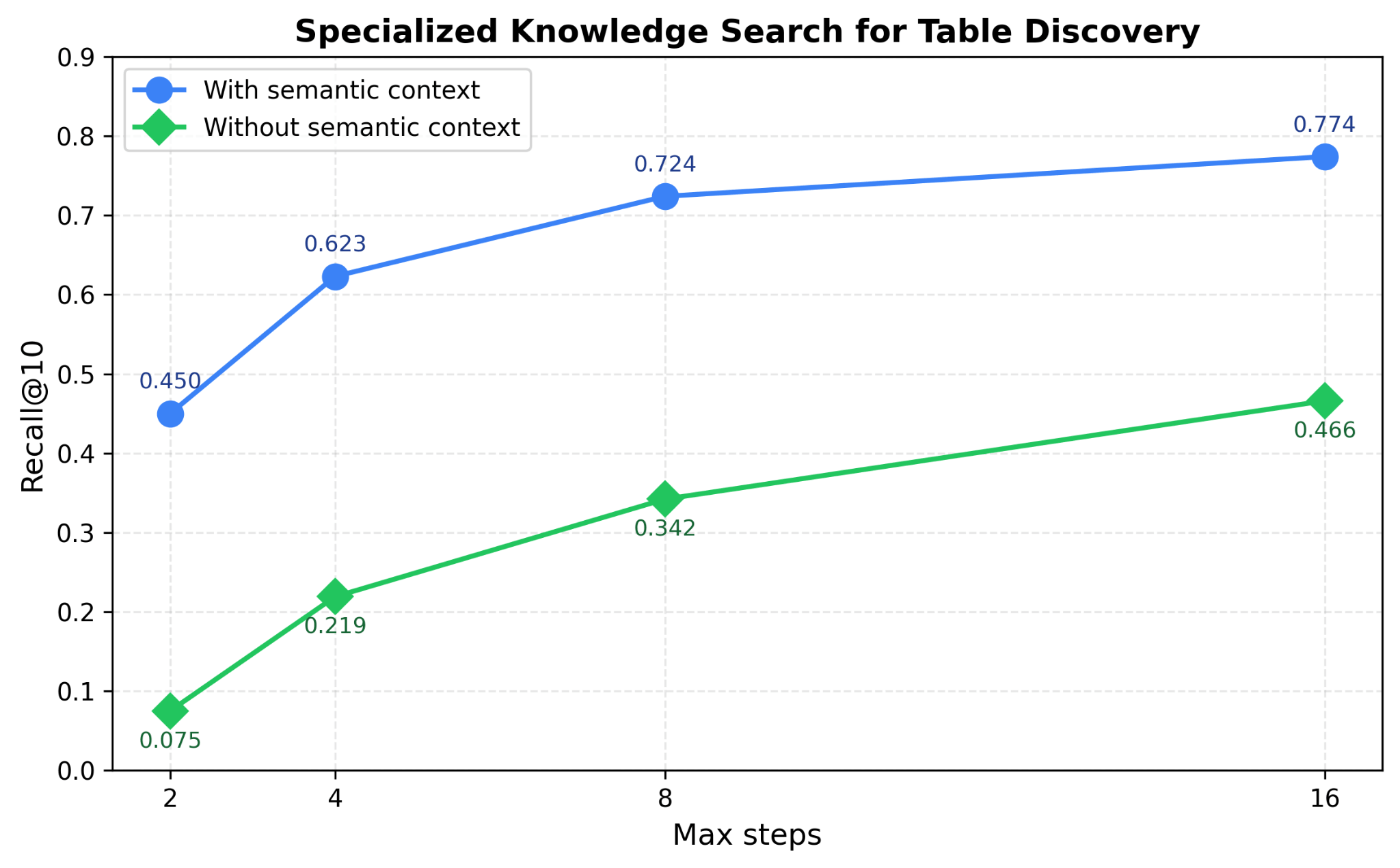
O Genie usa os ativos de dados existentes, como tabelas do workspace, notebooks, dashboards, documentos e arquivos, para derivar um rico contexto corporativo semântico e, em seguida, usa esse contexto para construir um índice de pesquisa. Ele usa múltiplos índices de pesquisa em paralelo, juntamente com sinais de metadados ricos, para descobrir eficientemente os ativos mais relevantes para uma consulta do usuário. A Figura 4 demonstra como alavancar a pesquisa de conhecimento especializado ajuda o Genie a melhorar o desempenho da pesquisa de tabelas em até 40% em nossos benchmarks de descoberta de tabelas.
Pensamento Paralelo
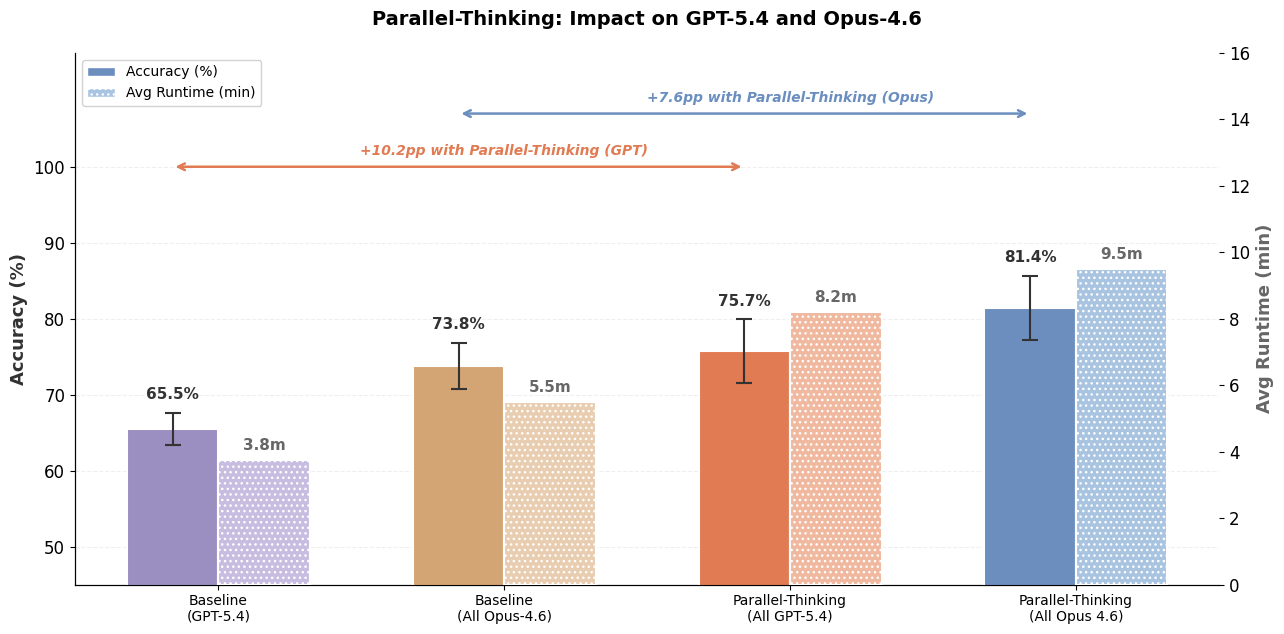
Diferentemente das tarefas de engenharia de software, onde agentes de codificação podem primeiro escrever testes para verificar a funcionalidade desejada e depois iterar na geração de código até que os testes passem, as consultas de dados abertas não possuem testes unitários correspondentes. Na ausência de testes, torna-se desafiador para os agentes de dados saber se a resposta gerada está correta ou precisa de mais refinamento. Para abordar esse desafio, aproveitamos o pensamento paralelo, amostrando múltiplas trajetórias e agregando informações relevantes entre as trajetórias para calcular a resposta final. A Figura 5 mostra como o pensamento paralelo pode melhorar significativamente a precisão da resposta, embora com alguma latência e custos de token adicionais. Além disso, como mostrado na Figura 1, a combinação de Multi-LLM e otimizações adicionais pode reduzir significativamente ainda mais os custos e a latência.
Multi-LLM
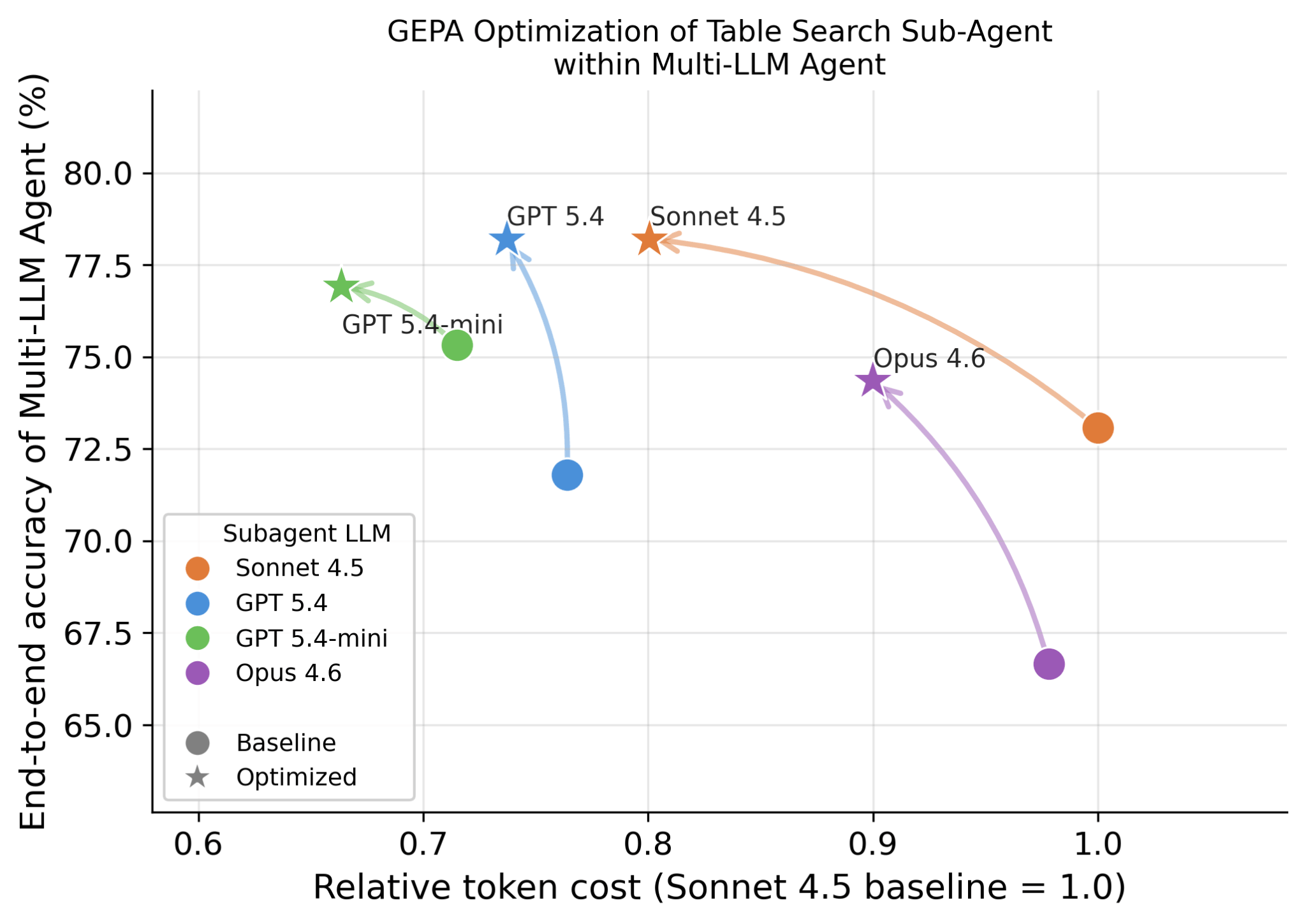
Um dos principais avanços técnicos no Genie é a capacidade de alavancar diferentes LLMs para diferentes subagentes, pois observamos que diferentes LLMs são bons em capacidades complementares. Por exemplo, ele pode usar um LLM diferente para a fase de planejamento, um LLM diferente para vários subagentes de pesquisa, um diferente para geração de código e juízes. Com a plataforma Databricks, é fácil experimentar qualquer um dos modelos de ponta (incluindo Opus, GPT e Gemini), modelos de código aberto, bem como modelos treinados personalizados. Além da precisão, também observamos que diferentes LLMs resultam em características de latência e custo muito diferentes. A Figura 6 mostra como diferentes LLMs se comportam em tarefas de pesquisa de tabelas e como a precisão e o custo correspondentes podem ser ainda mais otimizados usando métodos como GEPA.
Conclusão
Embora a codificação e a análise de dados compartilhem muitas semelhanças conceituais, a natureza dinâmica dos sistemas de dados corporativos cria desafios únicos. Os agentes de dados precisam descobrir eficientemente os ativos corretos em um grande contexto corporativo, determinar a “verdade” em um ambiente ambíguo e escrever código e consultas eficientes para responder corretamente às perguntas dos usuários. Desenvolvemos várias abordagens inovadoras para resolver esses problemas, como pesquisa especializada de conhecimento para alavancar ricas informações semânticas e múltiplos sinais de metadados, Multi-LLM para alavancar diferentes LLMs com prompts otimizados usando GEPA e pensamento paralelo para melhorar ainda mais a precisão geral. A adição dessas abordagens ao Genie o ajuda a ter um desempenho significativamente melhor do que os principais agentes de codificação nas tarefas de benchmark. Ainda há muitas perguntas desafiadoras em aberto para explorar, e nunca houve um momento mais emocionante para explorar pesquisas nesta área de construção de agentes de dados de última geração para empresas.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.