Como ler tabelas do Unity Catalog no Snowflake em 3 passos fáceis
O Unity Catalog agora funciona com Snowflake, Dremio, Starburst, EMR e mais - para ajudar você a unificar dados e IA
por Aniruth Narayanan, Randy Pitcher, Susan Pierce e Ryan Johnson
Aprenda a se conectar às APIs REST Iceberg do Unity Catalog a partir do Snowflake para ler um arquivo de dados de origem única como Iceberg.
Atualização: Este blog foi atualizado para refletir o suporte do Snowflake para credenciais fornecidas pelo catálogo.
A Databricks foi pioneira na arquitetura aberta de data lakehouse e tem estado na vanguarda da interoperabilidade de formatos. Estamos animados em ver mais plataformas adotando a arquitetura lakehouse e começando a abraçar formatos e padrões interoperáveis. A interoperabilidade permite que os clientes reduzam a duplicação cara de dados usando uma única cópia de dados com sua escolha de ferramentas de análise e IA para suas cargas de trabalho. Em particular, um padrão comum para nossos clientes é usar o melhor desempenho/preço de ETL da Databricks para dados upstream, acessando-o de ferramentas de BI e análise, como o Snowflake.
Unity Catalog é uma solução unificada e aberta de governança para ativos de dados e IA. Um recurso chave do Unity Catalog é sua implementação das APIs Iceberg REST Catalog. Isso simplifica o uso de um leitor compatível com Iceberg sem a necessidade de atualizar manualmente o local dos metadados.
Neste post do blog, cobriremos por que o Iceberg REST Catalog é útil e apresentaremos um exemplo de como ler tabelas do Unity Catalog no Snowflake.
Observação: Esta funcionalidade está disponível em todos os provedores de nuvem. As instruções a seguir são específicas para AWS S3, mas é possível usar outras plataformas de armazenamento de objetos, como Azure Data Lake Storage (ADLS) ou Google Cloud Storage (GCS).
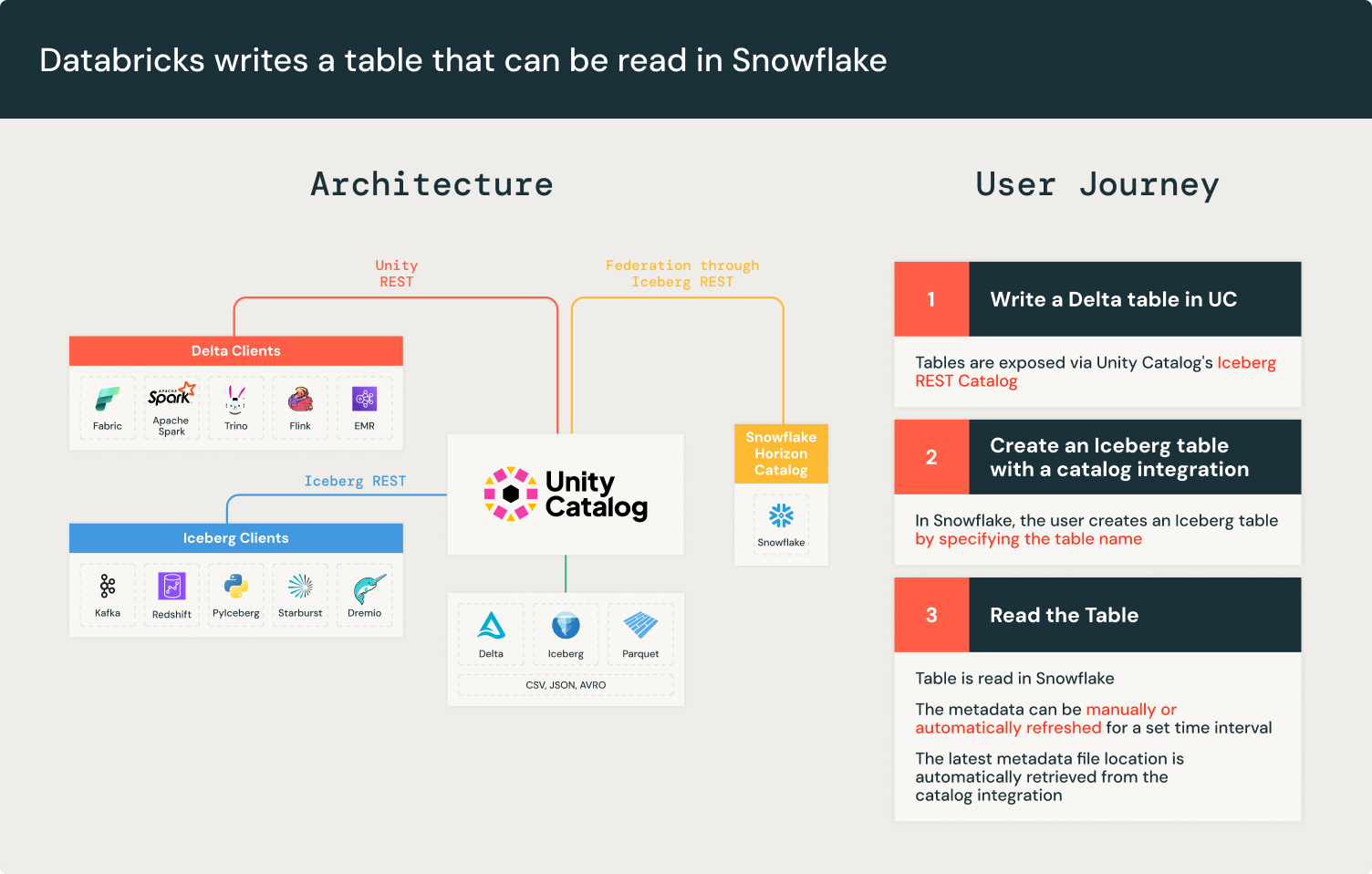
Integração de Catálogo Iceberg REST API
O Apache Iceberg™ mantém a atomicidade e a consistência criando novos arquivos de metadados para cada alteração de tabela. Isso garante que gravações incompletas não corrompam um arquivo de metadados existente. O catálogo Iceberg rastreia os novos metadados por gravação. No entanto, nem todos os mecanismos podem se conectar a todos os catálogos Iceberg, forçando os clientes a rastrear manualmente o novo local do arquivo de metadados.
O Iceberg resolve a interoperabilidade entre mecanismos e catálogos com a API Iceberg REST Catalog. O catálogo Iceberg REST é uma especificação de API padronizada e aberta, que é uma interface unificada para catálogos Iceberg, desacoplando implementações de catálogo de clientes.
O Unity Catalog implementou as APIs Iceberg REST Catalog desde o lançamento do Universal Format (UniForm) em 2023. O Unity Catalog expõe os metadados mais recentes da tabela, garantindo interoperabilidade com qualquer cliente Iceberg compatível com o Iceberg REST Catalog, como Apache Spark™, Apache Trino e Snowflake. Os endpoints do Iceberg REST Catalog do Unity Catalog permitem que sistemas externos acessem tabelas e se beneficiem de melhorias de desempenho como Liquid Clustering e Predictive Optimization, enquanto as cargas de trabalho da Databricks continuam a se beneficiar de recursos avançados do Unity Catalog como Change Data Feed. Além disso, os endpoints do Iceberg REST Catalog do Unity Catalog estendem a governança por meio de credenciais fornecidas.
A integração de catálogo REST API do Snowflake permite que você se conecte às APIs Iceberg REST do Unity Catalog para recuperar o local mais recente do arquivo de metadados. Isso significa que com o Unity Catalog, você pode ler tabelas diretamente no Snowflake.
Observação: No momento da escrita, o suporte do Snowflake ao Iceberg REST Catalog está em Visualização Pública. No entanto, as APIs Iceberg REST do Unity Catalog estão Geralmente Disponíveis.
Existem 3 etapas para criar uma integração de catálogo REST no Snowflake:
- Habilite o UniForm em uma tabela Delta Lake no Databricks para gerar metadados Iceberg
- Registre o Unity Catalog no Snowflake como seu catálogo
- Crie uma tabela Iceberg no Snowflake para que você possa consultar seus dados
Começando
Começaremos no Databricks, com nossa tabela gerenciada pelo Unity Catalog, e garantiremos que ela possa ser lida como Iceberg. Em seguida, passaremos para o Snowflake para concluir as etapas restantes.
Antes de começarmos, há alguns componentes necessários:
- Uma conta Databricks com Unity Catalog (Isso está habilitado por padrão para novos workspaces)
- Um bucket AWS S3 e privilégios IAM
- Uma conta Snowflake que possa acessar sua instância Databricks e S3
Namespaces do Unity Catalog seguem o formato nome_do_catalogo.nome_do_esquema.nome_da_tabela. No exemplo abaixo, usaremos uc_catalog_name.uc_schema_name.uc_table_name para nossa tabela Databricks.
Etapa 1: Habilitar UniForm em uma tabela Delta no Databricks
No Databricks, você pode habilitar o UniForm em uma tabela Delta Lake. Por padrão, novas tabelas são gerenciadas pelo Unity Catalog. Instruções completas estão disponíveis na documentação do UniForm, mas também estão incluídas abaixo.
Para uma nova tabela, você pode habilitar o UniForm durante a criação da tabela em seu workspace:
Se você tiver uma tabela existente, poderá fazer isso por meio de um comando ALTER TABLE:
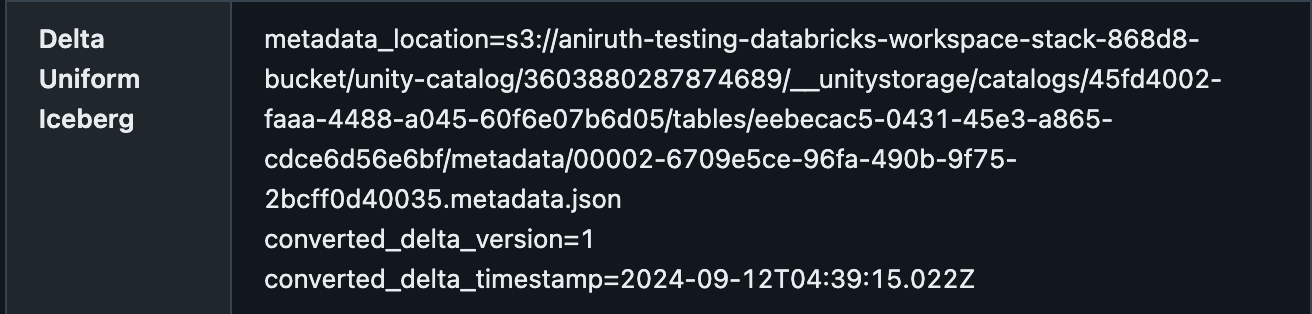
Você pode confirmar que uma tabela Delta tem o UniForm habilitado no Catalog Explorer, na guia Detalhes, com o local dos metadados. Deve ser algo assim:
Etapa 2: Registrar o Unity Catalog no Snowflake
Ainda no Databricks, crie um principal de serviço nas configurações de administrador do workspace e gere o segredo e o ID do cliente correspondentes. Em vez de um principal de serviço, você também pode autenticar com tokens pessoais para fins de depuração e teste. Recomendamos o uso de um principal de serviço para cargas de trabalho de desenvolvimento e produção. Para esta etapa, você precisará do seu <deployment-name> e dos valores para seu <client-id> e <secret> OAuth para que possa autenticar a integração no Snowflake.
Agora, mude para sua conta Snowflake.
Observação: Existem algumas diferenças de nomenclatura entre Databricks e Snowflake que podem ser confusas:
- Um “catálogo” no Databricks é um “warehouse” na configuração de integração do catálogo Iceberg do Snowflake.
- Um “esquema” no Databricks é um “catalog_namespace” na integração do catálogo Iceberg do Snowflake.
Você verá no exemplo abaixo que o valor CATALOG_NAMESPACE é uc_schema_name de nossa tabela Unity Catalog.
No Snowflake, crie uma integração de catálogo para catálogos Iceberg REST. Seguindo esse processo, você criará uma integração de catálogo como abaixo:
A Integração de Catálogo REST API também habilita credenciais delegadas e atualização automática baseada em tempo.
Credenciais delegadas incluem tanto o local de armazenamento de uma tabela quanto uma credencial de acesso temporária para acessar esse local. Isso permite que os clientes acessem tabelas através do catálogo sem configurar o acesso direto do cliente ao local de armazenamento da tabela. Recomendamos o uso de credenciais delegadas para simplificar e centralizar a governança no catálogo. No exemplo acima, configuramos o Snowflake para usar as credenciais delegadas do Unity Catalog com o parâmetro ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS no objeto REST_CONFIG.
Atualmente, o Snowflake suporta apenas credenciais delegadas para tabelas no AWS S3. Para tabelas no Azure Data Lake Storage (ADLS) ou Google Cloud Storage (GCS), o Snowflake requer acesso direto ao local de armazenamento da tabela com um volume externo.
Com a atualização automática, o Snowflake consultará o local de metadados mais recente do Unity Catalog em um intervalo de tempo definido para a integração do catálogo. No entanto, a atualização automática é incompatível com a atualização manual, exigindo que os usuários esperem até o intervalo de tempo após uma atualização da tabela. O parâmetro REFRESH_INTERVAL_SECONDS configurado na integração do catálogo se aplica a todas as tabelas Iceberg do Snowflake criadas com esta integração. Ele não é personalizável por tabela.
Passo 3: Crie uma tabela Apache Iceberg™ no Snowflake
No Snowflake, crie uma tabela Iceberg com a integração de catálogo criada anteriormente para se conectar à tabela Delta Lake. Você pode escolher o nome para sua tabela Iceberg no Snowflake; ele não precisa corresponder à tabela Delta Lake no Databricks.
Observação: O mapeamento correto para CATALOG_TABLE_NAME no Snowflake é o nome da tabela Databricks. Em nosso exemplo, este é uc_table_name. Você não precisa especificar o catálogo ou o esquema nesta etapa, pois eles já foram especificados na integração do catálogo.
Opcionalmente, você pode habilitar a atualização automática usando o intervalo de tempo da integração do catálogo adicionando AUTO_REFRESH = TRUE ao comando. Observe que, se a atualização automática estiver habilitada, a atualização manual estará desabilitada.
Agora você leu com sucesso a tabela Delta Lake no Snowflake.
Finalizando: Teste a Conexão
No Databricks, atualize os dados da tabela Delta inserindo uma nova linha.
Se você habilitou a atualização automática anteriormente, a tabela será atualizada automaticamente no intervalo de tempo especificado. Se não o fez, você pode atualizar manualmente executando ALTER ICEBERG TABLE <snowflake_table_name> REFRESH.
Observação: se você habilitou a atualização automática anteriormente, não poderá executar o comando de atualização manual e precisará aguardar o intervalo de atualização automática para que a tabela seja atualizada.
Estamos entusiasmados com o suporte contínuo à arquitetura lakehouse. Os clientes não precisam mais duplicar dados, reduzindo custos e complexidade. Essa arquitetura também permite que os clientes escolham a ferramenta certa para a carga de trabalho certa.
A chave para um lakehouse aberto é armazenar seus dados em um formato aberto, como Delta Lake ou Iceberg. Formatos proprietários prendem os clientes a um motor, mas formatos abertos oferecem flexibilidade e portabilidade. Independentemente da plataforma, incentivamos os clientes a sempre possuírem seus próprios dados como o primeiro passo para a interoperabilidade. Nos próximos meses, continuaremos a criar recursos que tornem mais simples gerenciar um data lakehouse aberto com Unity Catalog.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.