Clusters Compartilhados no Unity Catalog para vencer: Apresentando Bibliotecas de Cluster, UDFs Python, Scala, Machine Learning e mais
por Jakob Mund, Stefania Leone, Martin Grund, Herman van Hövell, Andrew Li e Sven Wagner-Boysen
Temos o prazer de anunciar que você pode executar ainda mais cargas de trabalho nos clusters multiusuário altamente eficientes da Databricks, graças a novos recursos de segurança e governança no Unity Catalog. As equipes de dados agora podem desenvolver e executar cargas de trabalho SQL, Python e Scala com segurança em recursos de computação compartilhados. Com isso, a Databricks é a única plataforma do setor que oferece controle de acesso granular em computação compartilhada para cargas de trabalho Scala, Python e SQL Spark.
A partir do Databricks Runtime 13.3 LTS, você pode migrar suas cargas de trabalho para clusters compartilhados sem problemas, graças aos seguintes recursos disponíveis em clusters compartilhados:
- Bibliotecas de cluster e scripts de inicialização: Simplifique a configuração do cluster instalando bibliotecas de cluster e executando scripts de inicialização na inicialização, com segurança e governança aprimoradas para definir quem pode instalar o quê.
- Scala: Execute cargas de trabalho Scala multiusuário com segurança ao lado de Python e SQL, com isolamento completo do código do usuário entre usuários concorrentes e aplicação das permissões do Unity Catalog.
- Python e UDFs Pandas. Execute UDFs Python e Pandas (escalares) com segurança, com isolamento completo do código do usuário entre usuários concorrentes.
- Machine Learning em nó único: Execute scikit-learn, XGBoost, prophet e outras bibliotecas populares de ML usando o nó driver do Spark, e use MLflow para gerenciar o ciclo de vida de machine learning de ponta a ponta.
- Structured Streaming: Desenvolva soluções de processamento e análise de dados em tempo real usando structured streaming.
Acesso mais fácil a dados no Unity Catalog
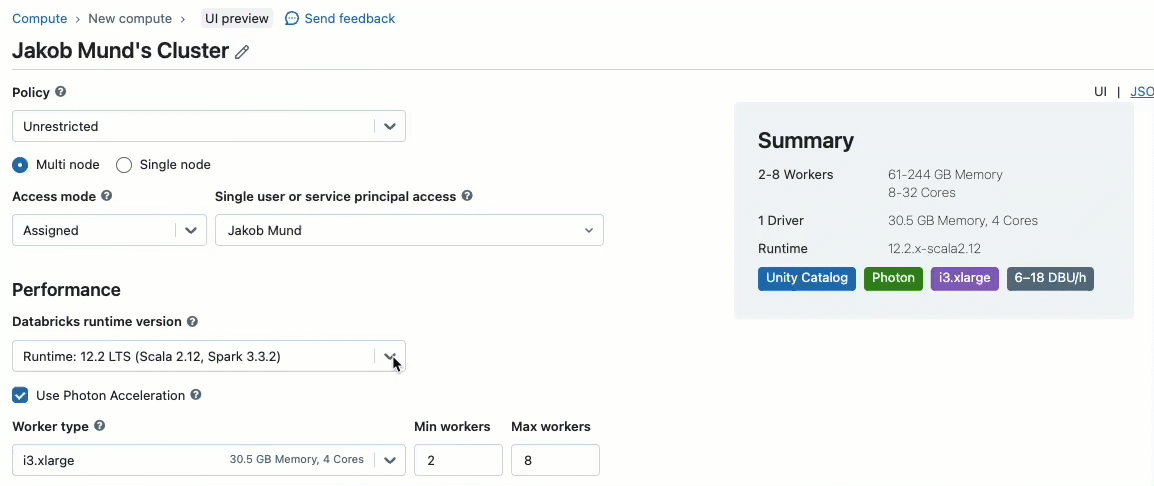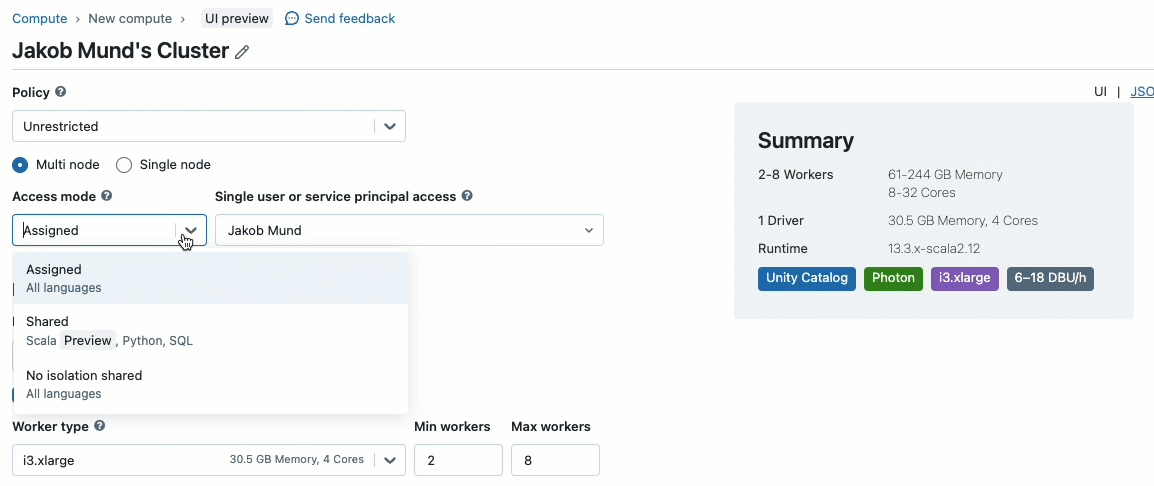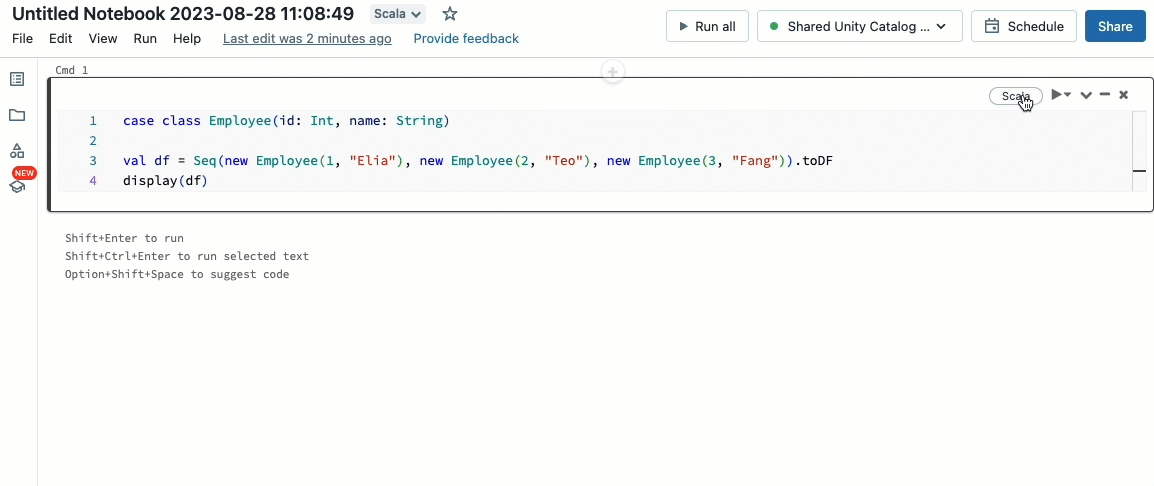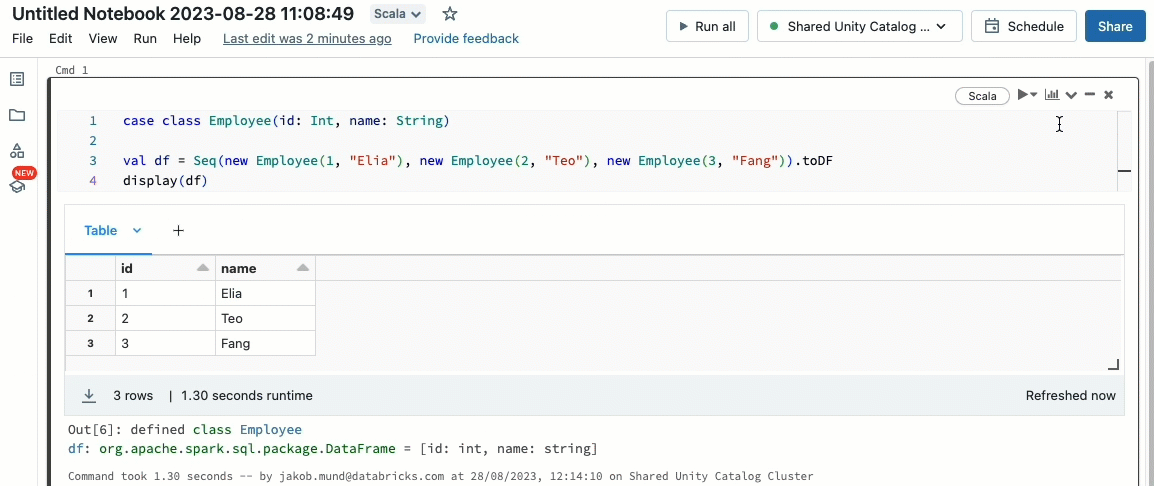
Ao criar um cluster para trabalhar com dados governados pelo Unity Catalog, você pode escolher entre dois modos de acesso:
- Clusters no modo de acesso compartilhado – ou apenas clusters compartilhados – são as opções de computação recomendadas para a maioria das cargas de trabalho. Clusters compartilhados permitem que qualquer número de usuários se conecte e execute cargas de trabalho simultaneamente no mesmo recurso de computação, permitindo economias significativas de custos, gerenciamento simplificado de clusters e governança de dados holística, incluindo controle de acesso granular. Isso é alcançado pelo isolamento de carga de trabalho do usuário do Unity Catalog, que executa qualquer código de usuário SQL, Python e Scala em total isolamento, sem acesso a recursos de nível inferior.
- Clusters no modo de acesso de usuário único são recomendados para cargas de trabalho que exigem acesso privilegiado à máquina ou que usam APIs RDD, ML distribuído, GPUs, Databricks Container Service ou R.
Enquanto os clusters de usuário único seguem a arquitetura tradicional do Spark, onde o código do usuário é executado no Spark com acesso privilegiado à máquina subjacente, os clusters compartilhados garantem o isolamento do usuário desse código. A figura abaixo ilustra a arquitetura e os primitivos de isolamento exclusivos dos clusters compartilhados: Qualquer código de usuário do lado do cliente (Python, Scala) é executado totalmente isolado e as UDFs executadas nos executores Spark são executadas em ambientes isolados. Com essa arquitetura, podemos multiplexar cargas de trabalho com segurança nos mesmos recursos de computação e oferecer uma solução colaborativa, econômica e segura ao mesmo tempo.
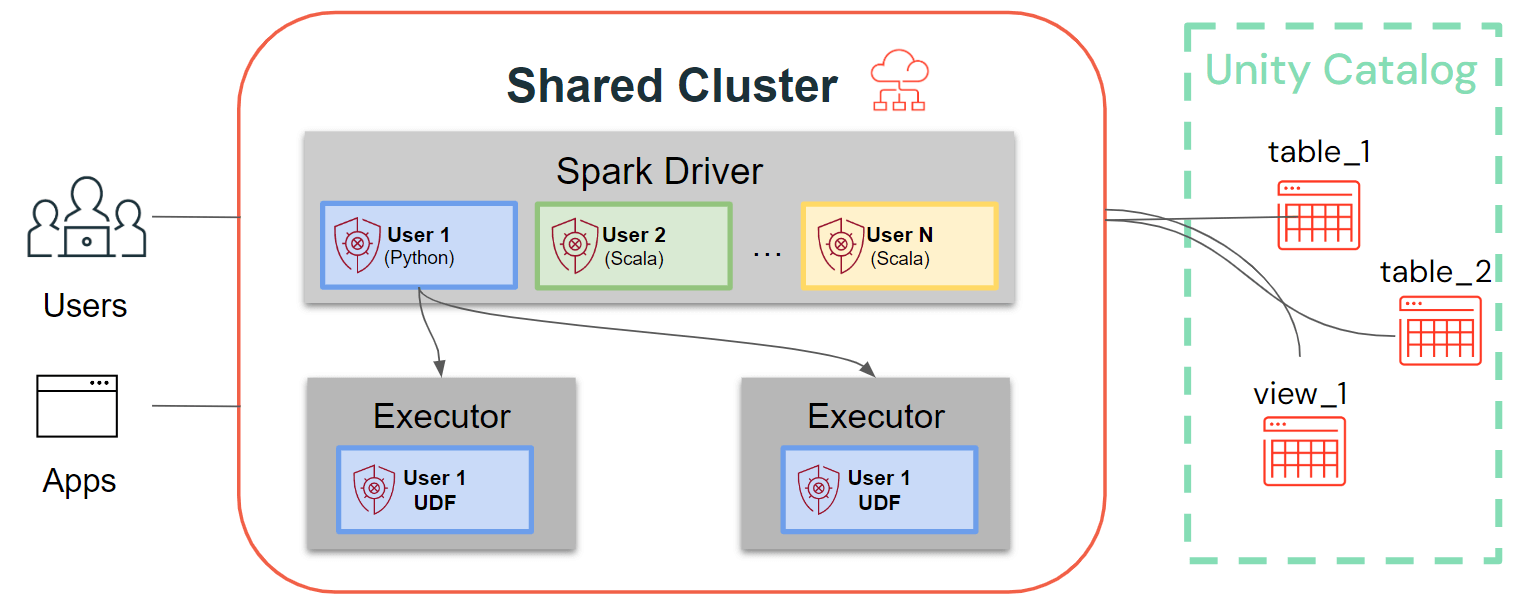
Últimos aprimoramentos para Clusters Compartilhados: Bibliotecas de Cluster, Scripts de Inicialização, UDFs Python, Scala, Suporte a ML e Streaming
Configure seu cluster compartilhado usando bibliotecas de cluster e scripts de inicialização
As bibliotecas de cluster permitem que você compartilhe e gerencie bibliotecas de forma transparente para um cluster ou até mesmo entre vários clusters, garantindo versões consistentes e reduzindo a necessidade de instalações repetitivas. Se você precisa incorporar frameworks de machine learning, conectores de banco de dados ou outros componentes essenciais em seus clusters, as bibliotecas de cluster fornecem uma solução centralizada e sem esforço, agora disponível em clusters compartilhados.
As bibliotecas podem ser instaladas a partir de volumes do Unity Catalog (AWS, Azure, GCP), arquivos do Workspace (AWS, Azure, GCP), PyPI/Maven e locais de armazenamento em nuvem, usando a Interface do Usuário ou API de Cluster existente.
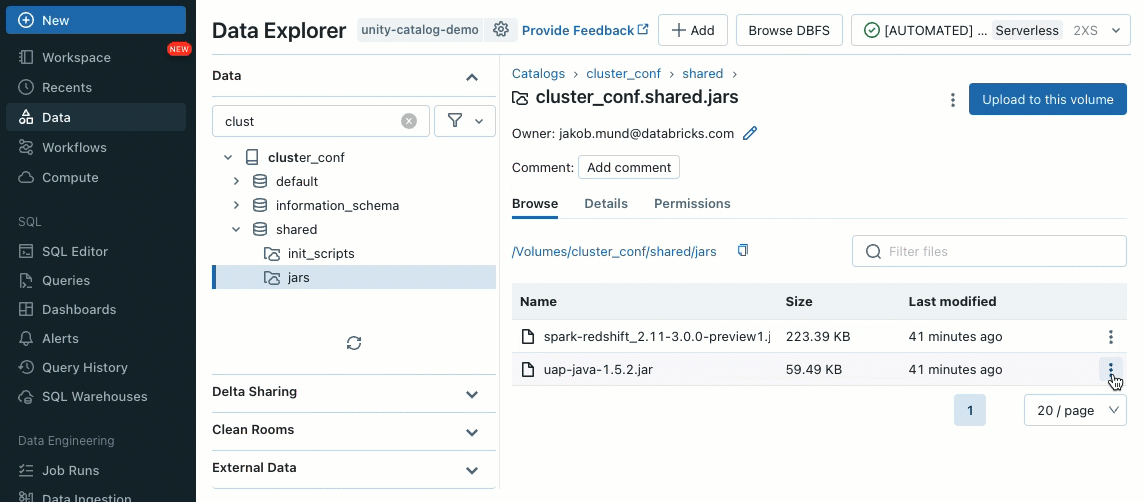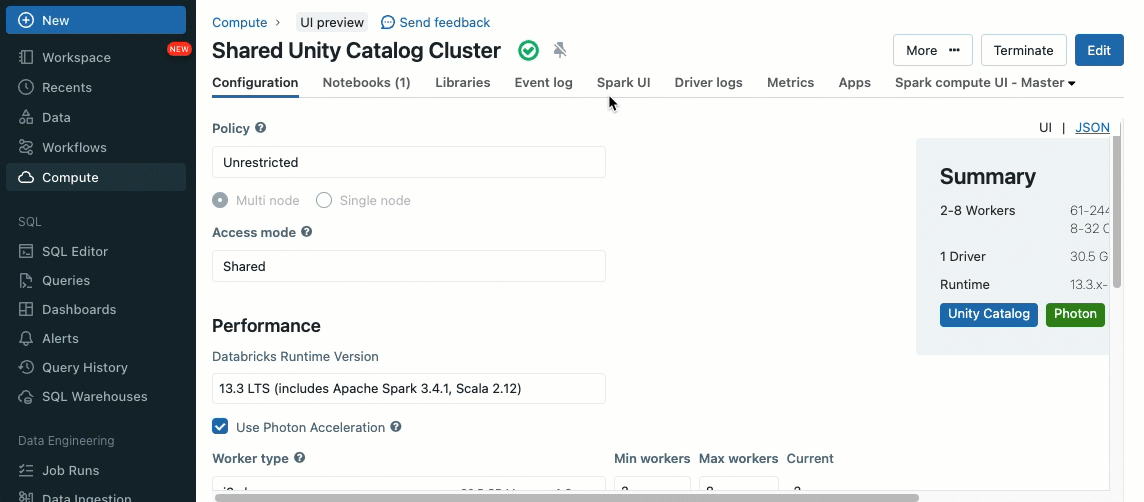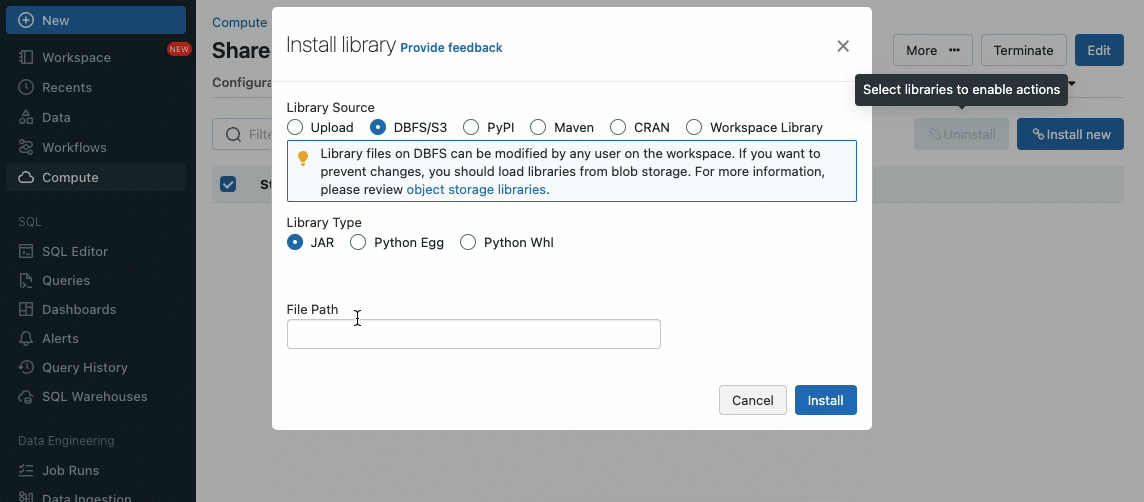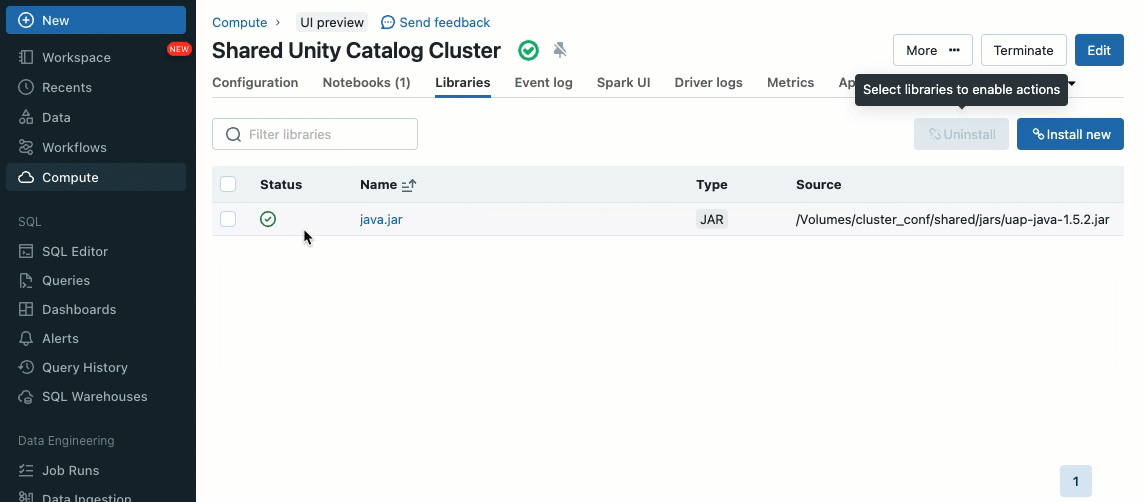
Usando scripts de inicialização, como administrador de cluster, você pode executar scripts personalizados durante o processo de criação do cluster para automatizar tarefas como configuração de mecanismos de autenticação, configurações de rede ou inicialização de fontes de dados.
Os scripts de inicialização podem ser instalados em clusters compartilhados, diretamente durante a criação do cluster ou para um conjunto de clusters usando políticas de cluster (AWS, Azure, GCP). Para máxima flexibilidade, você pode escolher se deseja usar um script de inicialização de volumes do Unity Catalog (AWS, Azure, GCP) ou armazenamento em nuvem.
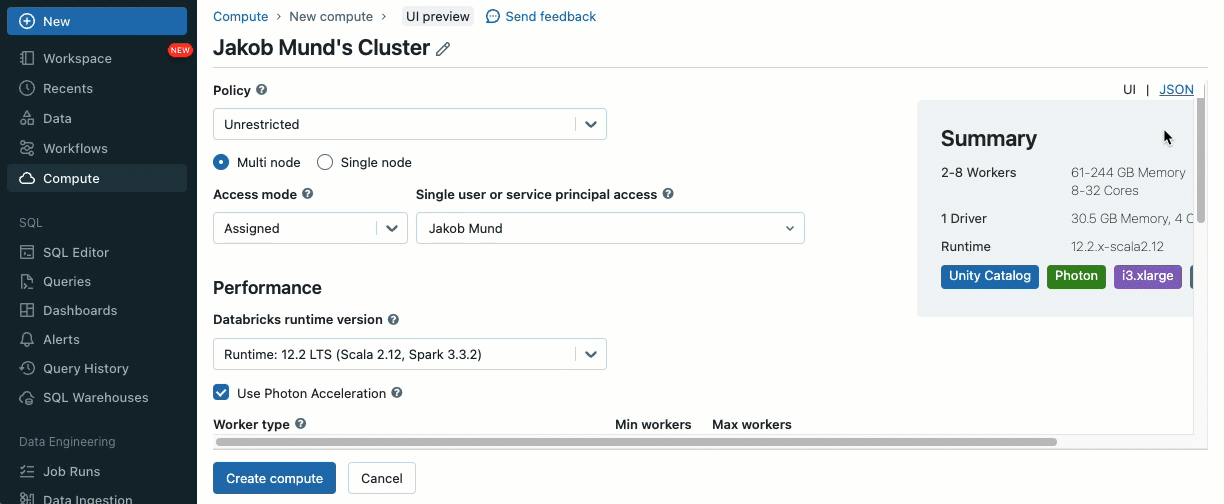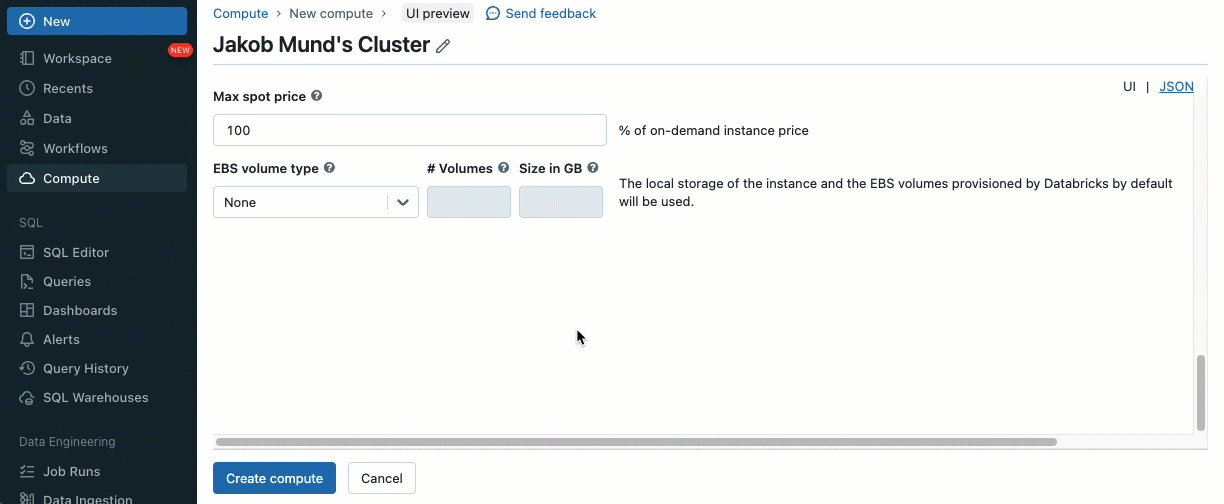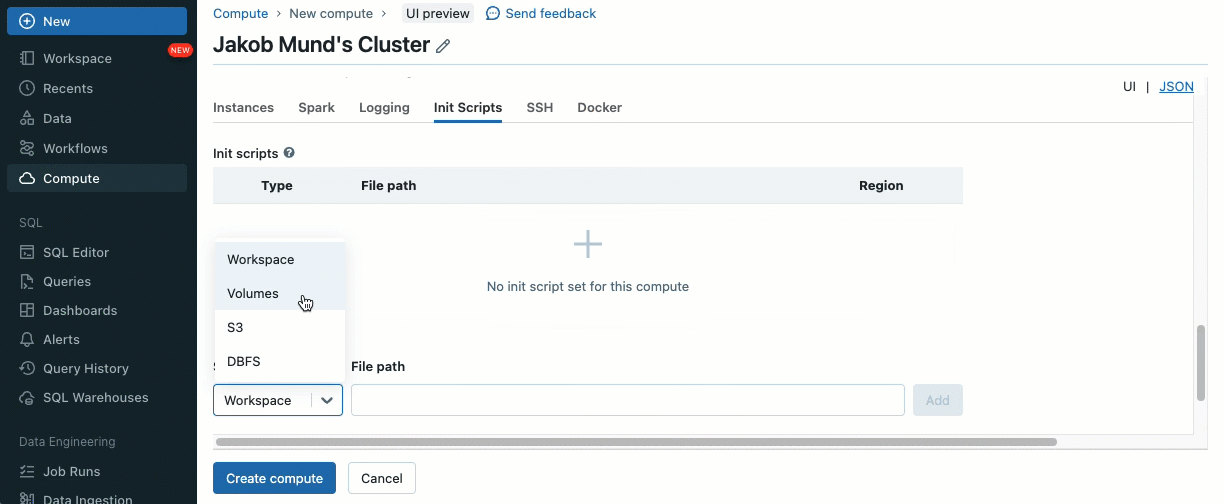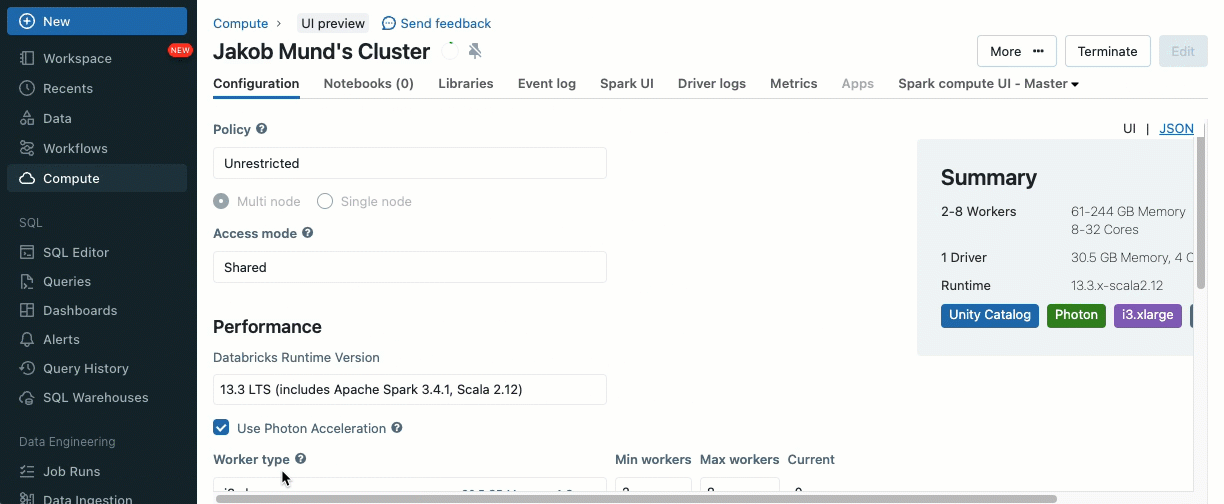
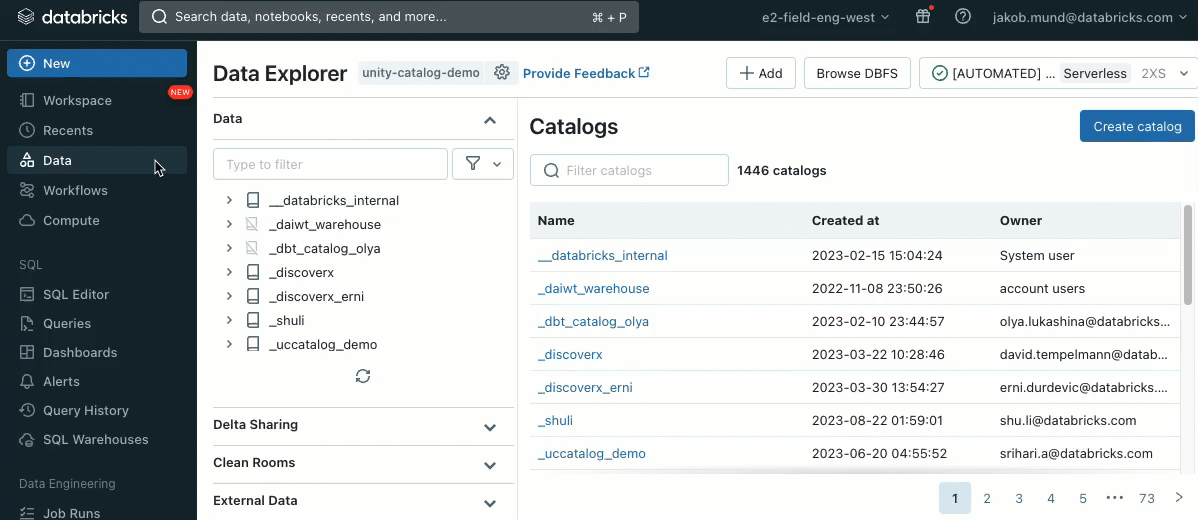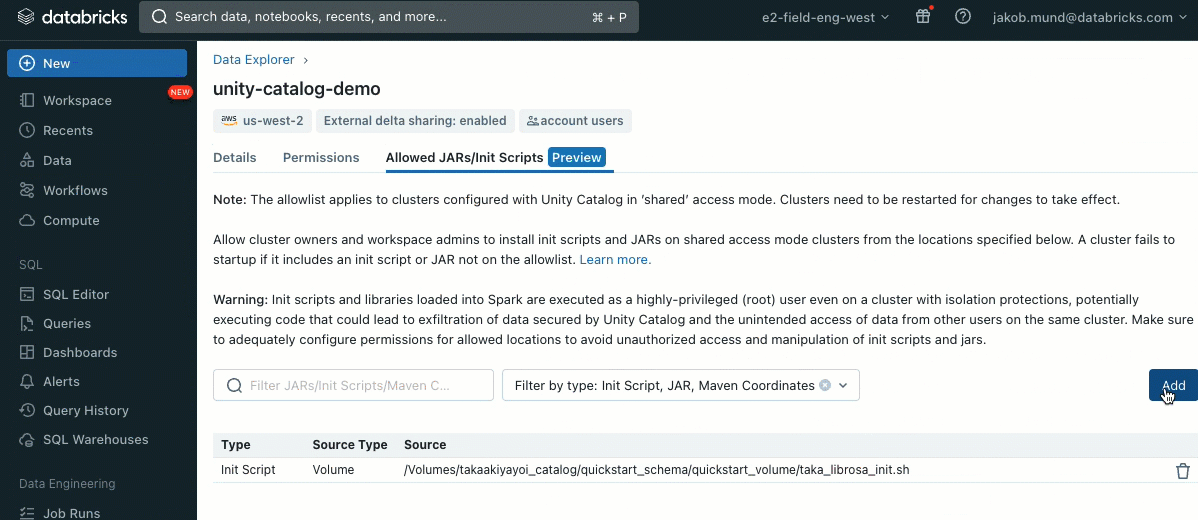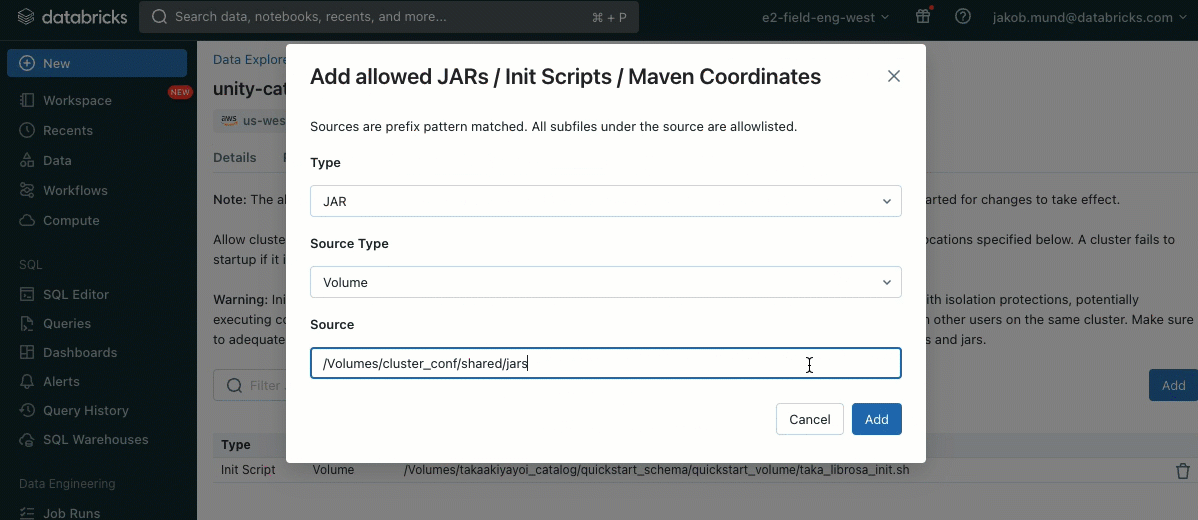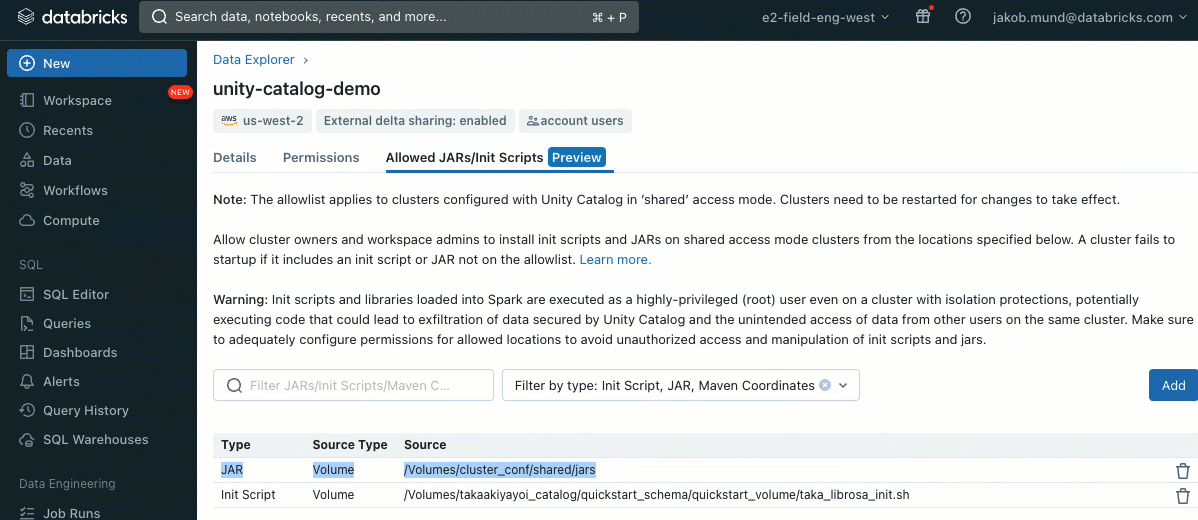
Como uma camada adicional de segurança, introduzimos uma lista de permissões (allowlist) (AWS, Azure, GCP) que governa a instalação de bibliotecas de cluster (jars) e scripts de inicialização. Isso coloca os administradores no controle do gerenciamento deles em clusters compartilhados. Para cada metastore, o administrador do metastore pode configurar os volumes e locais de armazenamento em nuvem de onde as bibliotecas (jars) e scripts de inicialização podem ser instalados, fornecendo assim um repositório centralizado de recursos confiáveis e prevenindo instalações não autorizadas. Isso permite um controle mais granular sobre as configurações do cluster e ajuda a manter a consistência nos fluxos de trabalho de dados da sua organização.
Traga suas cargas de trabalho Scala
Scala agora é suportado em clusters compartilhados governados pelo Unity Catalog. Engenheiros de dados podem alavancar a flexibilidade e o desempenho do Scala para lidar com todos os tipos de desafios de big data, colaborativamente no mesmo cluster e aproveitando o modelo de governança do Unity Catalog.
Integrar Scala ao seu fluxo de trabalho Databricks existente é muito fácil. Basta selecionar o Databricks runtime 13.3 LTS ou posterior ao criar um cluster compartilhado, e você estará pronto para escrever e executar código Scala ao lado de outras linguagens suportadas.
Aproveite Funções Definidas pelo Usuário (UDFs), Machine Learning e Structured Streaming
Isso não é tudo! Estamos entusiasmados em apresentar mais avanços revolucionários para clusters compartilhados.
Suporte para Funções Definidas pelo Usuário (UDFs) Python e Pandas: Agora você pode aproveitar o poder das UDFs Python e Pandas (escalares) também em clusters compartilhados. Basta trazer suas cargas de trabalho para clusters compartilhados sem problemas – nenhuma adaptação de código é necessária. Ao isolar a execução do código do usuário da UDF nos executores Spark em um ambiente de sandbox, os clusters compartilhados fornecem uma camada adicional de proteção para seus dados, prevenindo acesso não autorizado e possíveis violações.
Suporte para todas as bibliotecas populares de ML usando o nó driver Spark e MLflow: Se você está trabalhando com Scikit-learn, XGBoost, prophet e outras bibliotecas populares de ML, agora você pode criar, treinar e implantar modelos de machine learning diretamente em clusters compartilhados. Para instalar bibliotecas de ML para todos os usuários, você pode usar as novas bibliotecas de cluster. Com suporte integrado para MLflow (2.2.0 ou posterior), gerenciar o ciclo de vida de machine learning de ponta a ponta nunca foi tão fácil.
Structured Streaming agora também está disponível em Clusters Compartilhados governados pelo Unity Catalog. Esta adição transformadora permite o processamento e análise de dados em tempo real, revolucionando a forma como suas equipes de dados lidam com cargas de trabalho de streaming colaborativamente.
Comece hoje, mais coisas boas estão por vir
Descubra o poder do Scala, bibliotecas de cluster, UDFs Python, ML de nó único e streaming em clusters compartilhados hoje, simplesmente usando o Databricks Runtime 13.3 LTS ou superior. Consulte os guias de início rápido (AWS, Azure, GCP) para saber mais e iniciar sua jornada rumo à excelência em dados.
Nas próximas semanas e meses, continuaremos a unificar a arquitetura de computação do Unity Catalog e torná-la ainda mais simples para trabalhar com o Unity Catalog!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.