Modelo de Embedding SOTA para Fluxos de Trabalho Agentes Agora em Pré-visualização Pública
O Qwen3-Embedding-0.6B é o primeiro modelo de embedding multilíngue no Foundation Model Serving com desempenho de ponta em todas as tarefas de embedding
por Felix Zhu, Cade Daniel e Wai Wu
- O Qwen3-Embedding-0.6B agora está disponível no Model Serving, oferecendo desempenho de recuperação de ponta em um modelo compacto de 0.6B otimizado para busca vetorial e cargas de trabalho de agentes de IA.
- O primeiro modelo de embedding multilíngue no Databricks, suportando recuperação cross-lingual em mais de 100 idiomas para dados corporativos globais.
- Embeddings Matryoshka permitem compensações flexíveis de custo-desempenho, permitindo que embeddings sejam truncados de 1024 para até 32 dimensões para busca mais rápida e custos de armazenamento mais baixos.
A recuperação é a base dos sistemas modernos de IA, e a qualidade do modelo de embedding determina a eficácia com que as aplicações podem encontrar e raciocinar sobre dados corporativos. Hoje, estamos lançando o Qwen3-Embedding-0.6B no Databricks, um modelo de embedding de ponta que oferece forte desempenho de recuperação, cobertura multilíngue e implantação serverless segura.
Juntamente com o Agent Bricks e o AI Search, este modelo permite que as equipes criem agentes de IA diretamente em dados corporativos no Databricks, recuperando contexto relevante e raciocinando sobre dados governados sem mover dados para fora da plataforma.
Crie Agentes Potencializados por Recuperação com Agent Bricks
Modelos de embedding de ponta são uma base crítica para sistemas modernos de IA, permitindo que aplicações recuperem o contexto certo de grandes coleções de dados corporativos. O Qwen3-Embedding-0.6B, agora disponível no Databricks, oferece forte desempenho de recuperação para essas cargas de trabalho.
O Qwen3-Embedding-0.6B é construído sobre a poderosa base Qwen3 e vem da mesma equipe de pesquisa por trás da série GTE amplamente adotada. Com um comprimento de contexto máximo de 32 mil tokens, este modelo oferece flexibilidade incrível para dividir documentos em vários tamanhos diferentes. Além disso, seu design instrucional permite que os desenvolvedores adaptem o modelo a tarefas e idiomas específicos com um prompt simples, geralmente aumentando o desempenho de recuperação em 1–5%.
No Databricks, isso pode ser combinado com Agent Bricks e AI Search para criar agentes de IA potencializados por recuperação diretamente em dados corporativos. As equipes podem indexar documentos com AI Search e recuperar contexto relevante durante a execução do agente, fundamentando os agentes em dados governados armazenados no Databricks.
Como Este Modelo de Embedding Melhora Agentes de IA no Databricks
O Qwen3-Embedding-0.6B oferece qualidade de ponta para seu tamanho. Nos leaderboards MTEB multilíngue e inglês v2, ele supera a maioria dos outros modelos de classe 0.6B e supera modelos de embedding de ponta da OpenAI e Cohere, enquanto rivaliza com modelos muito maiores de 7B+. Isso significa que você pode alcançar desempenho de recuperação de ponta sem a latência e o custo de modelos muito grandes.
O modelo também oferece controle granular sobre custo e recall por meio do Matryoshka Representation Learning (MRL), que concentra as informações mais importantes nas primeiras dimensões do vetor. Isso permite que os embeddings sejam truncados com segurança para armazenamento mais barato e pesquisa mais rápida, preservando a maior parte do sinal. Com o Qwen3-Embedding-0.6B, você pode escolher qualquer tamanho de embedding de 32 a 1024 dimensões no momento da solicitação — usando vetores menores para índices de recall em larga escala e vetores de tamanho completo para reclassificação de maior precisão.
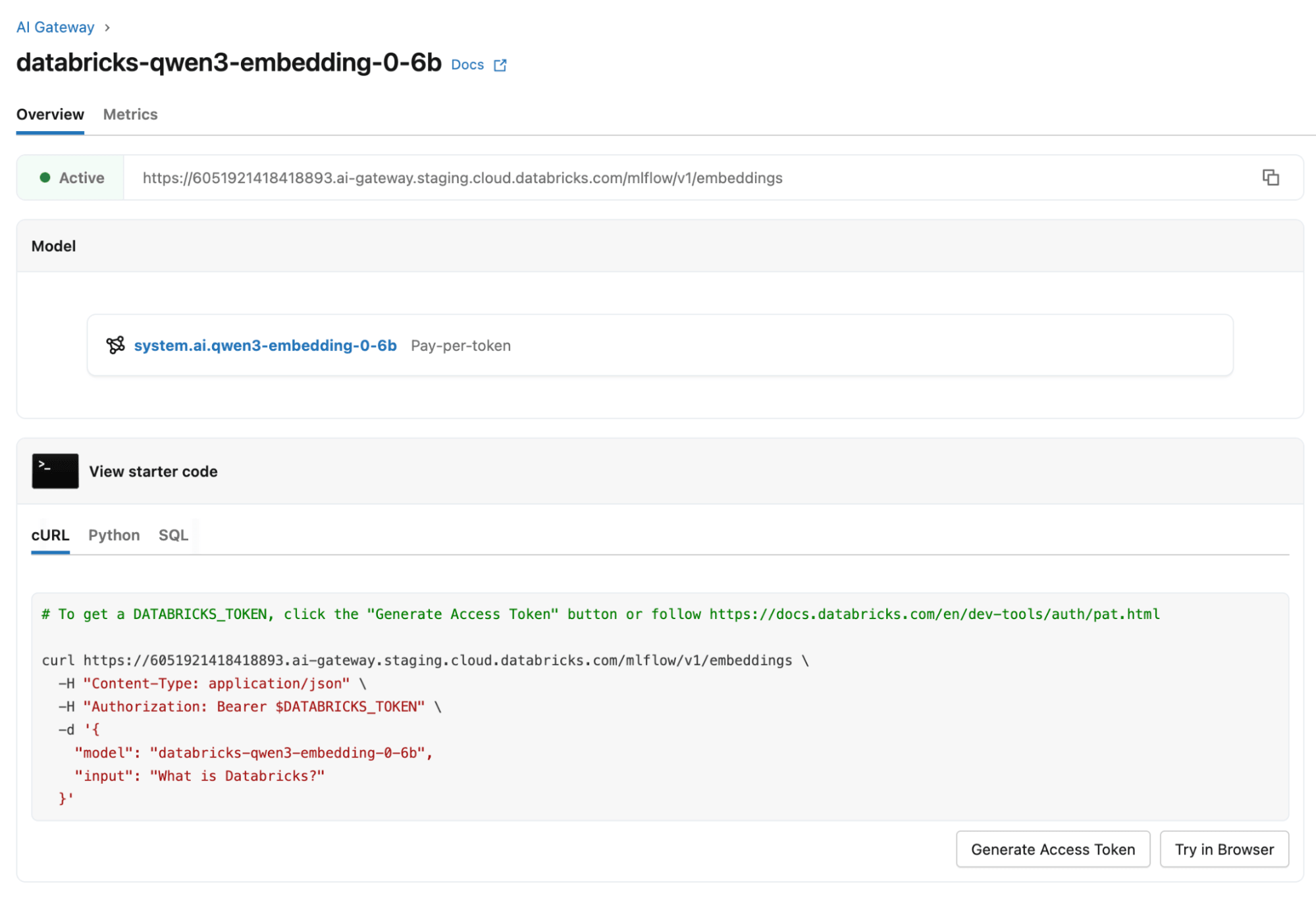
Para usar este recurso com databricks-qwen3-embedding-0-6b, defina o campo opcional dimensions em sua solicitação da API REST de Embeddings para o tamanho de saída desejado (uma potência de dois entre 32 e 1024). Consulte a documentação da API REST de Modelos Fundamentais para obter detalhes.
Multilíngue por Design
O Qwen3-Embedding-0.6B é o primeiro modelo de embedding multilíngue hospedado pelo Databricks, projetado para cargas de trabalho globais desde o início. Enquanto muitos modelos de embedding são focados em inglês com suporte multilíngue limitado, o Qwen3-Embedding-0.6B herda ampla cobertura de idiomas do modelo base Qwen3, que foi pré-treinado em texto abrangendo mais de 100 idiomas.
Isso permite um forte desempenho não apenas para recuperação em inglês, mas também para tarefas multilíngues e cross-linguais. As aplicações podem pesquisar em um idioma e recuperar resultados em outro, ou dar suporte a conjuntos de dados de idiomas mistos e recuperação de código em várias linguagens de programação.
Implantação Serverless Segura
Como outros modelos fundamentais hospedados pelo Databricks, o Qwen3-Embedding-0.6B é executado em GPUs serverless seguras e totalmente gerenciadas dentro da plataforma Databricks.
Simplesmente chame as APIs de Modelos Fundamentais, e o Databricks cuida do provisionamento, escalonamento automático e confiabilidade. Como o modelo é executado em infraestrutura compatível e ciente de geolocalização, você pode manter os embeddings próximos aos seus dados, respeitar os requisitos de residência de dados e integrar a recuperação diretamente com cargas de trabalho Databricks existentes.
Experimente o Qwen3-Embedding-0.6B hoje mesmo!
Se você está construindo pesquisa semântica, pipelines RAG, recuperação multilíngue ou sistemas de classificação de texto, o Qwen3-Embedding-0.6B oferece uma combinação excepcional de velocidade, eficiência e precisão de ponta. Este modelo está disponível como databricks-qwen3-embedding-0-6b em todas as nuvens em todas as regiões que suportam Foundation Model Serving, e você pode experimentar este modelo na página Databricks Serving. Ele está disponível em todas as superfícies de Model Serving: Pay-Per-Token, AI Functions (inferência em lote) e Provisioned Throughput. Você também pode selecionar este modelo para casos de uso de AI Search.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.