O que são Pipelines de ML?
Aprenda como os pipelines de aprendizado de máquina automatizam e otimizam o fluxo de trabalho, desde o pré-processamento de dados até a validação do modelo.
- Entenda o que são pipelines de aprendizado de máquina e como eles conectam pré-processamento, extração de recursos, ajuste de modelos e validação em um fluxo de trabalho unificado.
- Aprenda a diferença entre Transformers e Estimators, os dois principais tipos de estágios de pipeline.
- Explore como os Pipelines de ML do Spark permitem aprendizado de máquina escalável e distribuído com criação e ajuste nativos de pipelines.
A execução de um algoritmo de machine learning geralmente envolve uma série de tarefas, como pré-processamento, extração de recursos, ajuste de modelo e estágios de validação. Por exemplo, a classificação de documentos de texto inclui segmentação e limpeza de texto, extração de recursos e validação cruzada para treinar um modelo de classificação. Há muitas bibliotecas disponíveis para cada estágio, mas combiná-las pode ser uma tarefa assustadora, especialmente ao trabalhar com grandes conjuntos de dados. Além disso, a maioria das bibliotecas de ML não foi projetada para computação distribuída ou não oferece compatibilidade nativa com a criação e o ajuste de pipelines.
O manual de IA agêntica para empresas

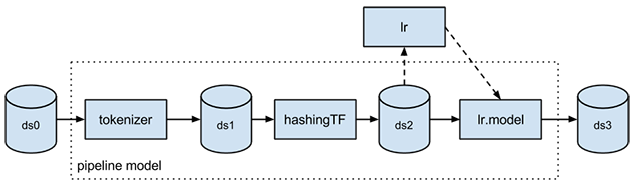
Um pipeline de ML é uma API de alto nível para MLlib no pacote “spark.ml”. Um pipeline consiste em uma sequência de estágios, podendo ser de dois tipos: Transformer e Estimator. Um Transformer recebe um conjunto de dados como entrada e produz um conjunto de dados aumentado como saída. Por exemplo, um tokenizer é um Transformer que transforma um conjunto de dados de texto em um conjunto de dados de palavras tokenizadas. Um Estimator deve primeiro ajustar um conjunto de dados de entrada para produzir um modelo, que é um Transformer que transforma o conjunto de dados de entrada. Por exemplo, a regressão logística é um Estimator que treina um conjunto de dados com rótulos e recursos para produzir um modelo de regressão logística.
Recursos adicionais
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.