O que é a Arquitetura Lambda?
Arquitetura que combina processamento em lote e em fluxo contínuo, com uma camada de lote para precisão, uma camada de velocidade para resultados em tempo real e uma camada de serviço que mescla ambas.
- A camada de lote armazena o conjunto de dados mestre em formato imutável de acréscimo único, pré-computando visualizações em lote por meio de processamento no estilo MapReduce, fornecendo resultados precisos e abrangentes, porém com latência de horas.
- A camada de velocidade processa apenas fluxos de dados recentes usando sistemas de baixa latência como Storm ou Flink, criando visualizações em tempo real que compensam o atraso da camada de lote com consistência eventual quando as visualizações em lote são atualizadas.
- A camada de serviço indexa as visualizações em lote e de velocidade, permitindo consultas ad-hoc rápidas que mesclam ambas as perspectivas, embora a complexidade da arquitetura tenha diminuído, visto que sistemas de streaming como o Apache Spark oferecem recursos tanto em lote quanto em tempo real.
O que é a arquitetura Lambda?
A arquitetura Lambda é uma forma de processar enormes quantidades de dados ("Big Data") que fornece acesso a métodos de processamento em batch e de stream com uma abordagem híbrida. A arquitetura Lambda é usada para resolver o problema do compute de funções arbitrárias. A arquitetura Lambda é composta por 3 camadas:
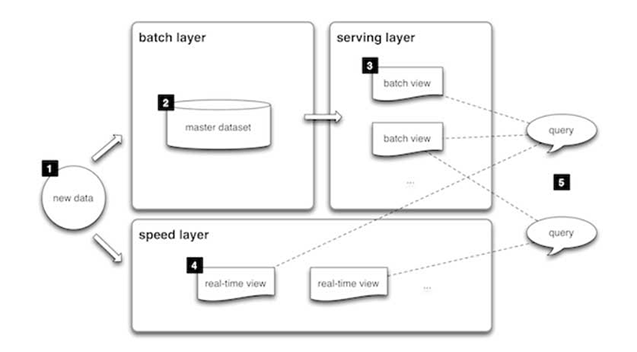
Camada em lote
Novos dados chegam continuamente, como um feed para o sistema de dados. Eles são alimentados para a camada em batch e para a camada de velocidade simultaneamente. Todos os dados são analisados de uma vez e, às vezes, corrigidos na camada de stream. Aqui, podemos encontrar muitas ETL e um data warehouse tradicional. Essa camada é construída usando uma programação pré-definida, normalmente uma ou duas vezes por dia. A camada em batch tem duas funções muito importantes:
- Gerenciar o conjunto de dados mestre
- Fazer o pré-compute das visualizações em lote.
Camada de serviço
Os resultados da camada em batch na forma de visualizações em batch e aqueles provenientes da camada de velocidade na forma de visualizações quase em tempo real são encaminhados para a camada de serviço. Essa camada indexa as visualizações em batch de forma que possam ser consultadas em baixa latência em uma base ad-hoc.
Camada de velocidade (camada de stream)
Esta camada lida com os dados que ainda não foram entregues na visualização em batch devido à latência da camada em batch. Ela também lida apenas com dados recentes para fornecer uma visão completa dos dados ao usuário, criando visualizações em tempo real.
O manual de IA agêntica para empresas

Benefícios das arquiteturas Lambda
Conheça os principais benefícios das arquiteturas Lambda:
- Sem gerenciamento de servidor: você não precisa instalar, manter ou administrar nenhum software.
- Escala flexível: sua aplicação pode ser dimensionada automaticamente ou de acordo com o ajuste da sua capacidade
- Alta disponibilidade automatizada: refere-se ao fato de que as aplicações serverless já têm disponibilidade integrada e tolerância a falhas. Representa uma garantia de que todas as solicitações receberão uma resposta informando se foram bem-sucedidas ou não.
- Agilidade nos negócios: reaja em tempo real às mudanças nos cenários de negócios/mercado
Desafios das arquiteturas Lambda
- Complexidade: as arquiteturas Lambda podem ter um alto nível de complexidade. Normalmente, os administradores devem manter duas bases de código separadas para camadas em batch e de streaming, o que pode dificultar a depuração.
Relacionado
Delta Lake: lote unificado e fonte e destino de dados de streaming
Recursos adicionais
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.