Uma História de Três APIs do Apache Spark: RDDs vs DataFrames e Datasets
Quando usá-los e por quê
por Jules Damji
De todas as maravilhas para desenvolvedores, nenhuma é mais atraente do que um conjunto de APIs que os tornam produtivos, fáceis de usar, intuitivas e expressivas. Um dos apelos do Apache Spark para desenvolvedores tem sido suas APIs fáceis de usar para operar em grandes conjuntos de dados, em várias linguagens: Scala, Java, Python e R.
Neste blog, explorarei três conjuntos de APIs — RDDs, DataFrames e Datasets — disponíveis no Apache Spark 2.2 e versões posteriores; por que e quando usar cada conjunto; descreverei seus benefícios de desempenho e otimização; e listarei cenários em que usar DataFrames e Datasets em vez de RDDs. Principalmente, focarei em DataFrames e Datasets, pois no Apache Spark 2.0, essas duas APIs foram unificadas.
Nossa principal motivação por trás dessa unificação é nossa busca para simplificar o Spark, limitando o número de conceitos que você precisa aprender e oferecendo maneiras de processar dados estruturados. E através da estrutura, o Spark pode oferecer abstrações de nível superior e APIs como construções de linguagem específicas de domínio.
Resilient Distributed Dataset (RDD)
RDD foi a principal API voltada para o usuário no Spark desde sua criação. Em sua essência, um RDD é uma coleção distribuída imutável de elementos dos seus dados, particionada entre os nós do seu cluster, que pode ser operada em paralelo com uma API de baixo nível que oferece transformações e ações.
Quando usar RDDs?
Considere estes cenários ou casos de uso comuns para usar RDDs quando:
- você deseja transformações e ações de baixo nível e controle sobre seu conjunto de dados;
- seus dados não são estruturados, como fluxos de mídia ou fluxos de texto;
- você deseja manipular seus dados com construções de programação funcional em vez de expressões específicas de domínio;
- você não se importa em impor um esquema, como formato colunar, ao processar ou acessar atributos de dados por nome ou coluna; e
- você pode abrir mão de alguns benefícios de otimização e desempenho disponíveis com DataFrames e Datasets para dados estruturados e semiestruturados.
O que acontece com os RDDs no Apache Spark 2.0?
Você pode perguntar: Os RDDs estão sendo relegados a cidadãos de segunda classe? Eles estão sendo descontinuados?
A resposta é um retumbante NÃO!
Além disso, como você notará abaixo, você pode transitar perfeitamente entre DataFrame ou Dataset e RDDs à vontade — por meio de chamadas simples de métodos de API — e DataFrames e Datasets são construídos sobre RDDs.
DataFrames
Assim como um RDD, um DataFrame é uma coleção distribuída imutável de dados. Diferente de um RDD, os dados são organizados em colunas nomeadas, como uma tabela em um banco de dados relacional. Projetado para tornar o processamento de grandes conjuntos de dados ainda mais fácil, o DataFrame permite que os desenvolvedores imponham uma estrutura a uma coleção distribuída de dados, permitindo abstrações de nível superior; ele fornece uma API de linguagem específica de domínio para manipular seus dados distribuídos; e torna o Spark acessível a um público mais amplo, além de engenheiros de dados especializados.
Em nossa prévia do webinar do Apache Spark 2.0 e no blog subsequente, mencionamos que no Spark 2.0, as APIs de DataFrame se fundiriam com as APIs de Datasets, unificando as capacidades de processamento de dados entre as bibliotecas. Devido a essa unificação, os desenvolvedores agora têm menos conceitos para aprender ou lembrar e trabalham com uma única API de alto nível e com segurança de tipo chamada Dataset.
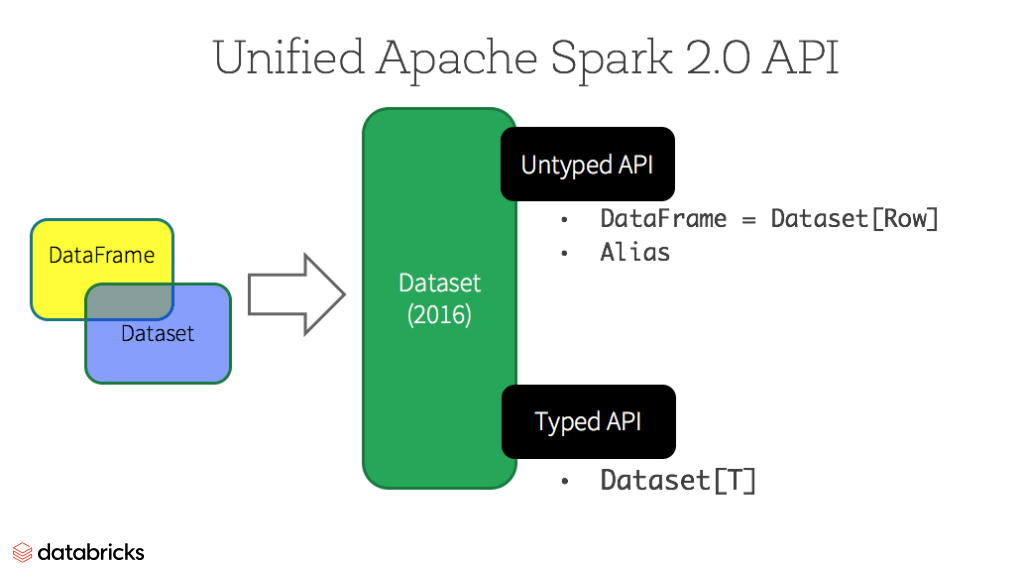
Datasets
A partir do Spark 2.0, o Dataset assume duas características de API distintas: uma API fortemente tipada e uma API não tipada, como mostrado na tabela abaixo. Conceitualmente, considere DataFrame como um alias para uma coleção de objetos genéricos Dataset[Row], onde um Row é um objeto JVM genérico não tipado. Dataset, por outro lado, é uma coleção de objetos JVM fortemente tipados, ditados por uma classe de caso que você define em Scala ou uma classe em Java.
APIs Tipadas e Não Tipadas
| Linguagem | Abstração Principal |
|---|---|
| Scala | Dataset[T] & DataFrame (alias para Dataset[Row]) |
| Java | Dataset[T] |
| Python* | DataFrame |
| R* | DataFrame |
Nota: Como Python e R não possuem segurança de tipo em tempo de compilação, temos apenas APIs não tipadas, especificamente DataFrames.
Benefícios das APIs de Dataset
Como desenvolvedor Spark, você se beneficia das APIs unificadas de DataFrame e Dataset no Spark 2.0 de várias maneiras.
1. Tipagem estática e segurança de tipo em tempo de execução
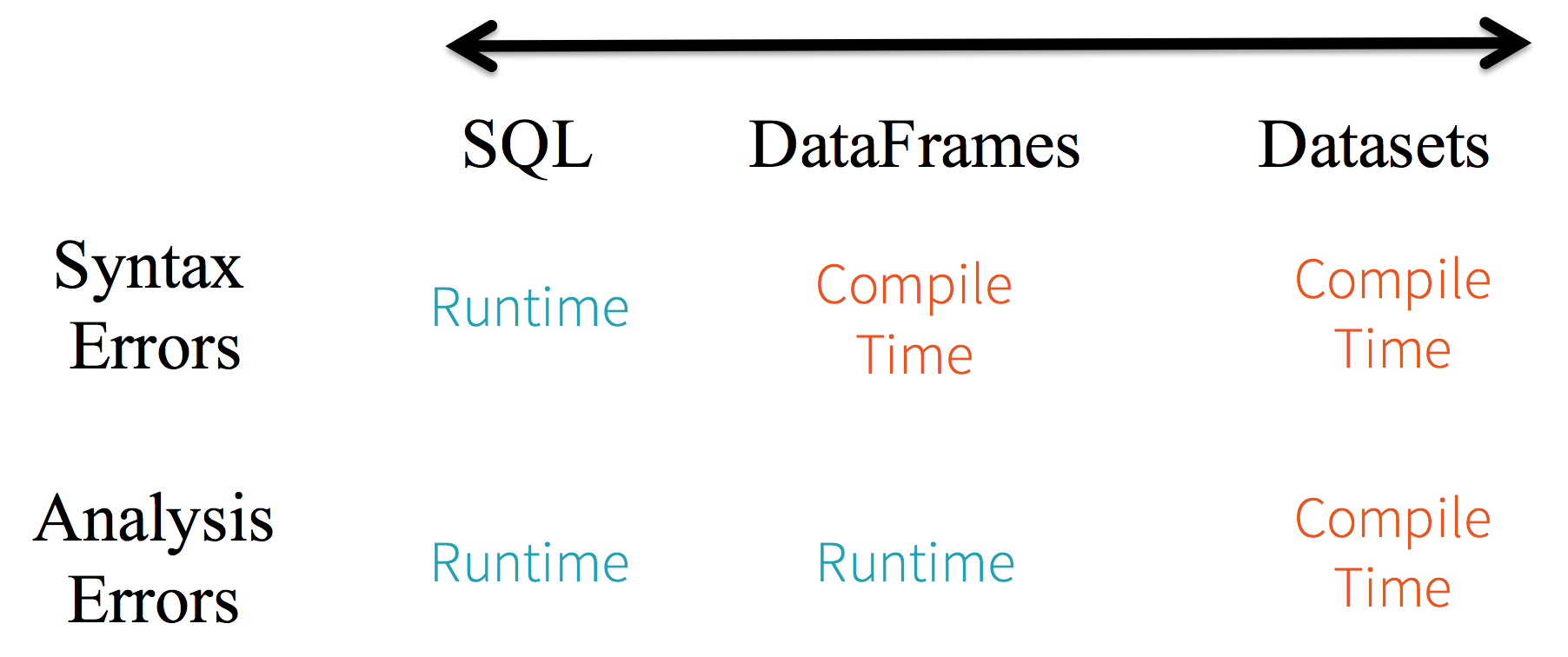
Considere a tipagem estática e a segurança em tempo de execução como um espectro, com SQL sendo o menos restritivo e Dataset o mais restritivo. Por exemplo, em suas consultas de string Spark SQL, você não saberá de um erro de sintaxe até o tempo de execução (o que pode ser custoso), enquanto em DataFrames e Datasets você pode capturar erros em tempo de compilação (o que economiza tempo e custos do desenvolvedor). Ou seja, se você invocar uma função em DataFrame que não faz parte da API, o compilador a detectará. No entanto, ele não detectará um nome de coluna inexistente até o tempo de execução.
Na extremidade do espectro está o Dataset, o mais restritivo. Como as APIs de Dataset são expressas como funções lambda e objetos tipados JVM, qualquer incompatibilidade de parâmetros tipados será detectada em tempo de compilação. Além disso, seu erro de análise também pode ser detectado em tempo de compilação, ao usar Datasets, economizando assim tempo e custos do desenvolvedor.
Tudo isso se traduz em um espectro de segurança de tipo ao longo da sintaxe e erros de análise em seu código Spark, com Datasets sendo o mais restritivo, porém produtivo para um desenvolvedor.
2. Abstração de alto nível e visualização personalizada de dados estruturados e semiestruturados
DataFrames, como uma coleção de Datasets[Row], oferecem uma visualização estruturada personalizada de seus dados semiestruturados. Por exemplo, digamos que você tenha um enorme conjunto de dados de eventos de dispositivos IoT, expresso em JSON. Como JSON é um formato semiestruturado, ele se presta bem ao uso de Dataset como uma coleção de Dataset[DeviceIoTData] fortemente tipados e específicos.
Você poderia expressar cada entrada JSON como DeviceIoTData, um objeto personalizado, com uma classe de caso Scala.
Em seguida, podemos ler os dados de um arquivo JSON.
Três coisas acontecem aqui nos bastidores no código acima:
- O Spark lê o JSON, infere o esquema e cria uma coleção de DataFrames.
- Neste ponto, o Spark converte seus dados em DataFrame = Dataset[Row], uma coleção de objeto Row genérico, pois ele não conhece o tipo exato.
- Agora, o Spark converte o Dataset[Row] -> Dataset[DeviceIoTData] tipo específico de objeto Scala JVM, conforme ditado pela classe DeviceIoTData.
A maioria de nós que trabalha com dados estruturados está acostumada a visualizar e processar dados de forma colunar ou acessar atributos específicos dentro de um objeto. Com Dataset como uma coleção de objetos tipados Dataset[ElementType], você obtém perfeitamente segurança em tempo de compilação e visualização personalizada para objetos JVM fortemente tipados. E seu fortemente tipado resultante Dataset[T] do código acima pode ser facilmente exibido ou processado com métodos de alto nível.
3. Facilidade de uso das APIs com estrutura
Embora a estrutura possa limitar o controle sobre o que seu programa Spark pode fazer com os dados, ela introduz semânticas ricas e um conjunto fácil de operações específicas de domínio que podem ser expressas como construtos de alto nível. A maioria dos cálculos, no entanto, pode ser realizada com as APIs de alto nível do Dataset. Por exemplo, é muito mais simples realizar operações agg, select, sum, avg, map, filter ou groupBy acessando os campos de dados de um objeto tipado DeviceIoTData do Dataset do que usando os campos de dados de linhas RDD.
Expressar seu cálculo em uma API específica de domínio é muito mais simples e fácil do que com expressões do tipo álgebra relacional (em RDDs). Por exemplo, o código abaixo irá filter() e map() para criar outro Dataset imutável.
4. Desempenho e Otimização
Junto com todos os benefícios acima, você não pode ignorar a eficiência de espaço e os ganhos de desempenho no uso das APIs DataFrame e Dataset por duas razões.
Primeiro, como as APIs DataFrame e Dataset são construídas sobre o motor Spark SQL, ele usa o Catalyst para gerar um plano de consulta lógico e físico otimizado. Em todas as APIs DataFrame/Dataset em R, Java, Scala ou Python, todas as consultas do tipo relacional passam pelo mesmo otimizador de código, proporcionando eficiência de espaço e velocidade. Enquanto a API tipada Dataset[T] é otimizada para tarefas de engenharia de dados, a API não tipada Dataset[Row] (um alias de DataFrame) é ainda mais rápida e adequada para análise interativa.

Segundo, como o Spark como um compilador entende seu objeto JVM do tipo Dataset, ele mapeia seu objeto JVM específico do tipo para a representação de memória interna do Tungsten usando Encoders. Como resultado, os Encoders do Tungsten podem serializar/desserializar eficientemente objetos JVM, bem como gerar bytecode compacto que pode executar em velocidades superiores.
Quando devo usar DataFrames ou Datasets?
- Se você deseja semânticas ricas, abstrações de alto nível e APIs específicas de domínio, use DataFrame ou Dataset.
- Se seu processamento exige expressões de alto nível, filtros, mapas, agregação, médias, soma, consultas SQL, acesso colunar e uso de funções lambda em dados semiestruturados, use DataFrame ou Dataset.
- Se você deseja um maior grau de segurança de tipo em tempo de compilação, deseja objetos JVM tipados, aproveita a otimização do Catalyst e se beneficia da geração de código eficiente do Tungsten, use Dataset.
- Se você deseja unificação e simplificação de APIs entre as Bibliotecas Spark, use DataFrame ou Dataset.
- Se você é um usuário de R, use DataFrames.
- Se você é um usuário de Python, use DataFrames e recorra a RDDs se precisar de mais controle.
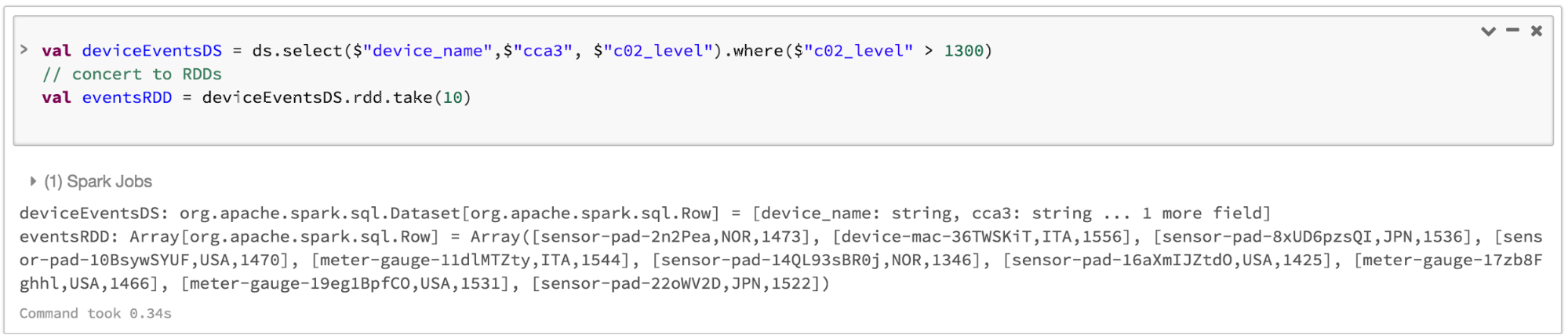
Note que você sempre pode interagir ou converter de DataFrame e/ou Dataset para um RDD de forma transparente, por meio de uma simples chamada de método .rdd. Por exemplo,
Colocando Tudo Junto
Em resumo, a escolha de quando usar RDD ou DataFrame e/ou Dataset parece óbvia. Enquanto o primeiro oferece funcionalidade e controle de baixo nível, o último permite visualização e estrutura personalizadas, oferece operações de alto nível e específicas de domínio, economiza espaço e executa em velocidades superiores.
À medida que examinamos as lições aprendidas com as primeiras versões do Spark — como simplificar o Spark para desenvolvedores, como otimizar e torná-lo performático — decidimos elevar as APIs RDD de baixo nível a uma abstração de alto nível como DataFrame e Dataset e construir essa abstração de dados unificada entre as bibliotecas sobre o otimizador Catalyst e o Tungsten.
Escolha uma — APIs DataFrames e/ou Dataset ou RDDs — que atenda às suas necessidades e caso de uso, mas não me surpreenderia se você caísse no grupo da maioria dos desenvolvedores que trabalham com dados estruturados e semiestruturados.
Próximos Passos?
Você pode experimentar o Apache Spark 2.2 no Databricks.
Você também pode assistir à apresentação do Spark Summit sobre A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets
Se você ainda não se inscreveu, experimente o Databricks agora.
Nas próximas semanas, teremos uma série de blogs sobre Structured Streaming. Fique ligado.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.