O que é o Catalyst Optimizer?
Como o otimizador Catalyst usa técnicas baseadas em regras e em custos em planos de consulta com estrutura em árvore para tornar as consultas Spark SQL mais rápidas, eficientes e fáceis de estender.
- Veja como o Catalyst está no núcleo do Spark SQL como um otimizador extensível, construído sobre recursos do Scala, como correspondência de padrões e quasiquotes, para suportar novas regras e tipos de dados.
- Entenda como o Catalyst representa consultas como árvores e aplica regras nas fases de análise, otimização lógica, planejamento físico e geração de código para criar planos de execução eficientes.
- Descubra como o Catalyst suporta otimização baseada em regras e em custos, além de expor pontos de extensão para fontes de dados externas e tipos definidos pelo usuário.
No centro do Spark SQL está o Catalyst Optimizer, que usa recursos avançados de linguagem de programação (por exemplo, correspondência de padrões do Scala e quasi quotes) em uma nova maneira de construir um otimizador de queries extensível. O Catalyst é baseado em construções de programação funcional em Scala e projetado com estes dois propósitos principais:
- Adicionar facilmente novas técnicas e recursos de otimização ao Spark SQL
- Permitir que desenvolvedores externos ampliem o otimizador (por exemplo, adicionando regras específicas de fonte de dados, suporte para novos tipos de dados etc.)
O manual de IA agêntica para empresas

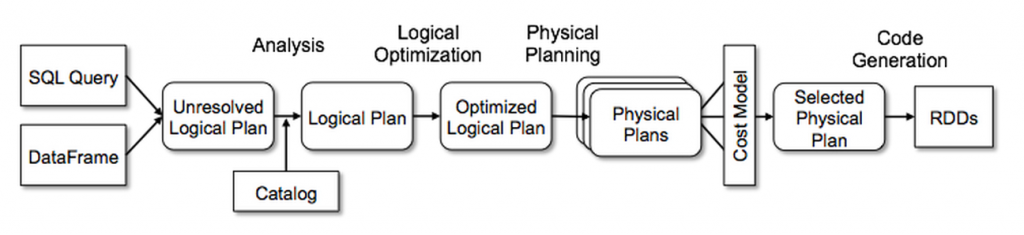
O Catalyst contém uma biblioteca geral para representar árvores e aplicar regras para manipulá-las. Além dessa estrutura, ele tem bibliotecas específicas para processamento de query relacional (p. ex., expressões, planos de query lógico) e vários conjuntos de regras que gerenciam diferentes fases de execução de queries: análise, otimização lógica, planejamento físico e geração de código para compilar partes de queries ao bytecode Java. Para este último, o Catalyst utiliza quasiquotes (outro recurso do Scala) para facilitar a geração de código no tempo de execução a partir de expressões compostas. O Catalyst também oferece vários pontos de extensão públicos, incluindo fontes de dados externas e tipos definidos pelo usuário. Além disso, o Catalyst oferece suporte à otimização baseada em regras e em custos.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.