Apresentando Pandas UDF para PySpark
Como executar seu código Python nativo com PySpark, de forma rápida.
por Li Jin
A Edição Gratuita substituiu a Edição Comunitária, oferecendo recursos aprimorados sem custo. Comece a usar a Edição Gratuita hoje mesmo.
OBSERVAÇÃO: O Spark 3.0 introduziu um novo pandas UDF. Você pode encontrar mais detalhes no seguinte post de blog: Novos Pandas UDFs e Dicas de Tipo Python na Próxima Versão do Apache Spark 3.0
Este é um post da comunidade convidado de Li Jin, engenheira de software na Two Sigma Investments, LP em Nova York. Este blog também está publicado em Two Sigma
Experimente este notebook no Databricks
ATUALIZAÇÃO: Este blog foi atualizado em 22 de fevereiro de 2018 para incluir algumas alterações.
Este post de blog apresenta os Pandas UDFs (também conhecidos como Vectorized UDFs), um recurso na próxima versão do Apache Spark 2.3 que melhora substancialmente o desempenho e a usabilidade das funções definidas pelo usuário (UDFs) em Python.
Nos últimos anos, Python se tornou a linguagem padrão para cientistas de dados. Pacotes como pandas, numpy, statsmodel e scikit-learn ganharam grande adoção e se tornaram as principais ferramentas. Ao mesmo tempo, Apache Spark se tornou o padrão de fato no processamento de big data. Para permitir que os cientistas de dados aproveitem o valor do big data, o Spark adicionou uma API Python na versão 0.7, com suporte para funções definidas pelo usuário. Essas funções definidas pelo usuário operam linha por linha e, portanto, sofrem com alta sobrecarga de serialização e invocação. Como resultado, muitos pipelines de dados definem UDFs em Java e Scala e, em seguida, as invocam a partir do Python.
Os Pandas UDFs, construídos sobre Apache Arrow, trazem o melhor dos dois mundos: a capacidade de definir UDFs de baixo overhead e alto desempenho inteiramente em Python.
No Spark 2.3, haverá dois tipos de Pandas UDFs: escalar e grouped map. Em seguida, ilustramos seus usos com quatro exemplos de programas: Adicionar Um, Probabilidade Cumulativa, Subtrair Média, Regressão Linear de Mínimos Quadrados Ordinários.
Escalares Pandas UDFs
Escalares Pandas UDFs são usados para vetorizar operações escalares. Para definir um escalar Pandas UDF, basta usar @pandas_udf para anotar uma função Python que recebe pandas.Series como argumentos e retorna outra pandas.Series do mesmo tamanho. Abaixo ilustramos usando dois exemplos: Adicionar Um e Probabilidade Cumulativa.
Adicionar Um
Calcular v + 1 é um exemplo simples para demonstrar as diferenças entre UDFs linha por linha e escalares Pandas UDFs. Observe que os operadores de coluna embutidos podem ter um desempenho muito mais rápido neste cenário.
Usando UDFs linha por linha:
Usando Pandas UDFs:
Os exemplos acima definem um UDF linha por linha "plus_one" e um escalar Pandas UDF "pandas_plus_one" que realiza a mesma computação "adicionar um". As definições de UDF são as mesmas, exceto pelos decoradores da função: "udf" vs "pandas_udf".
Na versão linha por linha, a função definida pelo usuário recebe um double "v" e retorna o resultado de "v + 1" como um double. Na versão Pandas, a função definida pelo usuário recebe um pandas.Series "v" e retorna o resultado de "v + 1" como um pandas.Series. Como "v + 1" é vetorizado em pandas.Series, a versão Pandas é muito mais rápida que a versão linha por linha.
Observe que existem dois requisitos importantes ao usar escalares pandas UDFs:
- As séries de entrada e saída devem ter o mesmo tamanho.
- Como uma coluna é dividida em vários
pandas.Seriesé interno ao Spark e, portanto, o resultado da função definida pelo usuário deve ser independente da divisão.
Probabilidade Cumulativa
Este exemplo mostra um uso mais prático do escalar Pandas UDF: calcular a probabilidade cumulativa de um valor em uma distribuição normal N(0,1) usando o pacote scipy.
stats.norm.cdf funciona tanto em um valor escalar quanto em pandas.Series, e este exemplo também pode ser escrito com UDFs linha por linha. Semelhante ao exemplo anterior, a versão Pandas é executada muito mais rapidamente, como mostrado posteriormente na seção "Comparação de Desempenho".
Grouped Map Pandas UDFs
Usuários de Python estão bastante familiarizados com o padrão split-apply-combine em análise de dados. Grouped map Pandas UDFs são projetados para este cenário e operam em todos os dados de um determinado grupo, por exemplo, "para cada data, aplique esta operação".
Grouped map Pandas UDFs primeiro dividem um Spark DataFrame em grupos com base nas condições especificadas no operador groupby, aplicam uma função definida pelo usuário (pandas.DataFrame -> pandas.DataFrame) a cada grupo, combinam e retornam os resultados como um novo Spark DataFrame.
Grouped map Pandas UDFs usam o mesmo decorador de função pandas_udf que os escalares Pandas UDFs, mas eles têm algumas diferenças:
- Entrada da função definida pelo usuário:
- Escalar:
pandas.Series - Grouped map:
pandas.DataFrame
- Escalar:
- Saída da função definida pelo usuário:
- Escalar:
pandas.Series - Grouped map:
pandas.DataFrame
- Escalar:
- Semântica de agrupamento:
- Escalar: sem semântica de agrupamento
- Grouped map: definido pela cláusula "groupby"
- Tamanho da saída:
- Escalar: igual ao tamanho da entrada
- Grouped map: qualquer tamanho
- Tipos de retorno no decorador da função:
- Escalar: um
DataTypeque especifica o tipo dopandas.Seriesretornado - Grouped map: um
StructTypeque especifica o nome e o tipo de cada coluna dopandas.DataFrameretornado
- Escalar: um
Em seguida, vamos percorrer dois exemplos para ilustrar os casos de uso de grouped map Pandas UDFs.
Subtrair Média
Este exemplo mostra um uso simples de grouped map Pandas UDFs: subtrair a média de cada valor no grupo.
Neste exemplo, subtraímos a média de v de cada valor de v para cada grupo. A semântica de agrupamento é definida pela função "groupby", ou seja, cada pandas.DataFrame de entrada para a função definida pelo usuário tem o mesmo valor "id". O esquema de entrada e saída desta função definida pelo usuário são os mesmos, então passamos "df.schema" para o decorador pandas_udf para especificar o esquema.
Grouped map Pandas UDFs também podem ser chamados como funções Python independentes no driver. Isso é muito útil para depuração, por exemplo:
No exemplo acima, primeiro convertemos um pequeno subconjunto do Spark DataFrame para um pandas.DataFrame e, em seguida, executamos subtract_mean como uma função Python independente nele. Após verificar a lógica da função, podemos chamar o UDF com Spark em todo o conjunto de dados.
Regressão Linear de Mínimos Quadrados Ordinários
O último exemplo mostra como executar regressão linear OLS para cada grupo usando statsmodels. Para cada grupo, calculamos beta b = (b1, b2) para X = (x1, x2) de acordo com o modelo estatístico Y = bX + c.
Este exemplo demonstra que as UDFs Pandas de mapa agrupado podem ser usadas com qualquer função Python arbitrária: pandas.DataFrame -> pandas.DataFrame. O pandas.DataFrame retornado pode ter um número diferente de linhas e colunas que a entrada.
Comparação de Desempenho
Por fim, queremos mostrar a comparação de desempenho entre UDFs de linha por linha e UDFs Pandas. Executamos micro benchmarks para três dos exemplos acima (mais um, probabilidade cumulativa e subtração da média).
Configuração e Metodologia
Executamos o benchmark em um cluster Spark de nó único na Databricks Community Edition.
Detalhes da configuração:
Dados: Um DataFrame de 10 milhões de linhas com uma coluna Int e uma coluna Double
Cluster: 6.0 GB de Memória, 0.88 Cores, 1 DBU
Databricks runtime versão: Última RC (4.0, Scala 2.11)
Para a implementação detalhada do benchmark, confira o Notebook de UDFs Pandas.
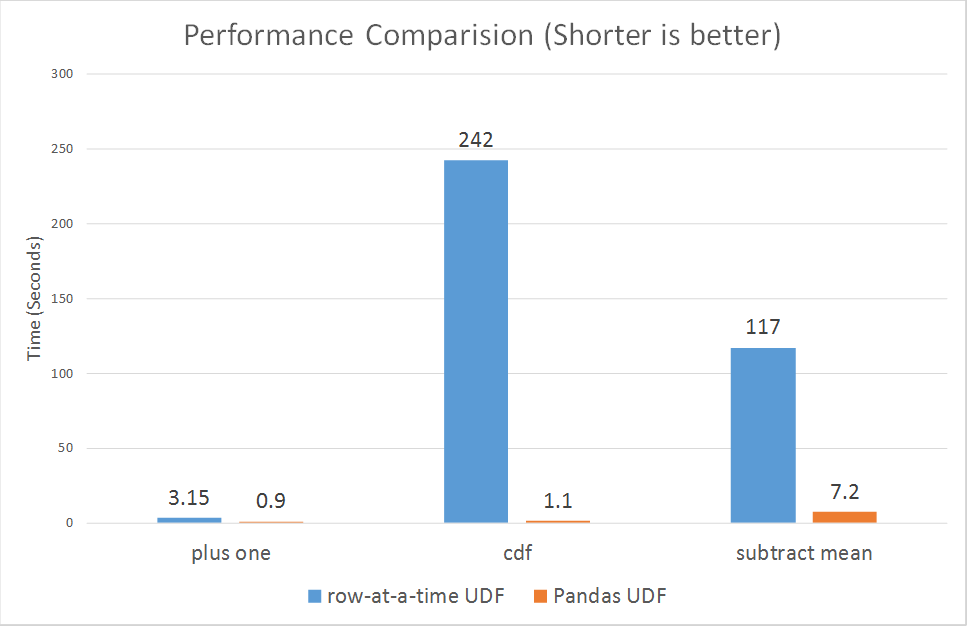
Como mostrado nos gráficos, as UDFs Pandas têm um desempenho muito melhor que as UDFs de linha por linha em geral, variando de 3x a mais de 100x.
Conclusão e Trabalho Futuro
O próximo lançamento do Spark 2.3 estabelece a base para melhorar substancialmente as capacidades e o desempenho das funções definidas pelo usuário em Python. No futuro, planejamos introduzir suporte para UDFs Pandas em agregações e funções de janela. O trabalho relacionado pode ser acompanhado em SPARK-22216.
As UDFs Pandas são um ótimo exemplo do esforço da comunidade Spark. Gostaríamos de agradecer a Bryan Cutler, Hyukjin Kwon, Jeff Reback, Liang-Chi Hsieh, Leif Walsh, Li Jin, Reynold Xin, Takuya Ueshin, Wenchen Fan, Wes McKinney, Xiao Li e muitos outros por suas contribuições. Finalmente, agradecimentos especiais à comunidade Apache Arrow por tornar este trabalho possível.
Próximos Passos
Você pode experimentar o notebook de UDFs Pandas e este recurso já está disponível como parte do Databricks Runtime 4.0 beta.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.