Simplificando os pipelines de genômica em escala com o Databricks Delta
Obtenha uma prévia exclusiva do novo ebook da O'Reilly para ter o guia passo a passo de que você precisa para começar a usar o Delta Lake.
Experimente este Notebook no Databricks
Este é o primeiro blog da nossa série “genomics análise em escala”. Nesta série, demonstraremos como a plataforma de análise unificada para genomics da Databricks permite que os clientes analisem dados genômicos em escala populacional. A partir do resultado do nosso pipeline genômico, esta série fornecerá um tutorial sobre como usar o Databricks para executar controle de qualidade de amostras, genotipagem conjunta, controle de qualidade de coorte e análises genéticas estatísticas avançadas.
Desde a conclusão do Projeto Genoma Humano em 2003, houve uma explosão de dados impulsionada por uma queda drástica no custo do sequenciamento de DNA, de US$ 3 bilhões1 para o primeiro genoma a menos de US$ 1.000 hoje.
[1] O Projeto Genoma Humano foi um projeto de US$ 3 bilhões liderado pelo Departamento de Energia e pelos Institutos Nacionais de Saúde, iniciado em 1990 e concluído em 2003.
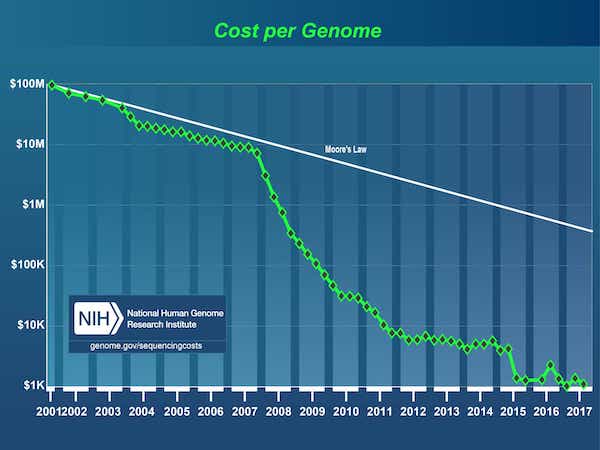
Fonte: Custos de Sequenciamento de DNA: Dados
Consequentemente, o campo da genômica amadureceu a um estágio em que as empresas começaram a fazer o sequenciamento de DNA em escala populacional. No entanto, sequenciar o código de DNA é apenas o primeiro passo, os dados brutos precisam ser transformados em um formato adequado para análise. Normalmente, isso é feito juntando uma série de ferramentas de bioinformática com scripts personalizados e processando os dados em um único nó, uma amostra por vez, até obtermos uma coleção de variantes genômicas. Cientistas de bioinformática hoje gastam a maior parte do tempo criando e mantendo esses pipelines. À medida que os conjuntos de dados genômicos se expandiram para a escala de petabytes, tornou-se um desafio responder até mesmo às seguintes perguntas simples em tempo hábil:
- Quantas amostras foram sequenciadas neste mês?
- Qual é o número total de variantes únicas detectadas?
- Quantas variantes vimos nas diferentes classes de variação?
Para agravar ainda mais esse problema, os dados de milhares de indivíduos não podem ser armazenados, rastreados nem versionados e, ao mesmo tempo, permanecer acessíveis e consultáveis. Consequentemente, pesquisadores frequentemente duplicam subconjuntos de seus dados genômicos ao realizar suas análises, o que aumenta o espaço de armazenamento geral e os custos. Na tentativa de aliviar esse problema, hoje os pesquisadores empregam uma estratégia de “congelamento de dados”, normalmente entre seis meses e dois anos, onde eles interrompem o trabalho com novos dados e, em vez disso, se concentram em uma cópia congelada dos dados existentes. Não há uma solução para desenvolver análises de forma incremental em períodos de tempo mais curtos, o que causa a desaceleração do progresso da pesquisa.
Há uma forte necessidade de um software robusto que possa consumir dados genômicos em escala industrial, ao mesmo tempo em que mantém a flexibilidade para que os cientistas explorem os dados, iterem em seus pipelines analíticos e obtenham novas percepções.
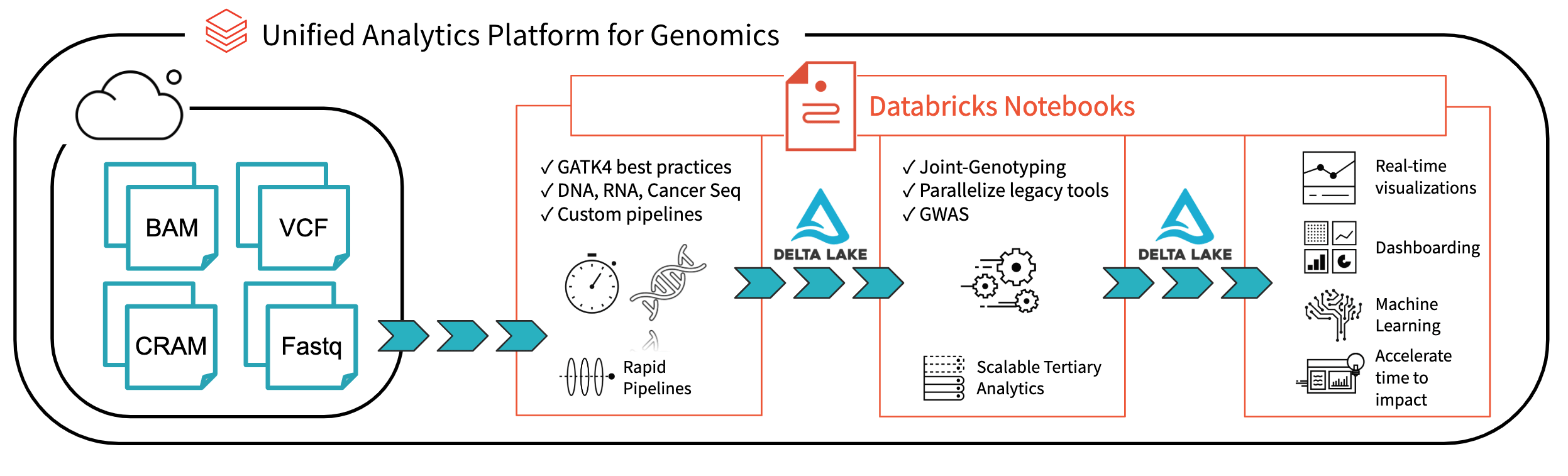
Fig. 1. Arquitetura para análise de genomics de ponta a ponta com Databricks
Com o Databricks Delta: A Unified Management System for tempo real análise big data, a plataforma Databricks deu um o passo importante para resolver os problemas de governança de dados, acesso a dados e análise de dados enfrentados pelos pesquisadores hoje. Com o Databricks Delta Lake, você pode armazenar todos os seus dados genômicos em um único lugar e criar análises que são atualizadas em tempo real à medida que novos dados são ingeridos. Combinado com otimizações em nossa plataforma de análise unificada para Genomics (UAP4G) para ler, gravar e processar formatos de arquivo de genômica, oferecemos uma solução de ponta a ponta para fluxos de trabalho de pipelines de genômica. A arquitetura UAP4G oferece flexibilidade, permitindo que os clientes conectem seus próprios pipelines e desenvolvam sua própria analítica terciária. Como exemplo, destacamos o dashboard a seguir, que mostra métricas de controle de qualidade e visualizações que podem ser calculadas e apresentadas de forma automatizada e personalizadas para atender aos seus requisitos específicos.
https://www.youtube.com/watch?v=73fMhDKXykU
No restante deste blog, vamos explicar os passos que seguimos para criar o painel de controle de qualidade acima, que é atualizado em tempo real à medida que as amostras concluem o processamento. Ao usar um pipeline baseado em Delta para processar dados genômicos, nossos clientes agora podem operar seus pipelines de uma forma que oferece visibilidade em tempo real, amostra por amostra. Com os notebooks da Databricks (e integrações como GitHub e MLflow), eles podem rastrear e versionar análises de uma forma que garantirá que seus resultados sejam reproduzíveis. Seus bioinformatas podem dedicar menos tempo à manutenção de pipelines e passar mais tempo fazendo descobertas. Vemos o UAP4G como o motor que impulsionará a transformação de análises ad-hoc para a genomics de produção em escala industrial, permitindo melhores percepções sobre o link entre a genética e as doenças.
Ler Dados de Amostra
Vamos começar lendo os dados de variação de um pequeno coorte de amostras; a instrução a seguir lê os dados para um sampleId específico e os salva usando o formato Databricks Delta (na pasta delta_stream_output).
Observação: a pasta annotations_etl_parquet contém anotações geradas a partir do dataset 1000 genomes armazenadas em formato parquet. O ETL e o processamento dessas anotações foram realizados usando a Plataforma de Análise Unificada para Genômica da Databricks.
Começar transmissão da tabela Databricks Delta
Na declaração a seguir, estamos criando o DataFrame do Apache Spark de exomas, que está lendo um stream (via readStream) de dados usando o formato Databricks Delta. Este é um DataFrame de execução contínua ou dinâmico, ou seja, o DataFrame de exomas carregará novos dados à medida que forem gravados na pasta delta_stream_output. Para visualizar o DataFrame de exomas, podemos executar uma consulta de DataFrame para encontrar a contagem de variantes agrupadas pelo sampleId.
Ao executar a instrução display, o notebook do Databricks fornece um dashboard de transmissão para monitorar os trabalhos de transmissão. Imediatamente abaixo do job de transmissão estão os resultados da declaração de exibição (ou seja, a contagem de variantes por sample_id).
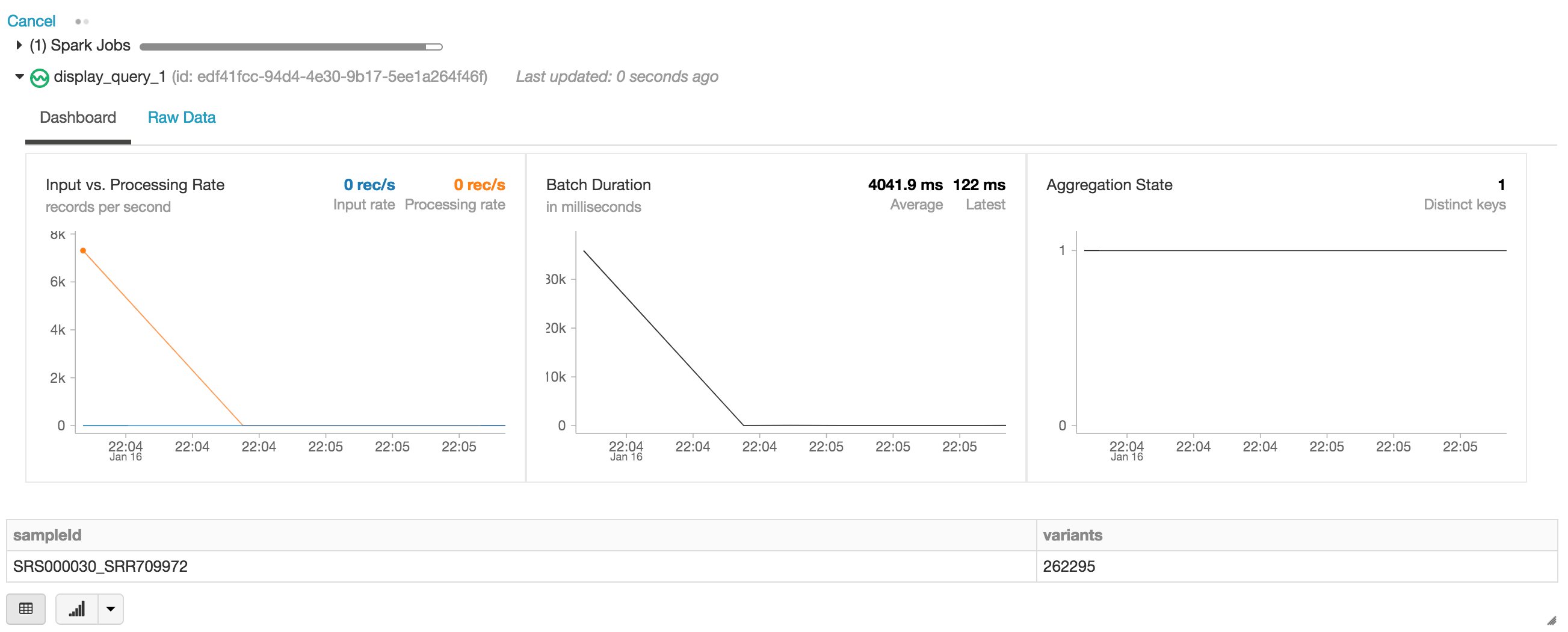
Vamos continuar respondendo ao nosso conjunto inicial de perguntas executando outras queries de DataFrame com base em nosso DataFrame exomes.
Contagem de Variante de Nucleotídeo Único
Para continuar o exemplo, podemos calcular rapidamente o número de variantes de nucleotídeo único (SNVs), conforme exibido no gráfico a seguir.
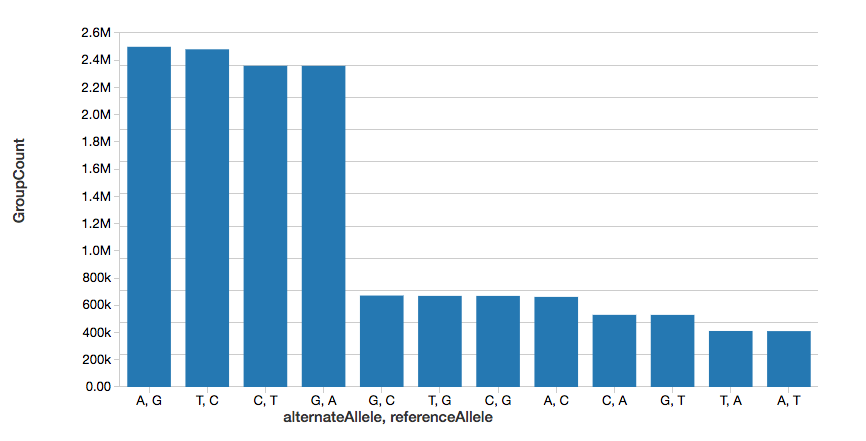
Observe que o comando display faz parte do workspace do Databricks que permite visualizar seu DataFrame usando as visualizações do Databricks (ou seja, não é necessário programar).
Contagem de variantes
Já que anotamos nossas variantes com efeitos funcionais, podemos continuar nossa análise observando a dispersão dos efeitos das variantes que vemos. A maioria das variantes detectadas flanqueia regiões que codificam proteínas, estas são conhecidas como variantes não codificantes.
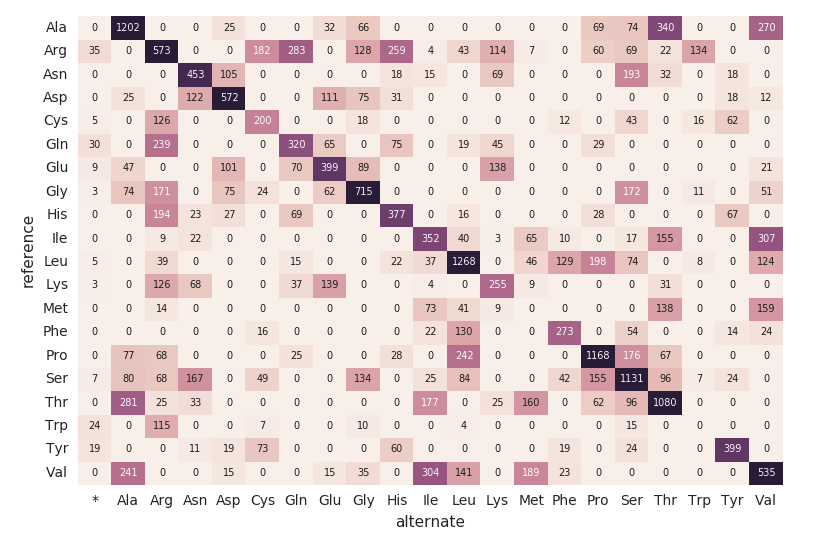
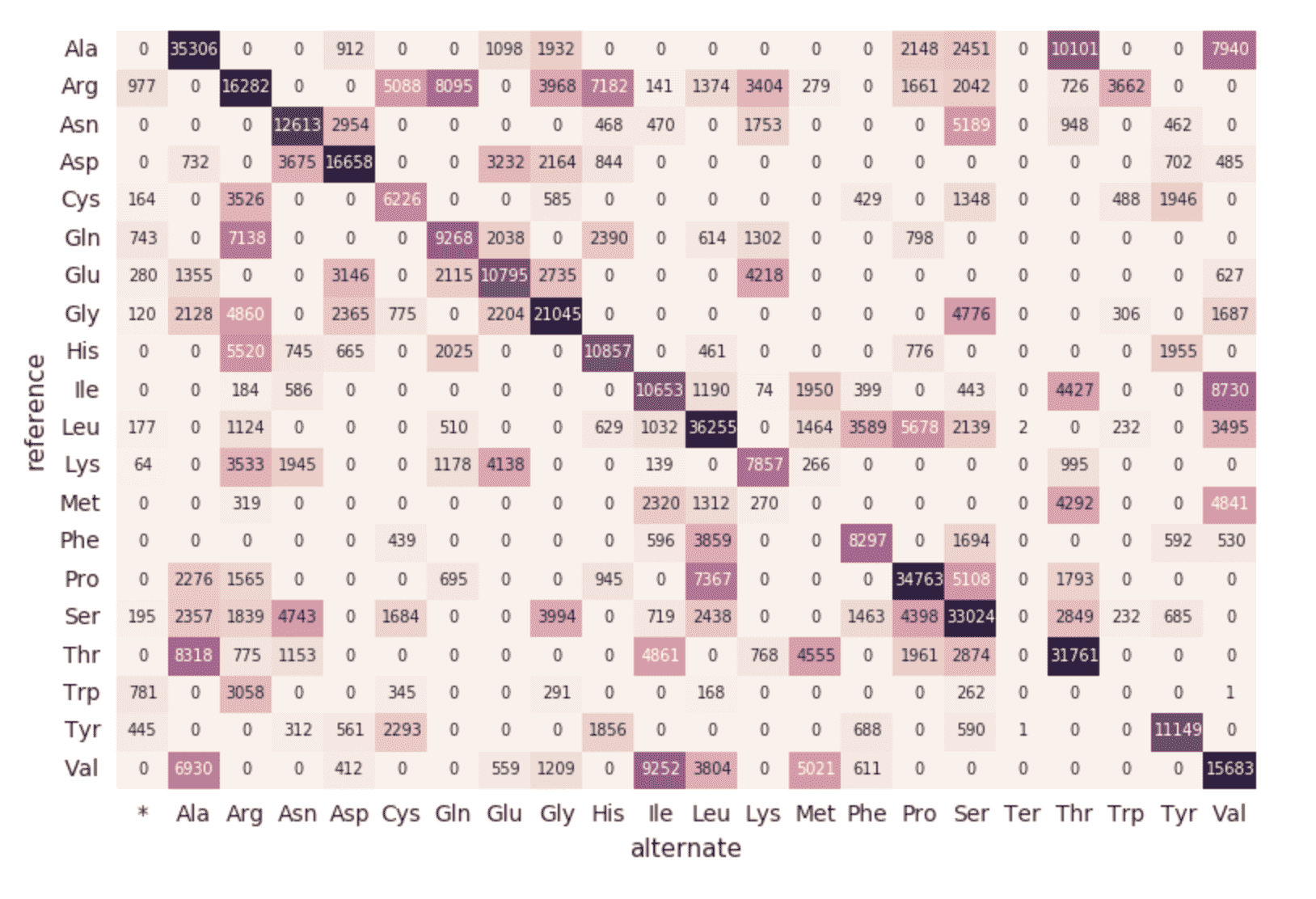
Mapa de calor de substituição de aminoácidos
Continuando com nosso DataFrame exomes, vamos calcular as contagens de substituição de aminoácidos com o seguinte trecho de código. Semelhante aos DataFrames anteriores, criaremos outro DataFrame dinâmico (aa_counts) para que, à medida que novos dados forem processados pelo DataFrame exomes, eles também sejam refletidos nas contagens de substituição de aminoácidos. Também estamos gravando os dados na memória (ou seja, .format(“memory”)) e processando lotes a cada 60s (ou seja, trigger(processingTime=’60 seconds’)) para que o código do mapa de calor do Pandas downstream possa processar e visualizar o mapa de calor.
O trecho de código a seguir lê a tabela amino_acid_substitutions do Spark anterior, determina a contagem máxima, cria uma nova tabela dinâmica do Pandas a partir da tabela do Spark e, em seguida, grafica o mapa de calor.
Migrando para um pipeline contínuo
Até este ponto, os trechos de código e as visualizações anteriores representam uma única execução para um único sampleId. Mas como estamos usando o Structured Streaming e o Databricks Delta, este código pode ser usado (sem nenhuma alteração) para construir um pipeline de dados de produção que calcula estatísticas de controle de qualidade continuamente, conforme as amostras passam pelo nosso pipeline. Para demonstrar isso, podemos executar o trecho de código a seguir, que carregará todo o nosso dataset.
Conforme descrito nos trechos de código anteriores, a origem do DataFrame exomes são os arquivos carregados na pasta delta_stream_output. Inicialmente, carregamos um conjunto de arquivos para um único sampleId (ou seja, sampleId = “SRS000030_SRR709972”). O trecho de código anterior agora pega todas as amostras parquet geradas (ou seja, parquets) e carrega incrementalmente esses arquivos por sampleId na mesma pasta delta_stream_output. O GIF animado a seguir mostra a saída abreviada do trecho de código anterior.
https://www.youtube.com/watch?v=JPngSC5Md-Q
Visualizando seu pipeline genomics
Ao rolar de volta para o topo do seu notebook, você notará que o DataFrame exomes agora está carregando automaticamente os novos sampleIds. Como o componente de transmissão estructurada do nosso pipeline de genomics é executado continuamente, ele processa os dados assim que novos arquivos são carregados na pasta delta_stream_outputpath. Ao usar o formato Databricks Delta, podemos garantir a consistência transacional da transmissão de dados para o DataFrame exomes.
https://www.youtube.com/watch?v=Q7KdPsc5mbY
Ao contrário da criação inicial do nosso DataFrame exomes, observe como o painel de monitoramento de transmissão estructurada agora está carregando dados (ou seja, a “taxa de entrada vs. processamento” flutuante, a “duração do lote” flutuante e um aumento de chaves distintas no “estado de agregações”). Enquanto o DataFrame exomes está processando, observe as novas linhas de sampleIds (e as contagens de variantes). Esta mesma ação também pode ser vista para a consulta de agrupamento por tipo de mutação associada.
https://www.youtube.com/watch?v=sT179SCknGM
Com o Databricks Delta, todos os novos dados são transacionalmente consistentes em cada um dos nossos passos do pipeline de genomics. Isso é importante porque garante que seu pipeline seja consistente (mantém a consistência de seus dados, ou seja, garante que todos os dados estejam “corretos”), confiável (a transação é bem-sucedida ou falha completamente) e possa lidar com atualizações em tempo real (a capacidade de lidar com muitas transações simultaneamente e qualquer interrupção ou falha não afetará os dados). Dessa forma, até mesmo os dados em nosso mapa de substituição de aminoácidos downstream (que teve vários os passos de ETL adicionais) são atualizados de forma transparente.
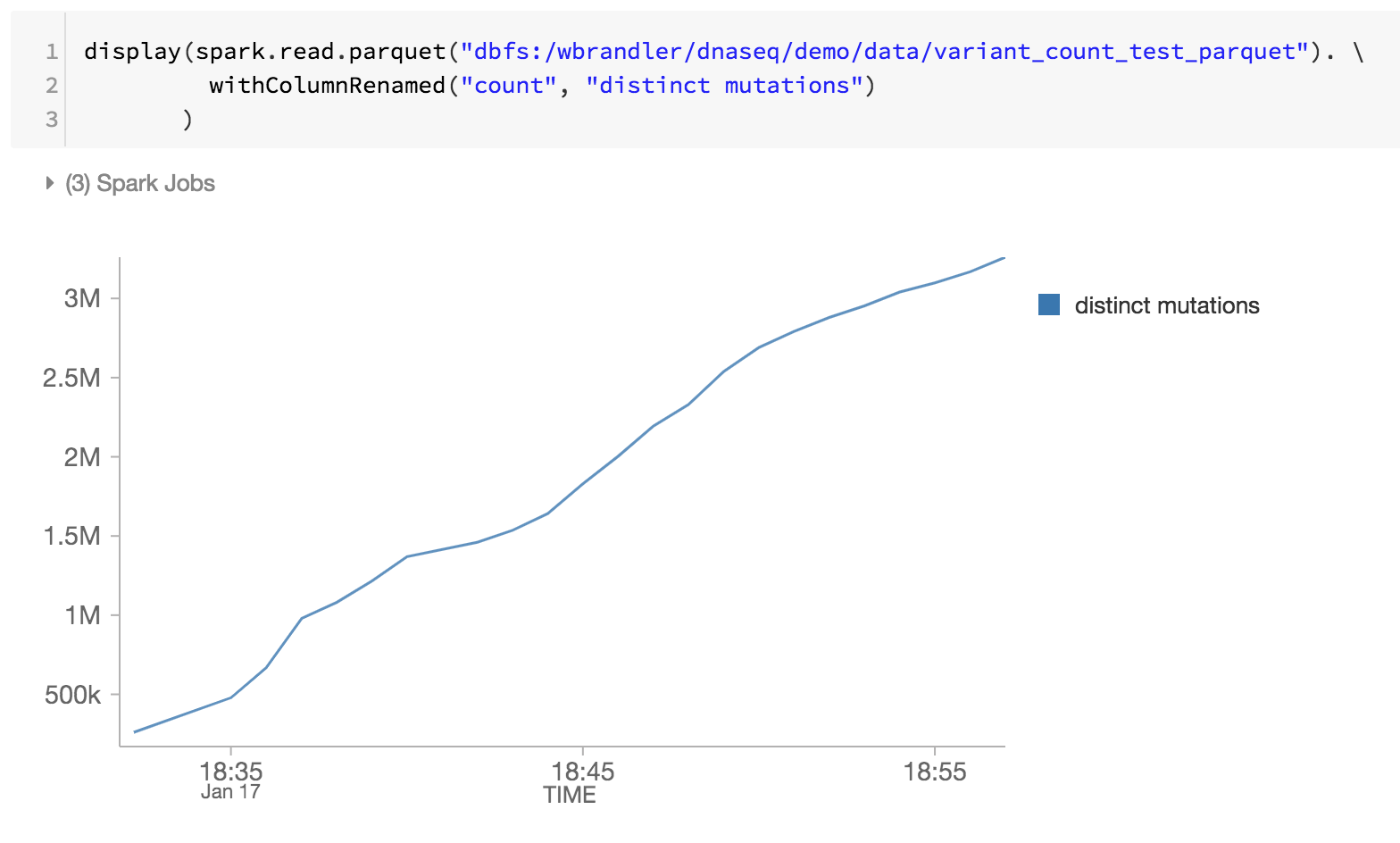
Como o último passo do nosso pipeline genômico, também estamos monitorando as mutações distintas, revisando os arquivos parquet do Databricks Delta no DBFS (ou seja, o aumento de mutações distintas ao longo do tempo).
Resumo
Usando a base da plataforma de análise unificada Databricks, com foco especial no Databricks Delta, bioinformatas e pesquisadores podem aplicar analítica distribuída com consistência transacional usando a plataforma de análise unificada Databricks para Genomics. Essas abstrações permitem que profissionais de dados simplifiquem os pipelines de genomics. Aqui, criamos um pipeline de controle de qualidade de amostras genômicas que processa dados continuamente à medida que novas amostras são processadas, sem intervenção manual. Esteja você executando ETL ou analítica sofisticada, seus dados fluirão pelo seu pipeline de genomics rapidamente e sem interrupção. Experimente você mesmo hoje fazendo o download do Notebook Simplifying genomics pipelines at escala with Databricks Delta.
Comece a analisar genômica em escala:
- Leia nosso guia de soluçãode Análise Unificada para Genômica
- Download do Notebook Simplificando Pipelines de Genômica em escala com Databricks Delta
- Inscreva-se para um trial grátis da Análise Unificada do Databricks para o Genomics
Agradecimentos
Agradecimentos a Yongsheng Huang e Michael Ortega por suas contribuições.
Visite o hub on-line do Delta Lake para saber mais, baixar o código mais recente e fazer parte da comunidade do Delta Lake.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.