Detectando Vieses de Dados Usando SHAP e Machine Learning
O que o Machine Learning e o SHAP podem nos dizer sobre a relação entre os salários de desenvolvedores e a diferença salarial de gênero
por Sean Owen
Experimente o notebook Detecção de viés de dados usando SHAP para reproduzir os passos descritos abaixo e assista ao nosso webinar sob demanda para saber mais.
A pesquisa anual de desenvolvedores do StackOverflow foi concluída no início deste ano, e eles gentilmente publicaram os resultados (anonimizados) de 2019 para análise. Eles são uma rich view da experiência de desenvolvedores de software em todo o mundo: qual é o editor favorito deles? quantos anos de experiência? tabs ou espaços? e, crucialmente, o salário. Os salários dos engenheiros de software são bons e, às vezes, tão altos que chegam a surpreender e viram notícia.
A indústria de tecnologia também está dolorosamente ciente de que nem sempre corresponde a seus supostos ideais meritocráticos. A remuneração não é uma função pura do mérito, e inúmeros relatos nos dizem que fatores como escola de renome, idade, raça e gênero têm um efeito em resultados como o salário.
O machine learning pode fazer mais do que prever coisas? Ele pode explicar os salários e, assim, destacar casos em que esses fatores podem estar causando diferenças salariais indesejadas? Este exemplo irá esboçar como modelos padrão podem ser aumentados com SHAP (SHapley Additive exPlanations) para detectar instâncias individuais cujas previsões podem ser preocupantes e, em seguida, investigar mais a fundo os motivos específicos pelos quais os dados levam a essas previsões.
Viés do modelo ou viés nos dados?
Embora este tópico seja frequentemente caracterizado como a detecção de "viés do modelo", um modelo é apenas um espelho dos dados nos quais foi treinado. Se o modelo for 'enviesado', ele aprendeu isso a partir dos fatos históricos dos dados. Os modelos não são o problema em si; eles são uma oportunidade para analisar os dados em busca de evidências de viés.
Explicar modelos não é novidade, e a maioria das bibliotecas pode avaliar a importância relativa das entradas para um modelo. Essas são views agregadas dos efeitos das entradas. No entanto, a saída de alguns modelos do machine learning tem efeitos altamente individuais: seu empréstimo foi aprovado? você receberá ajuda financeira? você é um viajante suspeito?
De fato, o StackOverflow oferece uma calculadora prática para estimar o salário esperado de alguém, com base em sua pesquisa. Só podemos especular sobre a precisão geral das previsões, mas tudo com que um desenvolvedor se importa são suas próprias perspectivas.
A pergunta certa talvez não seja: os dados sugerem um viés geral? mas sim: os dados mostram casos individuais de viés?
Avaliando os dados da pesquisa do StackOverflow
Os dados de 2019 são, felizmente, limpos e livres de problemas de dados. Eles contêm respostas a 85 perguntas de cerca de 88.000 desenvolvedores.
Este exemplo foca apenas em desenvolvedores em tempo integral. O conjunto de dados contém muitas informações relevantes, como anos de experiência, educação, função e informações demográficas. É importante notar que este conjunto de dados não contém informações sobre bônus e participação acionária, apenas salário.
Ele também tem respostas para perguntas abrangentes sobre atitudes em relação a blockchain, fizz buzz e a própria pesquisa. Eles são excluídos aqui por ser improvável que reflitam a experiência e as habilidades que supostamente deveriam determinar a remuneração. Da mesma forma, para simplificar, ele também se concentrará apenas em desenvolvedores baseados nos EUA.
Os dados precisam de um pouco mais de transformação antes da modelagem. Várias perguntas permitem múltiplas respostas, como "Quais são seus maiores desafios de produtividade como desenvolvedor?" Essas perguntas únicas geram múltiplas respostas de sim/não e precisam ser desmembradas em múltiplos recursos de sim/não.
Algumas perguntas de múltipla escolha como "Aproximadamente quantas pessoas trabalham na empresa ou organização para a qual você trabalha?" permitir respostas como "2-9 funcionários". Esses são efetivamente valores contínuos agrupados e pode ser útil mapeá-los de volta para valores contínuos inferidos como "2", para que o modelo possa considerar sua ordem e magnitude relativa. Infelizmente, esta tradução é manual e envolve algumas decisões subjetivas.
O código Apache Spark que pode realizar isso está no notebook que o acompanha, para os interessados.
Seleção de Modelo com Apache Spark
Com os dados em um formato mais amigável para Machine Learning, o próximo passo é ajustar um modelo de regressão que prevê o salário a partir desses recursos. O conjunto de dados em si, após a filtragem e a transformação com o Spark, tem apenas 4 MB, contendo 206 recursos de cerca de 12.600 desenvolvedores, e caberia facilmente na memória como um DataFrame no seu smartwatch, quanto mais em um servidor.
xgboost, um pacote popular de árvores de gradient boosting, pode ajustar um modelo a esses dados em minutos em uma única máquina, sem o Spark. xgboost oferece muitos "hiperparâmetros" ajustáveis que afetam a qualidade do modelo: profundidade máxima, taxa de aprendizado, regularização e assim por diante. Em vez de adivinhar, a prática padrão e simples é testar várias configurações desses valores e escolher a combinação que resulta no modelo mais preciso.
Felizmente, é aqui que o Spark entra novamente. Ele pode construir centenas desses modelos em paralelo e coletar os resultados de cada um. Como o conjunto de dados é pequeno, é simples transmiti-lo para os workers, criar várias combinações desses hiperparâmetros para testar e usar o Spark para aplicar o mesmo código xgboost simples e não distribuído que poderia construir um modelo localmente aos dados com cada combinação.
Isso criará muitos modelos. Para acompanhar e avaliar os resultados, o mlflow pode registrar cada um com suas métricas e hiperparâmetros e visualizá-los no Experimento do Notebook. Aqui, um hiperparâmetro em várias execuções é comparado com a acurácia resultante (erro absoluto médio):
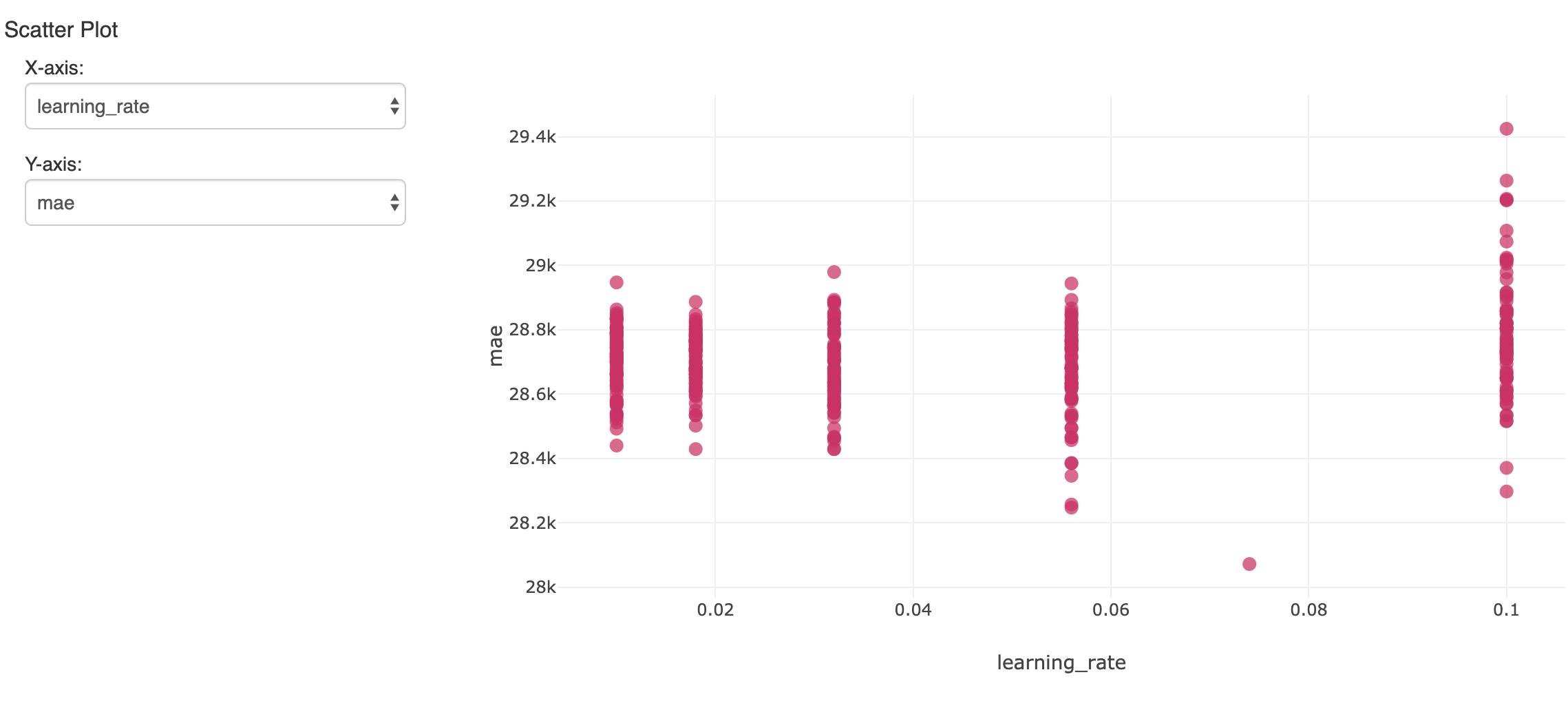
O único modelo que apresentou o menor erro no conjunto de dados de validação reservado é de interesse. Ele produziu um erro absoluto médio de cerca de US$ 28.000 em salários com média de cerca de US$ 119.000. Não é terrível, embora devamos perceber que o modelo só consegue explicar a maior parte da variação salarial.
Interpretando o modelo xgboost
Embora o modelo possa ser usado para prever salários futuros, a questão é o que o modelo diz sobre os dados. Que recursos parecem ser mais importantes para prever o salário com precisão? O próprio modelo xgboost computa uma noção de importância do recurso:
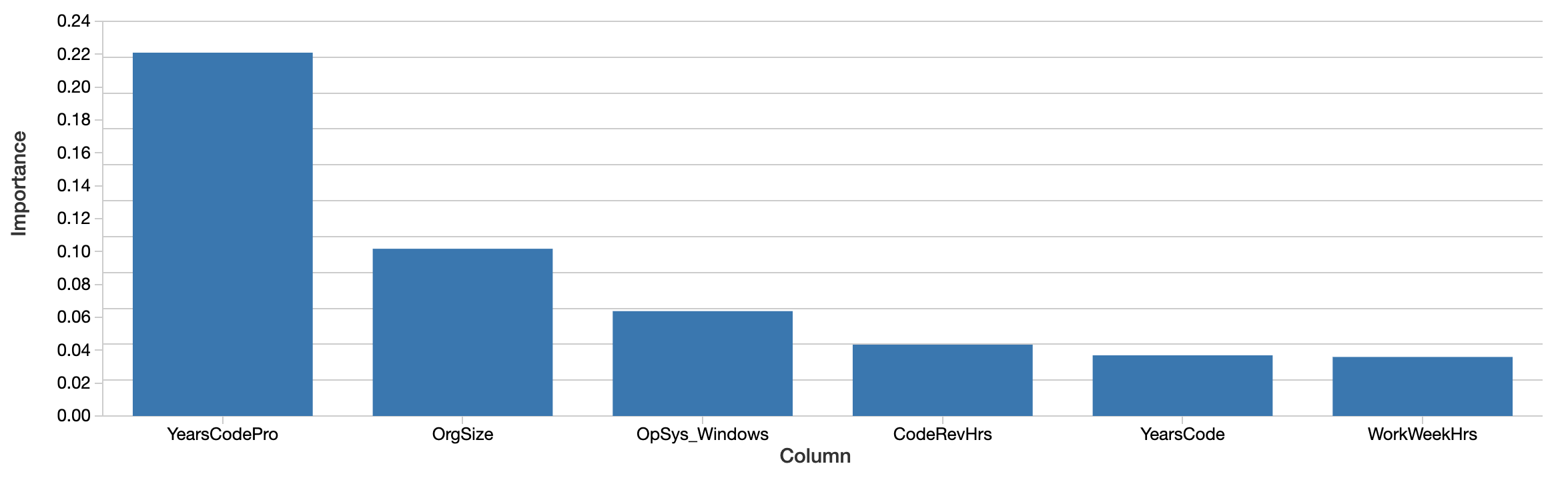
Fatores como anos de programação profissional, tamanho da organização e uso do Windows são os mais "importantes". Isso é interessante, mas difícil de interpretar. Os valores refletem a importância relativa, e não absoluta. Ou seja, o efeito não é medido em dólares. A definição de importância aqui (ganho total) também é específica de como as árvores de decisão são construídas e é difícil de mapear para uma interpretação intuitiva. Os recursos importantes nem sequer se correlacionam positivamente com o salário.
Mais importante, esta é uma 'global' view de quanto os recursos importam em conjunto. Fatores como gênero e etnia não aparecem nesta lista até mais adiante. Isso não significa que esses fatores não sejam ainda significativos. Para começar, os recursos podem estar correlacionados ou interagir. É possível que fatores como gênero se correlacionem com outros recursos que as árvores selecionaram, e isso, em certo grau, mascara o efeito deles.
A questão mais interessante não é tanto se esses fatores são importantes em geral - é possível que seu efeito médio seja relativamente pequeno - mas se eles têm um efeito significativo em alguns casos individuais. Esses são os casos em que o modelo está nos dizendo algo importante sobre a experiência dos indivíduos e, para esses indivíduos, essa experiência é o que importa.
Aplicando o pacote SHAP para explicações no nível do desenvolvedor
Felizmente, um conjunto de técnicas para uma interpretação de modelo teoricamente mais s�ólida no nível de previsão individual surgiu nos últimos cinco anos. Elas são coletivamente chamadas de "Shapley Additive Explanations" e, convenientemente, são implementadas no pacote Python shap.
Dado qualquer modelo, esta biblioteca computa os "valores SHAP" do modelo. Esses valores são facilmente interpretáveis, pois cada valor é o efeito de um recurso na predição, em suas unidades. Um valor SHAP de 1000 aqui significa "explicou +US$ 1.000 do salário previsto". Os valores SHAP são computados de uma forma que também tenta isolar a correlação e a interação.
Os valores SHAP também são computados para cada entrada, não para o modelo como um todo, portanto, essas explicações estão disponíveis para cada entrada individualmente. Ele também pode estimar o efeito das interações de recursos separadamente do efeito principal de cada recurso, para cada previsão.
IA explicável: descobrindo os efeitos gerais dos recursos
As explicações no nível do desenvolvedor podem se agregar em explicações dos efeitos dos recursos no salário sobre todo o conjunto de dados, simplesmente pela média de seus valores absolutos. A avaliação do SHAP sobre os recursos mais importantes em geral é semelhante:
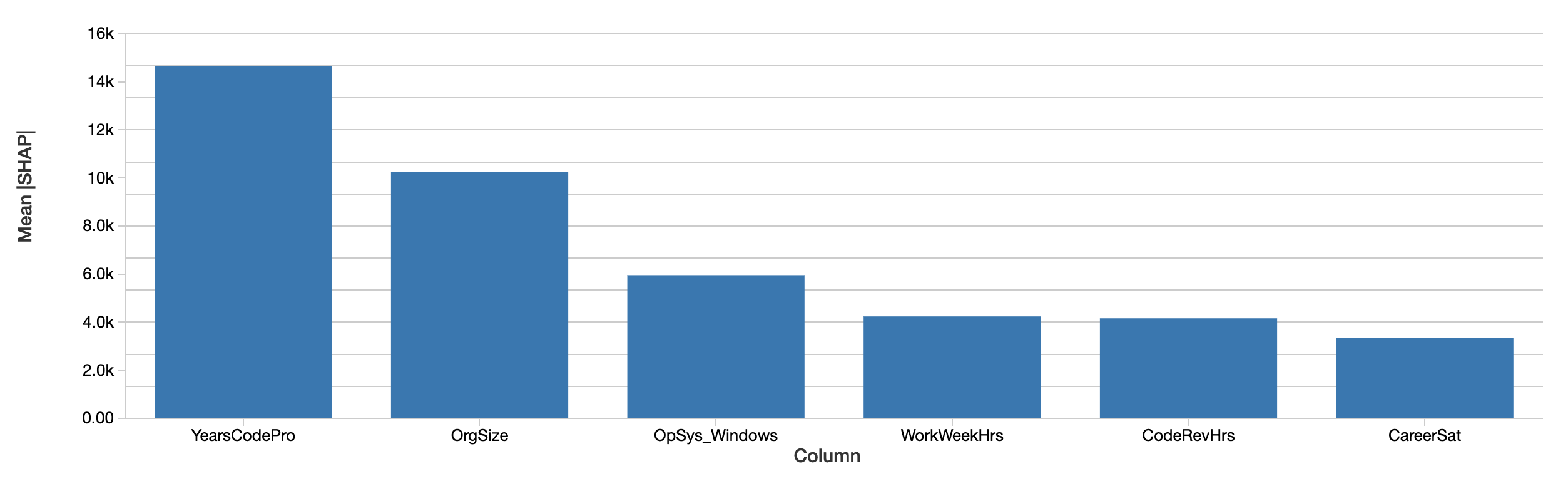
Os valores SHAP contam uma história semelhante. Primeiro, o SHAP é capaz de quantificar o efeito no salário em dólares, o que melhora muito a interpretação dos resultados. Acima está um gráfico do efeito absoluto de cada recurso no salário previsto, com média entre os desenvolvedores. Os anos de experiência profissional em programação ainda dominam, explicando, em média, um efeito de quase US$ 15.000 no salário.
Examinando os efeitos de gênero com valores SHAP
Analisamos especificamente os efeitos de gênero, raça e outros fatores que, supostamente, não deveriam ser preditivos do salário por si sós. Este exemplo examinará o efeito do gênero, embora isso não sugira de forma alguma que seja o único ou o mais importante tipo de viés a ser procurado.
Gênero não é binário, e a pesquisa reconhece respostas como "Homem", "Mulher" e "Não binário, genderqueer ou não conforme com o gênero", bem como "Trans" separadamente. (Observe que, embora a pesquisa também registre separadamente respostas sobre sexualidade, estas não são consideradas aqui.) O SHAP calcula o efeito no salário previsto para cada um destes. Para um desenvolvedor do sexo masculino (que se identifica apenas como homem), o efeito do gênero não é apenas o efeito de ser homem, mas de não se identificar como mulher, transgênero e assim por diante.
Os valores SHAP nos permitem observar a soma desses efeitos para desenvolvedores que se identificam com cada uma das quatro categorias:

Enquanto o gênero dos desenvolvedores do sexo masculino explica cerca de modestos -$230 a +$890 com uma média de cerca de $225, para as mulheres, o intervalo é mais amplo, de cerca de -$4.260 a -$690 com uma média de -$1.320. Os resultados para desenvolvedores transgêneros e não binários são semelhantes, embora um pouco menos negativos.
Ao avaliar o que isso significa abaixo, é importante lembrar as limitações dos dados e do modelo aqui:
- Correlação não é causalidade; 'explicar' o salário previsto é sugestivo, mas não prova que um recurso tenha causado diretamente o aumento ou a diminuição do salário
- O modelo não é perfeitamente preciso
- Estes são dados de apenas 1 ano, e apenas de desenvolvedores dos EUA
- Isso reflete apenas o salário-base, não bônus ou ações, que podem variar mais amplamente.
Usando o SHAP para visualizar recursos que interagem com gênero
A biblioteca SHAP oferece visualizações interessantes que aproveitam sua capacidade de isolar o efeito das interações de recursos. Por exemplo, os valores acima sugerem que desenvolvedores que se identificam como do sexo masculino têm a previsão de receber um salário um pouco maior do que outros, mas será que é só isso? Um gráfico de dependência como este pode ajudar:
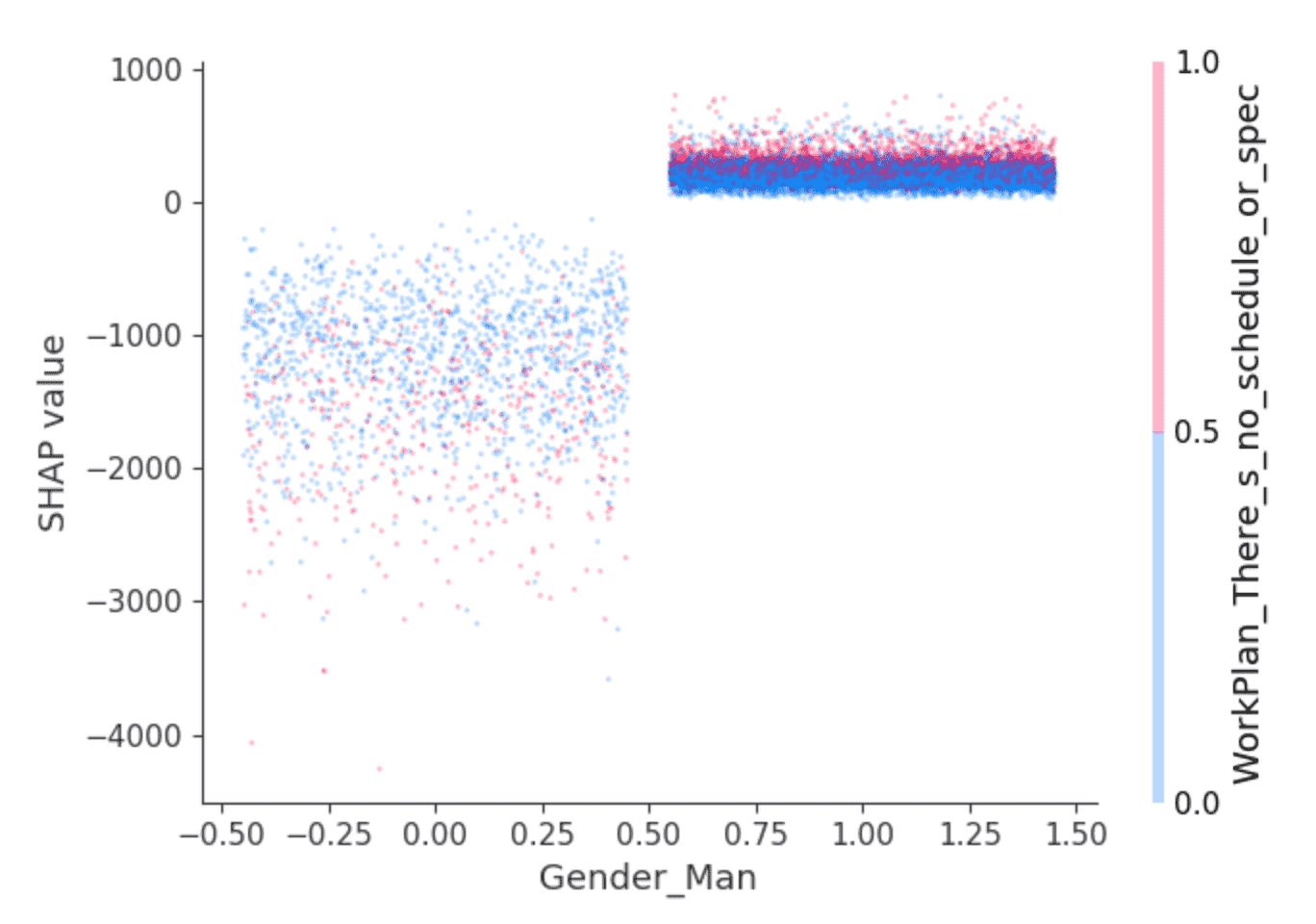
Os pontos são desenvolvedores. Os desenvolvedores à esquerda são aqueles que não se identificam como homens e, à direita, aqueles que se identificam, que são predominantemente aqueles que se identificam apenas como homens. (Os pontos são distribuídos aleatoriamente na horizontal para maior clareza.) O eixo y é o valor SHAP, ou o que se identificar como homem ou não explica sobre o salário previsto para cada desenvolvedor. Como acima, aqueles que não se identificam como homens apresentam valores SHAP negativos no geral, e que variam amplamente, enquanto outros mostram consistentemente um pequeno valor SHAP positivo.
O que está por trás dessa variação? O SHAP pode selecionar um segundo recurso cujo efeito mais varia dado o valor de, aqui, identificar-se como homem ou não. Ele seleciona a resposta "Eu trabalho no que parece mais importante ou urgente" para a pergunta "Quão estruturado ou planejado é o seu trabalho?" Entre os desenvolvedores que se identificam como homens, aqueles que responderam dessa forma (pontos vermelhos) parecem ter valores SHAP ligeiramente mais altos. Entre os demais, o efeito é mais misto, mas parece ter valores SHAP geralmente mais baixos.
A interpretação fica a critério do leitor, mas talvez: os desenvolvedores do sexo masculino que se sentem empoderados nesse sentido também estão desfrutando de salários um pouco mais altos, enquanto para outros desenvolvedores isso anda de mãos dadas com cargos de menor remuneração?
Explorando instâncias com efeitos de gênero desproporcionais
Que tal investigar o desenvolvedor cujo salário é mais afetado negativamente? Assim como é possível observar o efeito geral dos recursos relacionados ao gênero, é possível pesquisar o desenvolvedor cujos recursos relacionados ao gênero tiveram o maior impacto no salário previsto. Essa pessoa é do sexo feminino e o efeito é negativo. De acordo com o modelo, a previsão é que ela ganhe cerca de US$ 4.260 a menos por ano por causa de seu gênero:

O salário previsto, pouco mais de US$ 157.000, preciso neste caso, pois o salário real informado por ela é de US$ 150.000.
Os três recursos mais positivos e negativos que influenciam o salário previsto são que ela:
- Tem diploma universitário (apenas) (+US$ 18.200)
- Tem 10 anos de experiência profissional (+$9.400)
- Identifica-se como Leste Asiático (+$9,100)
- ...
- Trabalha 40 horas por semana (-$4,000)
- Não se identifica como homem (-$4.250)
- Trabalha em uma organização de médio porte de 100 a 499 funcionários (-$9.700)
Dada a magnitude do efeito no salário previsto de não se identificar como homem, podemos parar por aqui e investigar os detalhes deste caso offline para entender melhor o contexto em torno deste desenvolvedor e se sua experiência, ou salário, ou ambos, precisam de uma mudança.
Explicando interações usando valores SHAP
Há mais detalhes disponíveis dentro desses -US$ 4.260. O SHAP pode decompor os efeitos desses recursos em interações. O efeito total de se identificar como mulher na predição pode ser decomposto no efeito de se identificar como mulher e ser gerente de engenharia, e trabalhar com o Windows, etc.
O efeito no salário previsto, explicado pelos fatores de gênero em si, soma apenas cerca de -$630. Em vez disso, o SHAP atribui a maioria dos efeitos de gênero a interações com outros recursos:
Identificar-se como mulher e trabalhar com PostgreSQL afeta o salário previsto de forma ligeiramente positiva, enquanto identificar-se também como asiático oriental afeta o salário previsto de forma mais negativa. Interpretar esses valores neste nível de granularidade é difícil neste contexto, mas este nível adicional de explicação está disponível.
Aplicando SHAP com Apache Spark
Os valores SHAP são calculados de forma independente para cada linha, considerando o modelo, e, portanto, isso também poderia ter sido feito em paralelo com o Spark. O exemplo a seguir computa os valores SHAP em paralelo e, da mesma forma, localiza desenvolvedores com valores SHAP desproporcionais relacionados a gênero:
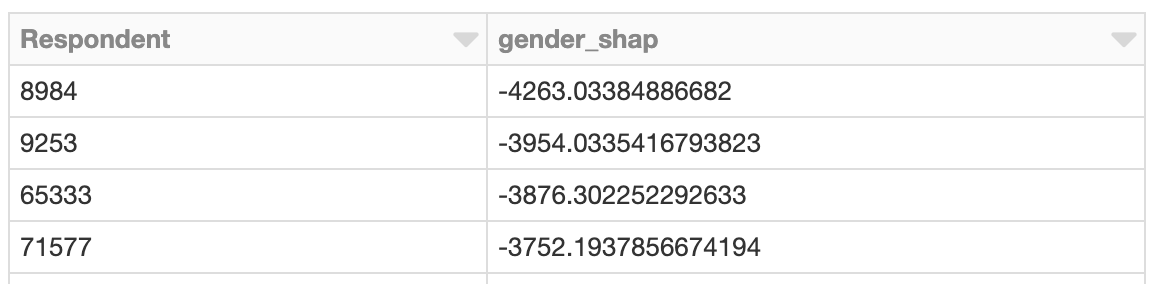
Agrupamento de valores SHAP
Aplicar o Spark é vantajoso quando há um grande número de previsões para avaliar com o SHAP. Dada essa saída, também é possível usar o Spark para agrupar os resultados com, por exemplo, o k-means bissetorial:
O cluster cujos efeitos totais do SHAP relacionados a gênero são mais negativos pode merecer uma investigação mais aprofundada. Quais são os valores SHAP dos respondentes no cluster? Qual é a aparência dos membros do cluster em relação à população geral de desenvolvedores?
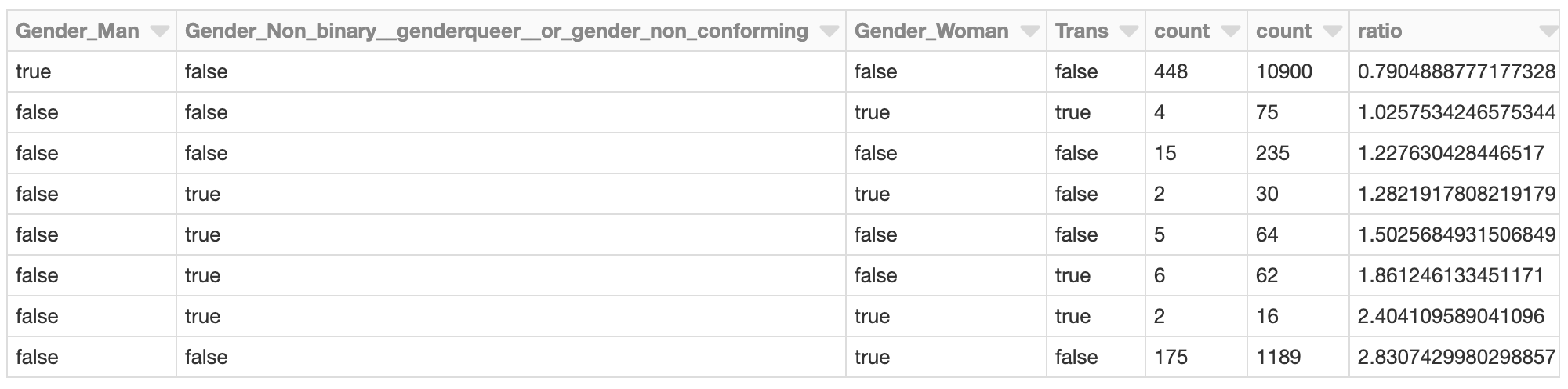
Desenvolvedoras que se identificam apenas como mulheres, por exemplo, são representadas neste cluster a uma taxa quase 2,8 vezes maior que a da população geral de desenvolvedores. Isso não é surpreendente, dada a análise anterior. Este cluster poderia ser investigado mais a fundo para avaliar outros fatores específicos deste grupo que contribuem para um salário previsto geral mais baixo.
Conclusão
Este tipo de análise com SHAP pode ser executado para qualquer modelo e também em escala. Como uma ferramenta analítica, ele transforma modelos em detetives de dados, para revelar instâncias individuais cujas predições sugerem que merecem um exame mais aprofundado. A saída do SHAP é facilmente interpretável e produz gráficos intuitivos, que podem ser avaliados caso a caso pelos usuários de negócios.
Claro, esta análise não se limita a examinar questões de viés de gênero, idade ou raça. Em termos mais práticos, isso poderia ser aplicado a modelos de churn de clientes. Nesse caso, a pergunta não é apenas "este cliente vai cancelar?", mas sim "por que o cliente está cancelando?" Um cliente que está cancelando por causa do preço pode receber uma oferta de desconto, enquanto um que está cancelando devido ao uso limitado pode precisar de um upsell.
Finalmente, esta análise pode ser executada como parte de um processo de validação, trazendo maior transparência para o modelo do machine learning como um todo. A validação de modelos geralmente foca na precisão geral de um modelo. Ela também deve focar no 'raciocínio' do modelo, ou em quais recursos mais contribuíram para as previsões. Com o SHAP, também pode ajudar a detectar quando muitas explicações de previsões individuais estão em desacordo com a importância geral dos recursos.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.