Execução Adaptativa de Consultas: Acelerando o Spark SQL em Tempo de Execução
Leia Rise of the Data Lakehouse para explorar por que os lakehouses são a arquitetura de dados do futuro com o pai do data warehouse, Bill Inmon.
Este é um esforço conjunto de engenharia entre a equipe de engenharia do Databricks Apache Spark — Wenchen Fan, Herman van Hovell e MaryAnn Xue — e a equipe de engenharia da Intel —Ke Jia, Haifeng Chen e Carson Wang.
Veja o notebook do AQE para demonstrar a solução abordada abaixo ou mergulhe mais fundo no funcionamento interno da Databricks Lakehouse Platform
Ao longo dos anos, houve um esforço contínuo e extenso para melhorar o otimizador de consultas e o planejador do Spark SQL, a fim de gerar planos de execução de consultas de alta qualidade. Uma das maiores melhorias é o framework de otimização baseado em custo, que coleta e utiliza uma variedade de estatísticas de dados (por exemplo, contagem de linhas, número de valores distintos, valores NULL, valores máximo/mínimo, etc.) para ajudar o Spark a escolher melhores planos. Exemplos dessas técnicas de otimização baseadas em custo incluem a escolha do tipo de join correto (broadcast hash join vs. sort merge join), a seleção do lado de build correto em um hash-join ou o ajuste da ordem de join em um multi-way join. No entanto, estatísticas desatualizadas e estimativas de cardinalidade imperfeitas podem levar a planos de consulta subótimos. A Execução Adaptativa de Consultas (Adaptive Query Execution - AQE), nova na próxima versão do Apache SparkTM 3.0 e disponível no Databricks Runtime 7.0, agora busca resolver esses problemas, reotimizando e ajustando planos de consulta com base em estatísticas de tempo de execução coletadas no processo de execução da consulta.
O framework de Execução Adaptativa de Consultas (AQE)
Uma das perguntas mais importantes para a Execução Adaptativa de Consultas é quando reotimizar. Operadores do Spark são frequentemente encadeados e executados em processos paralelos. No entanto, um shuffle ou broadcast exchange quebra esse pipeline. Chamamos isso de pontos de materialização e usamos o termo "query stages" para denotar subseções delimitadas por esses pontos de materialização em uma consulta. Cada query stage materializa seu resultado intermediário e o stage seguinte só pode prosseguir se todos os processos paralelos executando a materialização tiverem sido concluídos. Isso fornece uma oportunidade natural para reotimização, pois é quando as estatísticas de dados de todas as partições estão disponíveis e as operações subsequentes ainda não começaram.
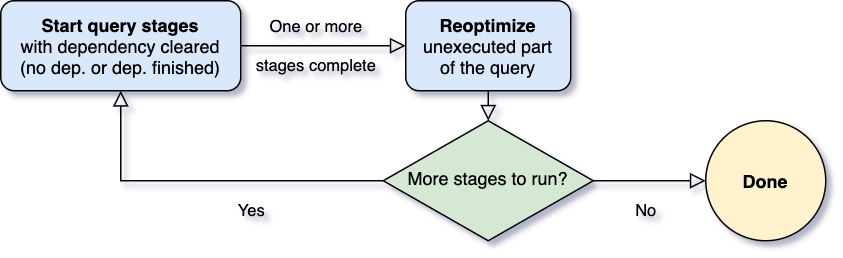
Quando a consulta começa, o framework de Execução Adaptativa de Consultas primeiro inicia todos os leaf stages — os stages que não dependem de nenhum outro stage. Assim que um ou mais desses stages terminam a materialização, o framework os marca como concluídos no plano de consulta físico e atualiza o plano de consulta lógico de acordo, com as estatísticas de tempo de execução recuperadas dos stages concluídos. Com base nessas novas estatísticas, o framework executa o otimizador (com uma lista selecionada de regras de otimização lógica), o planejador físico, bem como as regras de otimização física, que incluem as regras físicas regulares e as regras específicas de execução adaptativa, como coalescência de partições, tratamento de skew joins, etc. Agora que temos um plano de consulta recém-otimizado com alguns stages concluídos, o framework de execução adaptativa buscará e executará novos query stages cujos child stages foram todos materializados, e repetirá o processo acima de executar-reotimizar-executar até que a consulta inteira seja concluída.
No Spark 3.0, o framework AQE vem com três recursos:
- Coalescência dinâmica de partições de shuffle
- Troca dinâmica de estratégias de join
- Otimização dinâmica de skew joins
As seções a seguir detalharão esses três recursos.
Coalescência dinâmica de partições de shuffle
Ao executar consultas no Spark para lidar com dados muito grandes, o shuffle geralmente tem um impacto muito importante no desempenho da consulta, entre outras coisas. O Shuffle é um operador caro, pois precisa mover dados pela rede, de modo que os dados sejam redistribuídos da maneira exigida pelos operadores downstream.
Uma propriedade chave do shuffle é o número de partições. O número ideal de partições depende dos dados, mas os tamanhos dos dados podem variar muito de stage para stage, de consulta para consulta, tornando esse número difícil de ajustar:
- Se houver poucas partições, o tamanho dos dados de cada partição pode ser muito grande, e as tarefas para processar essas partições grandes podem precisar despejar dados em disco (por exemplo, quando sort ou aggregate está envolvido) e, como resultado, desacelerar a consulta.
- Se houver muitas partições, o tamanho dos dados de cada partição pode ser muito pequeno, e haverá muitas leituras de pequenos blocos de dados de rede, o que também pode desacelerar a consulta devido ao padrão de E/S ineficiente. Ter um grande número de tarefas também sobrecarrega o agendador de tarefas do Spark.
Para resolver esse problema, podemos definir um número relativamente grande de partições de shuffle no início e, em seguida, combinar partições pequenas adjacentes em partições maiores em tempo de execução, examinando as estatísticas dos arquivos de shuffle.
Por exemplo, digamos que estamos executando a consulta SELECT max(i)FROM tbl GROUP BY j. Os dados de entrada tbl são relativamente pequenos, então há apenas duas partições antes do agrupamento. O número inicial de partições de shuffle é definido como cinco, então, após o agrupamento local, os dados parcialmente agrupados são embaralhados em cinco partições. Sem AQE, o Spark iniciará cinco tarefas para fazer a agregação final. No entanto, existem três partições muito pequenas aqui, e seria um desperdício iniciar uma tarefa separada para cada uma delas.
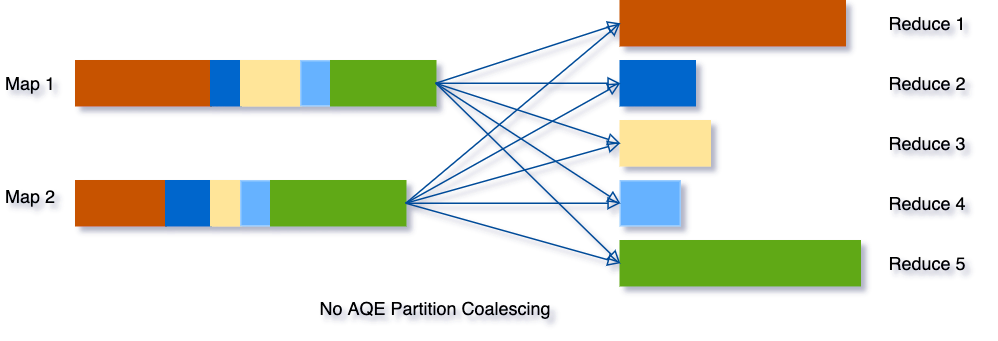
Em vez disso, o AQE une essas três partições pequenas em uma e, como resultado, a agregação final agora precisa realizar apenas três tarefas em vez de cinco.

Troca dinâmica de estratégias de join
O Spark suporta várias estratégias de join, entre as quais o broadcast hash join é geralmente o mais performático se um lado do join couber bem na memória. E por esse motivo, o Spark planeja um broadcast hash join se o tamanho estimado de uma relação de join for menor que o limite de tamanho de broadcast. Mas várias coisas podem fazer com que essa estimativa de tamanho dê errado — como a presença de um filtro muito seletivo — ou a relação de join ser uma série de operadores complexos além de um simples scan.
Para resolver esse problema, o AQE agora replaneja a estratégia de join em tempo de execução com base no tamanho mais preciso da relação de join. Como pode ser visto no exemplo a seguir, o lado direito do join é encontrado como sendo bem menor que a estimativa e também pequeno o suficiente para ser transmitido (broadcast), então, após a reotimização do AQE, o sort merge join planejado estaticamente é agora convertido para um broadcast hash join.
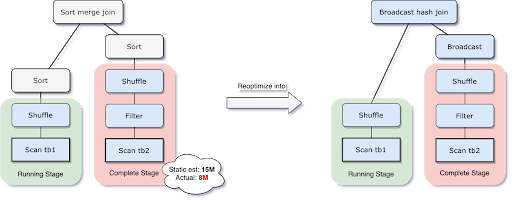
Para o broadcast hash join convertido em tempo de execução, podemos otimizar ainda mais o shuffle regular para um shuffle localizado (ou seja, shuffle que lê por mapper em vez de por reducer) para reduzir o tráfego de rede.
Otimização dinâmica de skew joins
O skew de dados ocorre quando os dados são distribuídos de forma desigual entre as partições no cluster. Skew severo pode degradar significativamente o desempenho da consulta, especialmente com joins. A otimização de skew join do AQE detecta esse skew automaticamente a partir das estatísticas de arquivos de shuffle. Em seguida, ele divide as partições com skew em subpartições menores, que serão unidas à partição correspondente do outro lado, respectivamente.
Vamos pegar este exemplo da tabela A unindo a tabela B, na qual a tabela A tem uma partição A0 significativamente maior que suas outras partições.
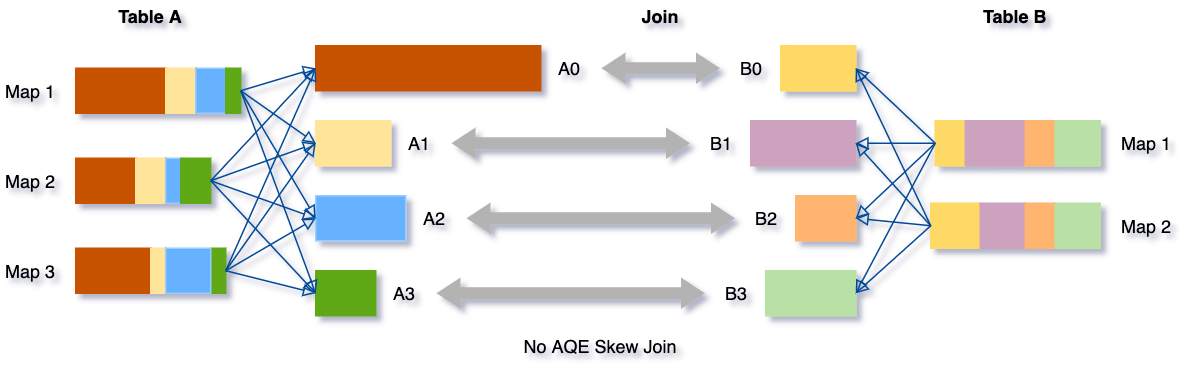
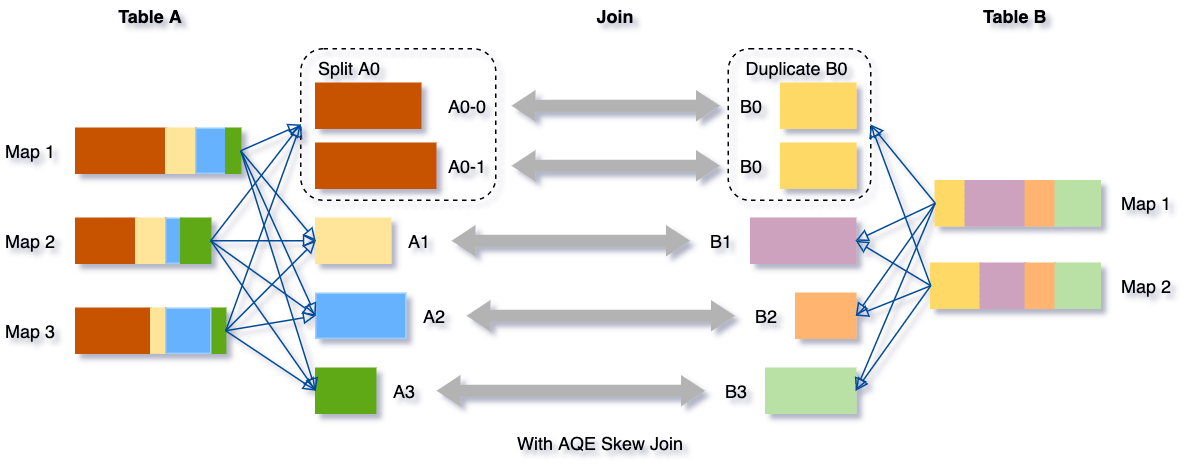
Sem essa otimização, haveria quatro tarefas executando o sort merge join, com uma tarefa levando muito mais tempo. Após essa otimização, haverá cinco tarefas executando o join, mas cada tarefa levará aproximadamente a mesma quantidade de tempo, resultando em um desempenho geral melhor.
Ganhos de desempenho TPC-DS com AQE
Em nossos experimentos usando dados e consultas TPC-DS, a Execução Adaptativa de Consultas (AQE) gerou um aumento de até 8x no desempenho das consultas, e 32 consultas tiveram um aumento de mais de 1,1x. Abaixo está um gráfico das 10 consultas TPC-DS com maior melhoria de desempenho pela AQE.
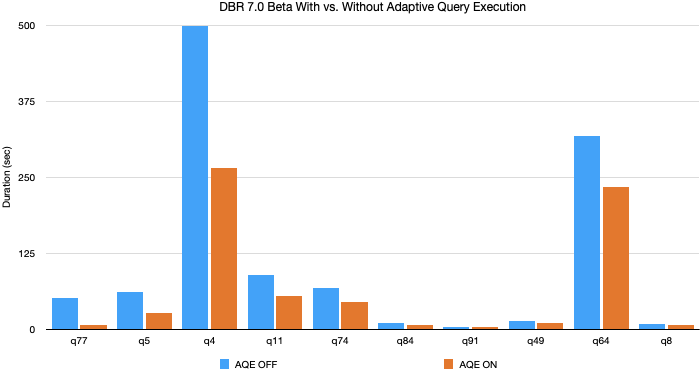
A maioria dessas melhorias veio da coalescência dinâmica de partições e da troca dinâmica de estratégia de join, pois os dados TPC-DS gerados aleatoriamente não têm skew. No entanto, vimos melhorias ainda maiores em cargas de trabalho de produção, onde todos os três recursos da AQE são aproveitados.
Habilitando a AQE
A AQE pode ser habilitada definindo a configuração SQL spark.sql.adaptive.enabled como true (padrão false no Spark 3.0) e se aplica se a consulta atender aos seguintes critérios:
- Não é uma consulta de streaming
- Contém pelo menos uma troca (geralmente quando há um operador de join, agregação ou janela) ou uma subconsulta
Ao tornar a otimização de consultas menos dependente de estatísticas estáticas, a AQE resolveu uma das maiores dificuldades da otimização baseada em custo do Spark — o equilíbrio entre o overhead da coleta de estatísticas e a precisão da estimativa. Para alcançar a melhor precisão de estimativa e resultado de planejamento, geralmente é necessário manter estatísticas detalhadas e atualizadas, e algumas delas são caras para coletar, como histogramas de colunas, que podem ser usados para melhorar a estimativa de seletividade e cardinalidade ou para detectar skew de dados. A AQE eliminou em grande parte a necessidade de tais estatísticas, bem como o esforço de ajuste manual. Além disso, a AQE também tornou a otimização de consultas SQL mais resiliente à presença de UDFs arbitrárias e a mudanças imprevisíveis no conjunto de dados, por exemplo, aumento ou diminuição repentina no tamanho dos dados, skew de dados frequente e aleatório, etc. Não há mais necessidade de "conhecer" seus dados com antecedência. A AQE descobrirá os dados e melhorará o plano de consulta enquanto a consulta é executada, aumentando o desempenho da consulta para análises mais rápidas e o desempenho do sistema.
Saiba mais sobre o Spark 3.0 em nosso webinar de prévia. Experimente a AQE no Spark 3.0 hoje mesmo gratuitamente no Databricks como parte do nosso Databricks Runtime 7.0.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.