Impondo Criptografia em Nível de Coluna e Evitando Duplicação de Dados com PII
Usando bibliotecas de criptografia Fernet, UDFs e segredos do Databricks para proteger dados de PII de forma discreta
por Keyuri Shah e Fred Kimball
Este é um post convidado de Keyuri Shah, engenheira de software líder, e Fred Kimball, engenheiro de software, Northwestern Mutual.
Proteger PII (informações de identificação pessoal) é muito importante, pois o número de violações de dados e registros com informações confidenciais expostas a cada dia está em tendência de alta. Para evitar nos tornarmos a próxima vítima e proteger os usuários contra roubo de identidade e fraudes, precisamos incorporar várias camadas de segurança de dados e informações.
Como usamos a plataforma Databricks, precisamos garantir que estamos permitindo que apenas as pessoas certas acessem informações confidenciais. Usando uma combinação de bibliotecas de criptografia Fernet, funções definidas pelo usuário (UDFs) e segredos do Databricks, a Northwestern Mutual desenvolveu um processo para criptografar informações de PII e permitir que apenas aqueles com necessidade comercial as decifrem, sem etapas adicionais necessárias para o leitor de dados.
A necessidade de proteger PII
Gerenciar qualquer quantidade de dados de clientes hoje em dia quase certamente requer a proteção de PII. Este é um grande risco para organizações de todos os tamanhos, pois casos como a violação de dados da Capital One resultaram no roubo de milhões de registros confidenciais de clientes devido a um simples erro de configuração. Embora a criptografia do dispositivo de armazenamento e a mascaramento de colunas em nível de tabela sejam medidas de segurança eficazes, o acesso interno não autorizado a esses dados confidenciais ainda representa uma grande ameaça. Portanto, precisamos de uma solução que restrinja um usuário normal com acesso a arquivos ou tabelas de recuperar informações confidenciais dentro do Databricks.
No entanto, também precisamos que aqueles com necessidade comercial possam ler informações confidenciais. Não queremos que haja diferença na forma como cada tipo de usuário lê a tabela. Leituras normais e decifradas devem ocorrer no mesmo objeto Delta Lake para simplificar a construção de consultas para análise de dados e construção de relatórios.
Construindo o processo para impor criptografia em nível de coluna
Dadas essas exigências de segurança, buscamos criar um processo que fosse seguro, discreto e fácil de gerenciar. O diagrama abaixo fornece uma visão geral de alto nível dos componentes necessários para este processo
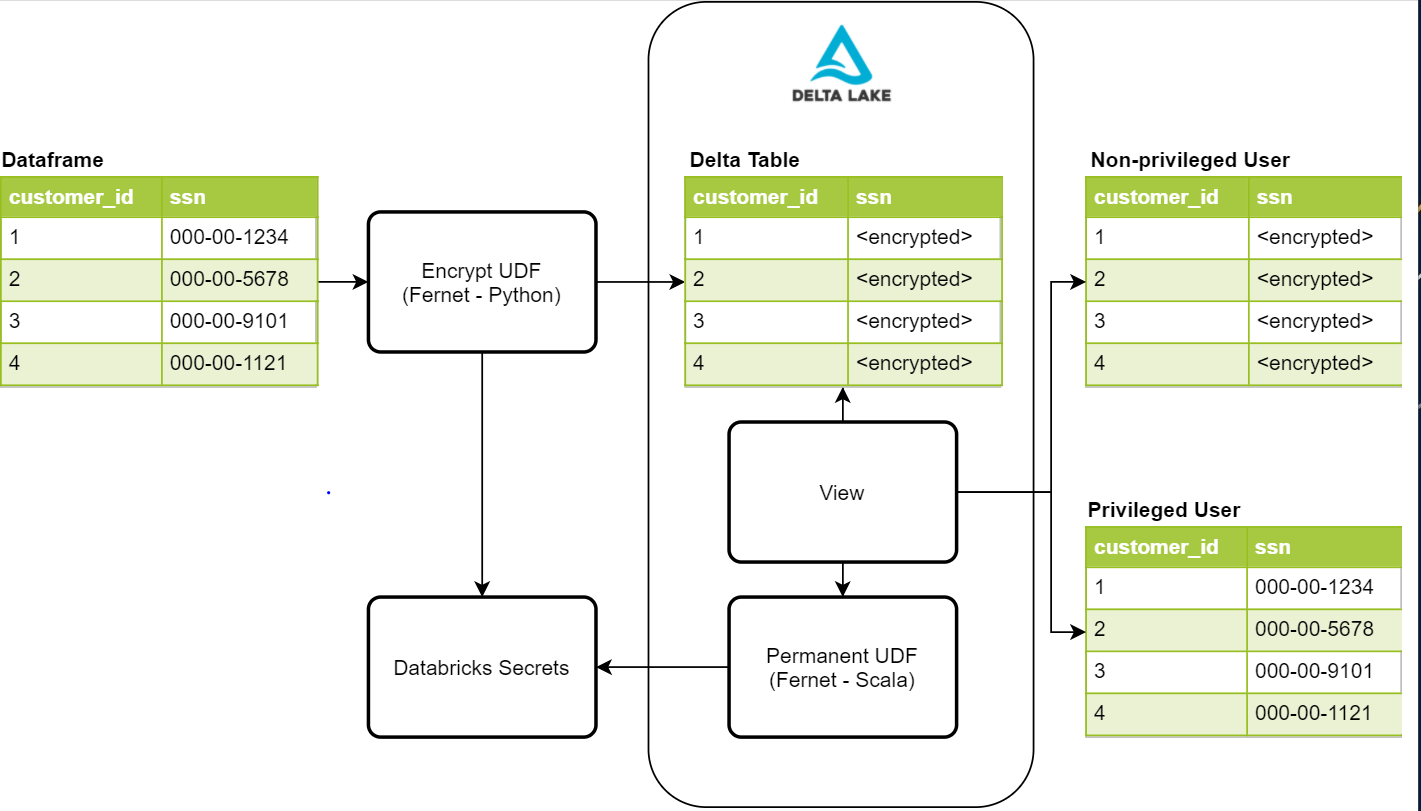
Escrevendo PII protegida com Fernet
O primeiro passo neste processo é proteger os dados criptografando-os. Uma solução possível é a biblioteca Python Fernet. Fernet usa criptografia simétrica, que é construída com vários primitivos criptográficos padrão. Esta biblioteca é usada dentro de uma UDF de criptografia que nos permitirá criptografar qualquer coluna em um dataframe. Para armazenar a chave de criptografia, usamos Segredos do Databricks com controles de acesso para permitir que apenas nosso processo de ingestão de dados o acesse. Uma vez que os dados são gravados em nossas tabelas Delta Lake, colunas de PII contendo valores como número de seguridade social, número de telefone, número de cartão de crédito e outros identificadores serão impossíveis de serem lidos por um usuário não autorizado.
Lendo os dados protegidos de uma view com UDF personalizada
Depois de termos os dados confidenciais gravados e protegidos, precisamos de uma maneira para que usuários privilegiados leiam os dados confidenciais. A primeira coisa a ser feita é criar uma UDF permanente para adicionar à instância Hive em execução no Databricks. Para que uma UDF seja permanente, ela deve ser escrita em Scala. Felizmente, Fernet também tem uma implementação Scala que podemos usar para nossas leituras decifradas. Esta UDF também acessa o mesmo segredo que usamos na gravação criptografada para realizar a decifragem e, neste caso, é adicionada à configuração do Spark do cluster. Isso exige que adicionemos controles de acesso ao cluster para usuários privilegiados e não privilegiados para controlar seu acesso à chave. Uma vez criada a UDF, podemos usá-la em nossas definições de view para que usuários privilegiados vejam os dados decifrados.
Atualmente, temos dois objetos de view para um único conjunto de dados, um para usuários privilegiados e outro para não privilegiados. A view para usuários não privilegiados não possui a UDF, então eles verão os valores de PII como valores criptografados. A outra view para usuários privilegiados possui a UDF, então eles podem ver os valores decifrados em texto simples para suas necessidades comerciais. O acesso a essas views também é controlado pelos controles de acesso à tabela fornecidos pelo Databricks.
Em um futuro próximo, queremos alavancar um novo recurso do Databricks chamado funções de view dinâmicas. Essas funções de view dinâmicas nos permitirão usar apenas uma view e retornar facilmente os valores criptografados ou decifrados com base no grupo do Databricks do qual eles são membros. Isso reduzirá a quantidade de objetos que estamos criando em nosso Delta Lake e simplificará nossas regras de controle de acesso à tabela.
Qualquer uma das implementações permite que os usuários façam seu desenvolvimento ou análise sem se preocupar se precisam ou não decifrar valores lidos da view e permite o acesso apenas àqueles com necessidade comercial.
Vantagens deste método de criptografia em nível de coluna
Em resumo, as vantagens de usar este processo são:
- A criptografia pode ser realizada usando bibliotecas Python ou Scala existentes
- Dados de PII confidenciais têm uma camada adicional de segurança ao serem armazenados no Delta Lake
- O mesmo objeto Delta Lake é usado por usuários com todos os níveis de acesso a tal objeto
- Analistas não são obstruídos, quer estejam ou não autorizados a ler PII
Como exemplo do que isso pode parecer, o notebook a seguir pode fornecer alguma orientação:
Recursos adicionais:
Bibliotecas Fernet
Criar UDF Permanente
Funções de View Dinâmicas
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.