Como Simplificar CDC com o Change Data Feed do Delta Lake
por Surya Sai Turaga e John O'Dwyer
Experimente este notebook no Databricks
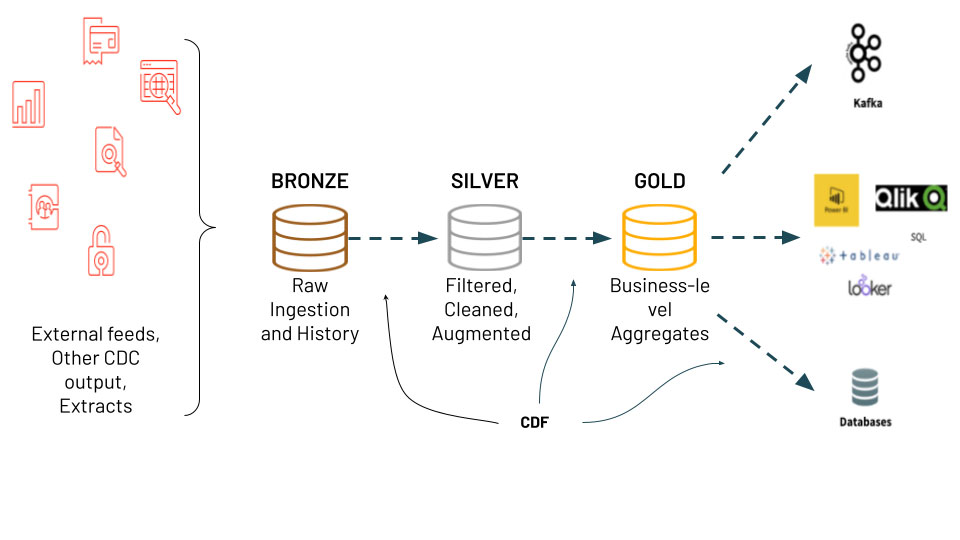
Change data capture (CDC) é um caso de uso que vemos muitos clientes implementarem no Databricks – você pode conferir nosso deep dive anterior sobre o tópico aqui. Normalmente, vemos o CDC sendo usado em uma arquitetura de ingestão para análise chamada arquitetura medallion. A arquitetura medallion pega dados brutos carregados de sistemas de origem e refina os dados através de tabelas bronze, silver e gold. O CDC e a arquitetura medallion oferecem múltiplos benefícios aos usuários, pois apenas dados alterados ou adicionados precisam ser processados. Além disso, as diferentes tabelas na arquitetura permitem que diferentes personas, como Cientistas de Dados e Analistas de BI, usem os dados corretos e atualizados para suas necessidades. Temos o prazer de anunciar o novo e empolgante recurso Change Data Feed (CDF) no Delta Lake, que torna essa arquitetura mais simples de implementar e possibilita a operação MERGE e o versionamento de log do Delta Lake!
Obtenha uma prévia antecipada do novo ebook da O'Reilly com o guia passo a passo que você precisa para começar a usar o Delta Lake.
Por que o recurso CDF é necessário?
Muitos clientes usam o Databricks para realizar CDC, pois é mais simples de implementar com o Delta Lake em comparação com outras tecnologias de Big Data. No entanto, mesmo com as ferramentas certas, o CDC ainda pode ser desafiador de executar. Projetamos o CDF para tornar a codificação ainda mais simples e abordar os maiores pontos problemáticos em torno do CDC, incluindo:
- Controle de Qualidade - Alterações em nível de linha são difíceis de obter entre versões.
- Ineficiência - Pode ser ineficiente contabilizar linhas que não foram alteradas, pois as alterações da versão atual são em nível de arquivo e não de linha.
Veja como a implementação do Change Data Feed (CDF) ajuda a resolver os problemas acima:
- Simplicidade e conveniência - Usa um padrão comum e fácil de usar para identificar alterações, tornando seu código simples, conveniente e fácil de entender.
- Eficiência - A capacidade de ter apenas as linhas que foram alteradas entre as versões torna o consumo downstream das operações Merge, Update e Delete extremamente eficiente.
O CDF captura alterações apenas de uma tabela Delta e é apenas prospectivo após ser habilitado.
Change Data Feed em Ação!
Vamos mergulhar em um exemplo de CDF para um caso de uso comum: previsões financeiras. O notebook referenciado no topo deste blog ingere dados financeiros. Estimated Earnings Per Share (EPS) são dados financeiros de analistas prevendo o lucro por ação trimestral de uma empresa. Os dados brutos podem vir de muitas fontes diferentes e de múltiplos analistas para várias ações.
Com o recurso CDF, os dados são simplesmente inseridos na tabela bronze (ingestão bruta), depois filtrados, limpos e aumentados na tabela silver e, finalmente, os valores agregados são computados na tabela gold com base nos dados alterados na tabela silver.
Embora essas transformações possam se tornar complexas, felizmente, agora o recurso CDF baseado em linha é simples e eficiente. Mas como usá-lo? Vamos investigar!
NOTA: O exemplo aqui foca na versão SQL do CDF e também em uma maneira específica de usar as operações, para avaliar variações, consulte a documentação aqui
Habilitando o CDF em uma Tabela Delta Lake
Para ter o recurso CDF disponível em uma tabela, você deve primeiro habilitar o recurso nessa tabela. Abaixo está um exemplo de habilitação do CDF para a tabela bronze na criação da tabela. Você também pode habilitar o CDF em uma tabela como uma atualização da tabela. Além disso, você pode habilitar o CDF em um cluster para todas as tabelas criadas pelo cluster. Para essas variações, consulte a documentação aqui.

O Change Data Feed é um recurso prospectivo, ele capturará alterações assim que a propriedade da tabela for configurada e não antes.
Consultando os dados de alteração
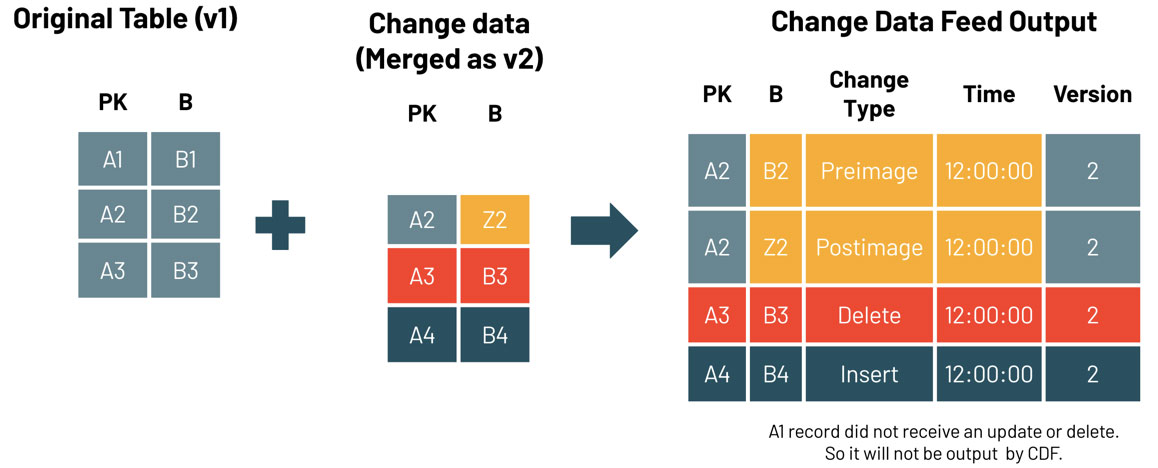
Para consultar os dados de alteração, use a operação table_changes. O exemplo abaixo inclui linhas inseridas e duas linhas que representam a imagem pré e pós de uma linha atualizada, para que possamos avaliar as diferenças nas alterações, se necessário. Há também um Tipo de Alteração delete que é retornado para linhas excluídas.
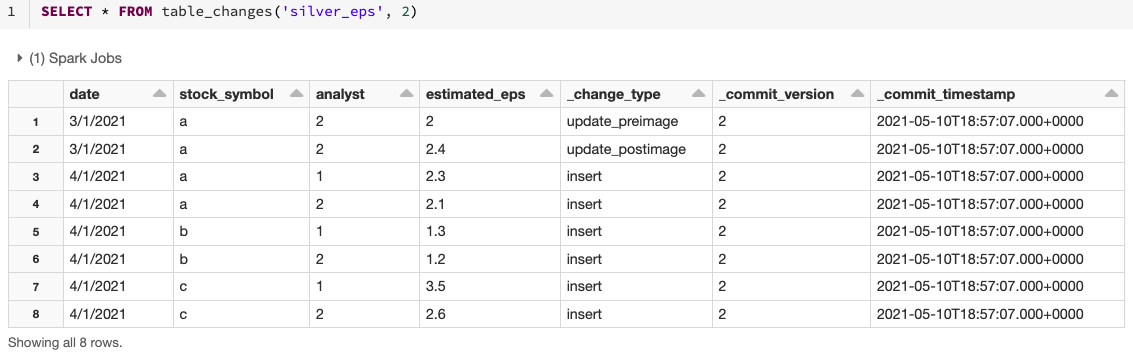
Este exemplo acessa os registros alterados com base na versão inicial, mas você também pode limitar as versões com base na versão final, bem como em timestamps inicial e final, se necessário. Este exemplo foca em SQL, mas também existem maneiras de acessar esses dados em Python, Scala, Java e R. Para essas variações, consulte a documentação aqui.
Usando dados de linha do CDF em uma instrução MERGE
Instruções MERGE agregadas, como o merge na tabela gold, podem ser complexas por natureza, mas o recurso CDF torna a codificação dessas instruções mais simples e eficiente.
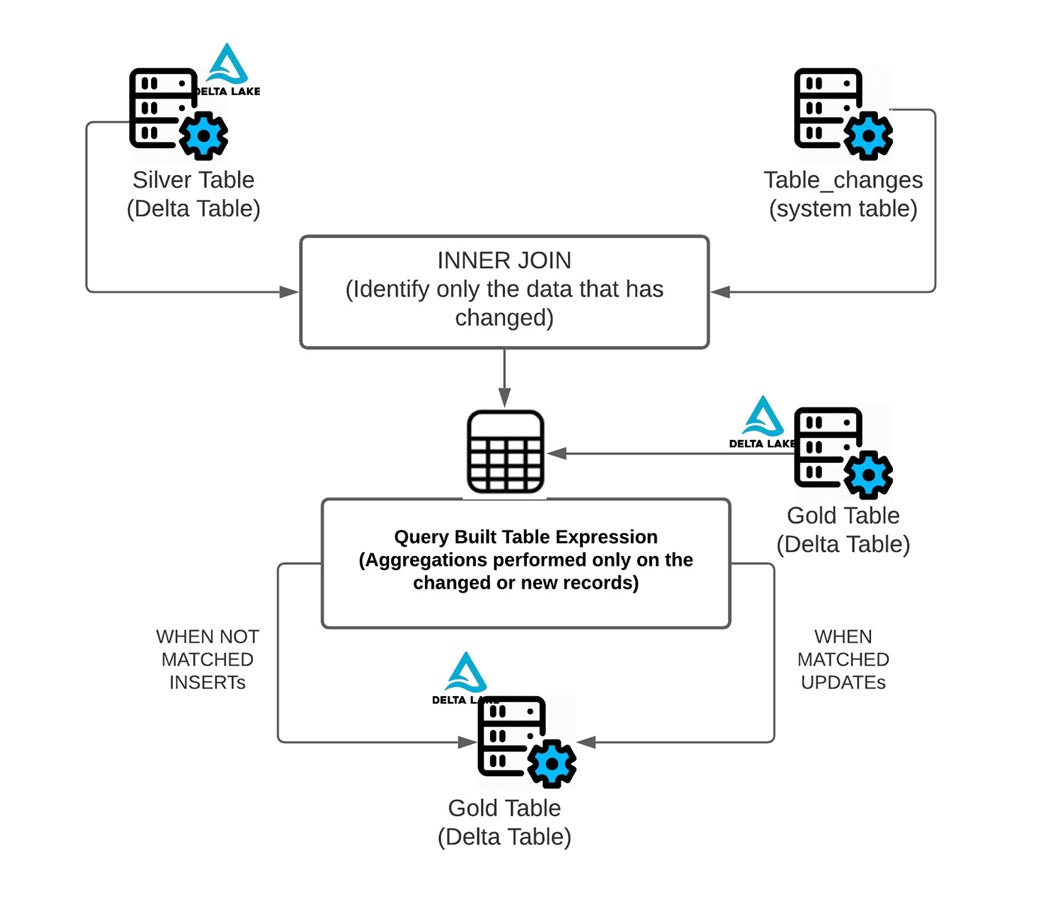
Como visto no diagrama acima, o CDF torna simples derivar quais linhas foram alteradas, pois ele realiza apenas a agregação necessária nos dados que foram alterados ou são novos usando a operação table_changes. Abaixo, você pode ver como usar os dados alterados para determinar quais datas e símbolos de ações foram alterados.
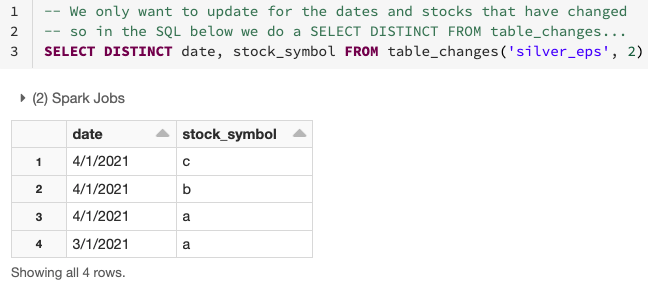
Como mostrado abaixo, você pode usar os dados alterados da tabela silver para agregar apenas os dados nas linhas que precisam ser atualizadas ou inseridas na tabela gold. Para fazer isso, use INNER JOIN na table_changes('nome_da_tabela','versao')
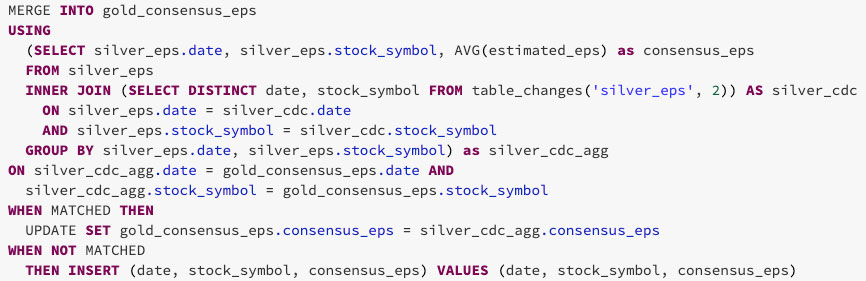
O resultado final é uma versão clara e concisa de uma tabela gold que pode mudar incrementalmente ao longo do tempo!
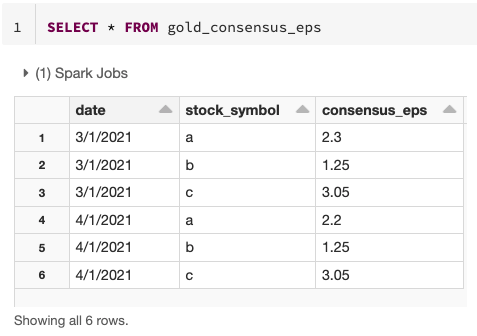
Casos de uso típicos
Aqui estão alguns casos de uso e benefícios comuns do novo recurso CDF:
Tabelas Silver & Gold
Melhore o desempenho do Delta processando apenas as alterações após a comparação inicial do MERGE para acelerar e simplificar operações de ETL/ELT.
Visualizações materializadas
Crie visualizações de informações atualizadas e agregadas para uso em BI e análise, sem precisar reprocessar as tabelas subjacentes completas, atualizando apenas onde as alterações ocorreram.
Transmitir alterações
Envie o Change Data Feed para sistemas downstream, como Kafka ou RDBMS, que podem usá-lo para processar incrementalmente em estágios posteriores dos pipelines de dados.
Tabela de trilha de auditoria
Capturar as saídas do Change Data Feed como uma tabela Delta fornece armazenamento perpétuo e capacidade de consulta eficiente para ver todas as alterações ao longo do tempo, incluindo quando exclusões ocorrem e quais atualizações foram feitas.
Quando usar o Change Data Feed
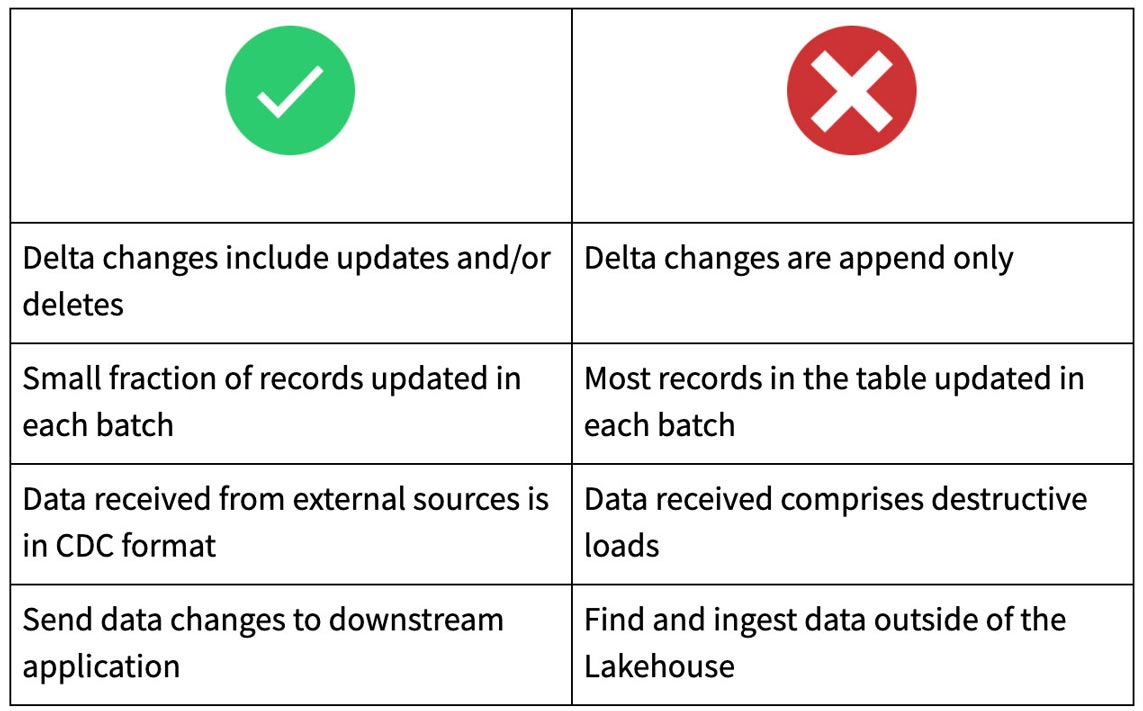
Conclusão
Na Databricks, nos esforçamos para tornar o impossível possível e o difícil simples. CDC, versionamento de log e implementação de MERGE eram virtualmente impossíveis em escala até que o Delta Lake foi criado. Agora, estamos tornando isso mais simples e eficiente com o empolgante recurso Change Data Feed (CDF)!
Experimente este notebook no Databricks
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.