How to Simplify CDC With Delta Lake's Change Data Feed
by Surya Sai Turaga and John O'Dwyer
Try this notebook in Databricks
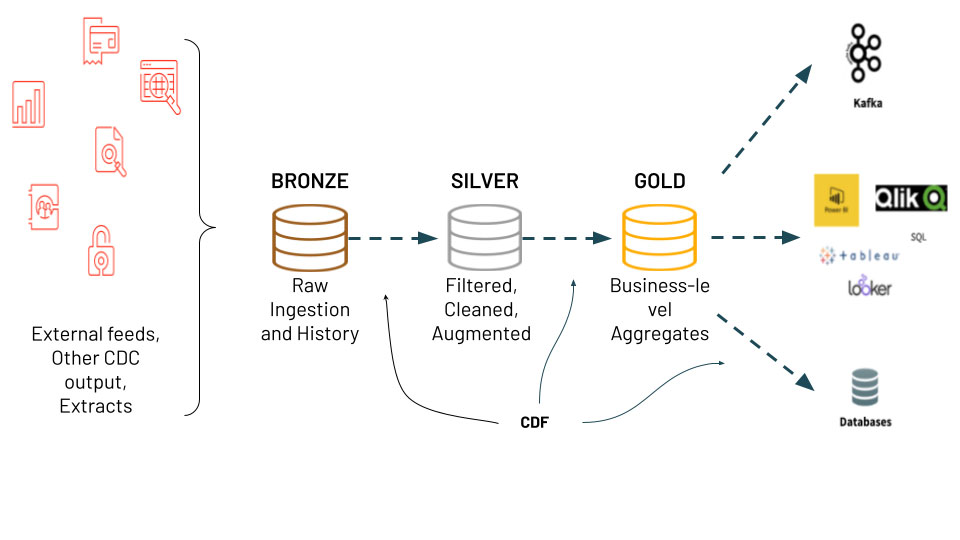
Change data capture (CDC) is a use case that we see many customers implement in Databricks – you can check out our previous deep dive on the topic here. Typically we see CDC used in an ingestion to analytics architecture called the medallion architecture. The medallion architecture that takes raw data landed from source systems and refines the data through bronze, silver and gold tables. CDC and the medallion architecture provide multiple benefits to users since only changed or added data needs to be processed. In addition, the different tables in the architecture allow different personas, such as Data Scientists and BI Analysts, to use the correct up-to-date data for their needs. We are happy to announce the exciting new Change Data Feed (CDF) feature in Delta Lake that makes this architecture simpler to implement and the MERGE operation and log versioning of Delta Lake possible!
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
Why is the CDF feature needed?
Many customers use Databricks to perform CDC, as it is simpler to implement with Delta Lake compared to other Big Data technologies. However, even with the right tools, CDC can still be challenging to execute. We designed CDF to make coding even simpler and address the biggest pain points around CDC, including:
- Quality Control - Row level changes are hard to attain between versions.
- Inefficiency - It can be inefficient to account for non-changing rows since the current version changes are at the file and not the row level.
Here is how Change Data Feed (CDF) implementation helps resolve the above issues:
- Simplicity and convenience - Uses a common, easy-to-use pattern for identifying changes, making your code simple, convenient and easy to understand.
- Efficiency - The ability to only have the rows that have changed between versions, makes downstream consumption of Merge, Update and Delete operations extremely efficient.
CDF captures changes only from a Delta table and is only forward-looking once enabled.
Change Data Feed in Action!
Let's dive into an example of CDF for a common use case: financial predictions. The notebook referenced at the top of this blog ingests financial data. Estimated Earnings Per Share (EPS) is financial data from analysts predicting a company's quarterly earnings per share. The raw data can come from many different sources and from multiple analysts for multiple stocks.
With the CDF feature, the data is simply inserted into the bronze table (raw ingestion), then filtered, cleaned and augmented in the silver table and, finally, aggregate values are computed in the gold table based on the changed data in the silver table.
While these transformations can get complex, thankfully, now the row-based CDF feature is simple and efficient. But how do you use it? Let's dig in!
NOTE: The example here focuses on the SQL version of CDF and also on a specific way to use the operations, to evaluate variations, please see the documentation here
Enabling CDF on a Delta Lake Table
To have the CDF feature available on a table, you must first enable the feature on said table. Below is an example of enabling CDF for the bronze table at table creation. You can also enable CDF on a table as an update to the table. In addition, you can enable CDF on a cluster for all tables created by the cluster. For these variations, please see the documentation here.

Querying the change data
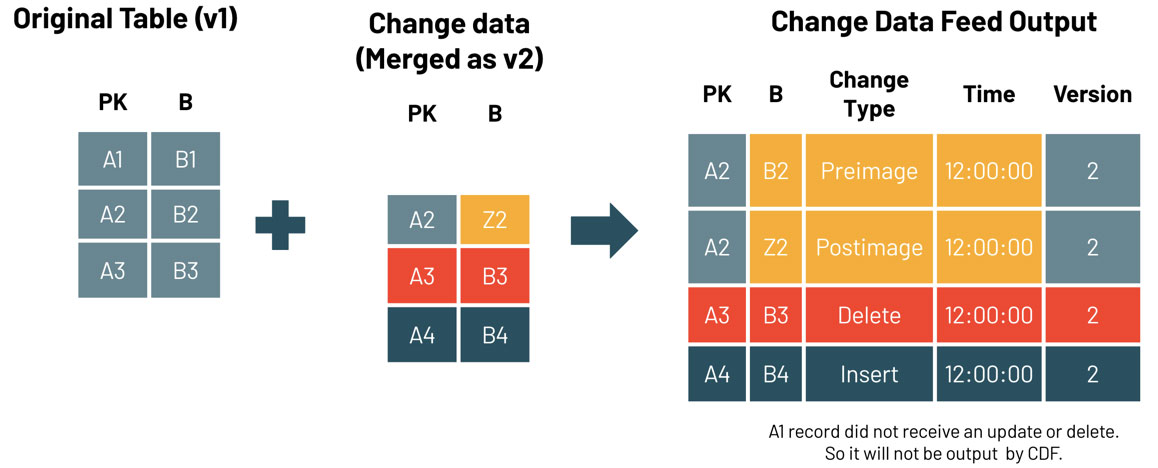
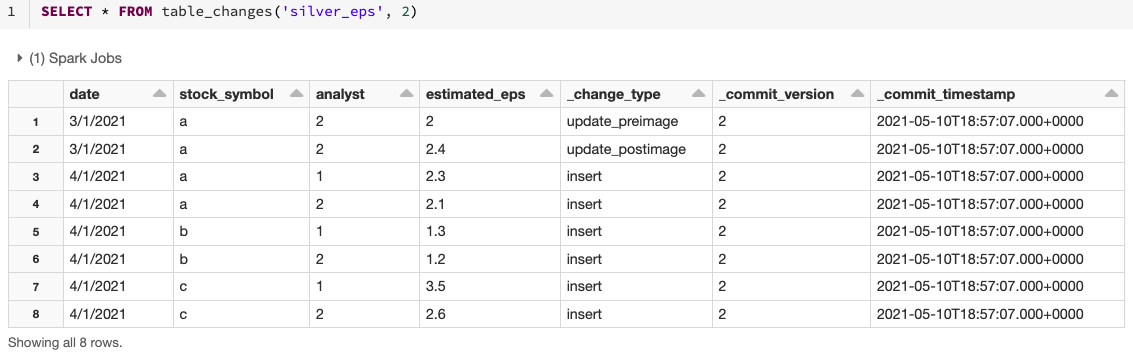
To query the change data, use the table_changes operation. The example below includes inserted rows and two rows that represent the pre- and post-image of an updated row, so that we can evaluate the differences in the changes if needed. There is also a delete Change Type that is returned for deleted rows.
This example accesses the changed records based on the starting version, but you can also cap the versions based on the ending version, as well as starting and ending timestamps if needed. This example focuses on SQL, but there are also ways to access this data in Python, Scala, Java and R. For these variations, please see the documentation here.
Using CDF row data in a MERGE statement
Aggregate MERGE statements, like the merge into the gold table, can be complex by nature, but the CDF feature makes the coding of these statements simpler and more efficient.
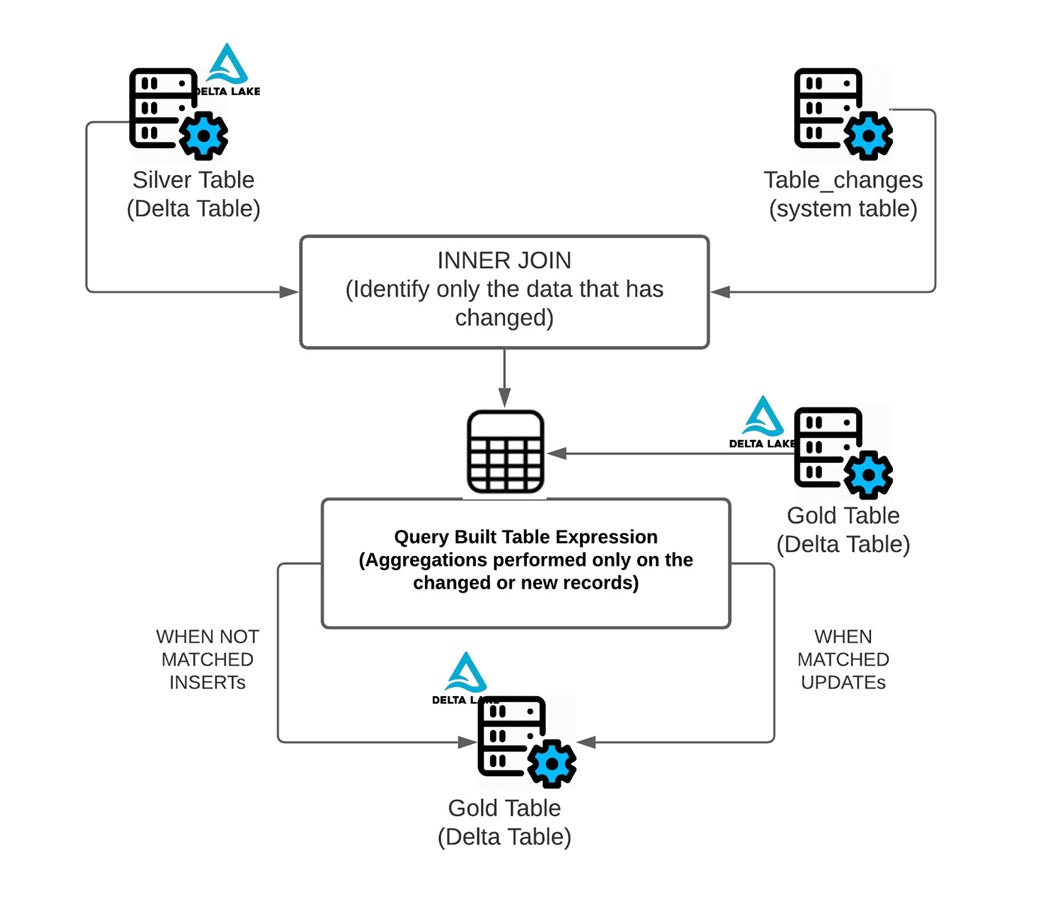
As seen in the above diagram, CDF makes it simple to derive which rows have changed, as it only performs the needed aggregation on the data that has changed or is new using table_changes operation. Below, you can see how to use the changed data to determine which dates and stock symbols have changed.
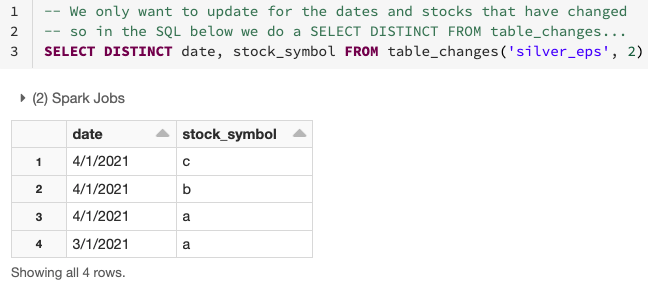
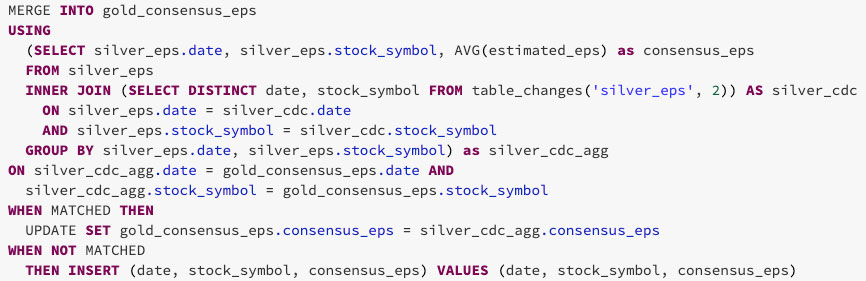
As shown below, you can use the changed data from the silver table to aggregate only the data on the rows that need to be updated or inserted into the gold table. To do this, use INNER JOIN on the table_changes('table_name','version')
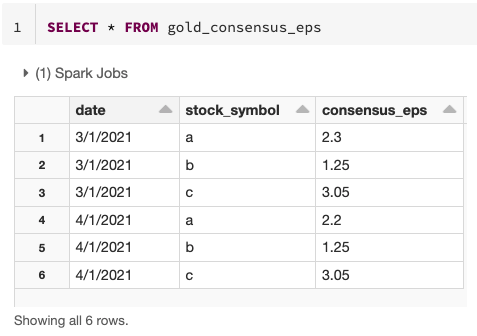
The end result is a clear and concise version of a gold table that can incrementally change over time!
Typical use cases
Here are some common use cases and benefits of the new CDF feature:
Silver & gold tables
Improve Delta performance by processing only changes following initial MERGE comparison to accelerate and simplify ETL/ELT operations.
Materialized views
Create up-to-date, aggregated views of information for use in BI and analytics without having to reprocess the full underlying tables, instead updating only where changes have come through.
Transmit changes
Send Change Data Feed to downstream systems such as Kafka or RDBMS that can use it to incrementally process in later stages of data pipelines.
Audit trail table
Capturing Change Data Feed outputs as a Delta table provides perpetual storage and efficient query capability to see all changes over time, including when deletes occur and what updates were made.
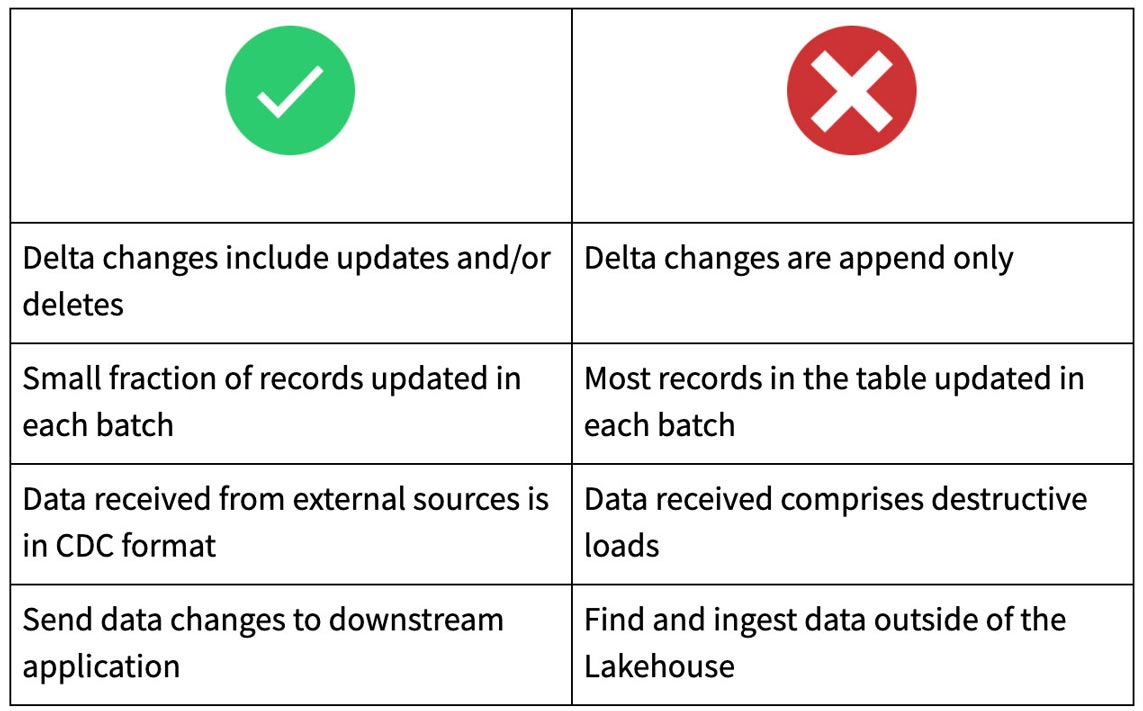
When to use Change Data Feed
Conclusion
At Databricks, we strive to make the impossible possible and the hard simple. CDC, Log versioning and MERGE implementation were virtually impossible at scale until Delta Lake was created. Now we are making it simpler and more efficient with the exciting Change Data Feed (CDF) feature!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.