Apresentando Perfis de Dados no Databricks Notebook
Simplificando a análise exploratória de dados
por Edward Gan, Moonsoo Lee e Austin Ford
Antes que um cientista de dados possa escrever um relatório sobre análise ou treinar um modelo de machine learning (ML), ele precisa entender a estrutura e o conteúdo de seus dados. Essa análise exploratória de dados é iterativa, com cada etapa do ciclo envolvendo frequentemente as mesmas técnicas básicas: visualização de distribuições de dados e cálculo de estatísticas resumidas como contagem de linhas, contagem de nulos, média, frequências de itens, etc. Infelizmente, gerar manualmente essas visualizações e estatísticas é complicado e propenso a erros, especialmente para grandes conjuntos de dados. Para resolver esse desafio e simplificar a análise exploratória de dados, estamos introduzindo recursos de perfil de dados no Databricks Notebook.
Perfil de dados no Notebook
Equipes de dados que trabalham em um cluster executando DBR 9.1 ou mais recente têm duas maneiras de gerar perfis de dados no Notebook: através da interface do usuário de saída da célula e através da biblioteca dbutils. Ao visualizar o conteúdo de um DataFrame usando a função display do Databricks (AWS|Azure|Google) ou os resultados de uma consulta SQL, os usuários verão uma aba “Perfil de Dados” à direita da aba “Tabela” na saída da célula. Clicar nesta aba executará automaticamente um novo comando que gera um perfil dos dados no DataFrame. O perfil incluirá estatísticas resumidas para colunas numéricas, de string e de data, bem como histogramas das distribuições de valores para cada coluna. Observe que este comando criará o perfil de todo o conjunto de dados no DataFrame ou nos resultados da consulta SQL, não apenas da parte exibida na tabela (que pode ser truncada).
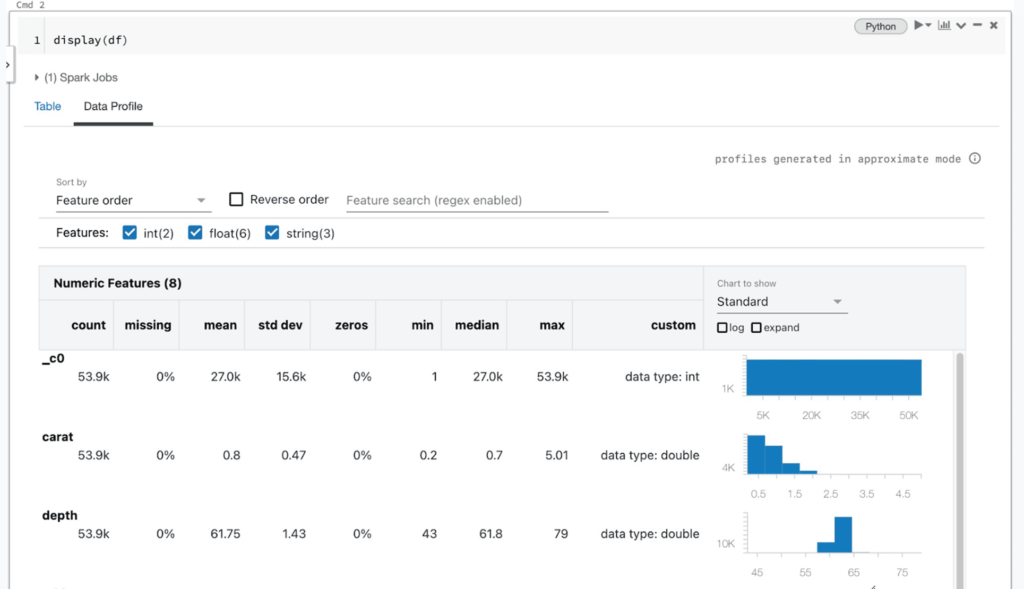
Nos bastidores, a interface do notebook emite um novo comando para calcular um perfil de dados, que é implementado por meio de uma consulta Apache Spark™ gerada automaticamente para cada conjunto de dados. Essa funcionalidade também está disponível através da API dbutils em Python, Scala e R, usando o comando dbutils.data.summarize(df). Para mais informações, consulte a documentação (AWS|Azure|Google).
Experimente os perfis de dados hoje mesmo ao visualizar DataFrames em notebooks Databricks!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.