Usando um Grafo de Conhecimento para Potencializar uma Camada Semântica de Dados para Databricks
por Prasad Kona e Aaron Wallace
Este é um post colaborativo entre Databricks e Stardog. Agradecemos a Aaron Wallace, Gerente Sênior de Produto na Stardog, por sua contribuição.
Os Knowledge Graphs (Grafos de Conhecimento) se tornaram onipresentes, só não sabemos disso. Nós os experimentamos todos os dias quando pesquisamos no Google ou assistimos aos feeds que rodam em nossas contas de mídia social de pessoas que conhecemos, empresas que seguimos ou o conteúdo que gostamos. Da mesma forma, os Enterprise Knowledge Graphs fornecem uma base para estruturar o conteúdo, os dados e os ativos de informação de sua organização, extraindo, relacionando e entregando conhecimento como respostas, recomendações e insights para todas as aplicações orientadas a dados, desde chatbots a motores de recomendação ou turbinando seu BI e Analytics.
Neste blog, você aprenderá como Databricks e Stardog resolvem o desafio da última milha na democratização de dados e insights. Databricks fornece uma plataforma lakehouse para cargas de trabalho de dados, analytics e inteligência artificial (IA) em uma plataforma multinuvem. Stardog fornece uma plataforma de grafo de conhecimento que pode modelar relacionamentos complexos contra dados que são amplos, e não apenas grandes, para descrever pessoas, lugares, coisas e como eles se relacionam. A Databricks Lakehouse Platform, juntamente com a camada semântica habilitada por Knowledge Graph da Stardog, oferece às organizações uma base para uma arquitetura de data fabric empresarial que permite que equipes multifuncionais, interempresariais ou interorganizacionais façam e respondam a consultas complexas entre silos de domínio.
A crescente necessidade de uma Arquitetura de Data Fabric
A rápida inovação e disrupção no espaço de gerenciamento de dados estão ajudando as organizações a extrair valor dos dados disponíveis tanto dentro quanto fora da empresa. Organizações que operam em fronteiras físicas e digitais estão encontrando novas oportunidades para atender os clientes da maneira que eles desejam ser atendidos.
Essas organizações conectaram todos os dados relevantes em toda a cadeia de suprimentos de dados para criar uma imagem completa e precisa no contexto de seus casos de uso. A maioria das indústrias que buscam operar e compartilhar dados entre fronteiras organizacionais para harmonizar dados e permitir o compartilhamento de dados estão adotando padrões abertos na forma de ontologias prescritas, de FIBO em Serviços Financeiros a D3FEND no domínio de Cibersegurança. Essas ontologias de negócios (ou modelos semânticos) refletem como pensamos sobre dados com significado anexado, ou seja, "coisas" em vez de como os dados são estruturados e armazenados, ou seja, "strings", e tornam o compartilhamento e a reutilização de dados possíveis.
A ideia de uma camada semântica não é nova. Ela existe há mais de 30 anos, frequentemente promovida por fornecedores de BI que ajudam empresas a construir dashboards feitos sob medida. No entanto, a adoção ampla tem sido dificultada, dada a natureza embutida dessa camada como parte de um sistema de BI proprietário. Essa camada é frequentemente muito rígida e complexa, sofrendo das mesmas limitações de um sistema de banco de dados relacional físico que modela dados para otimizar sua linguagem de consulta estruturada em vez de como os dados são relacionados no mundo real — muitos para muitos. Uma camada de dados semântica impulsionada por grafo de conhecimento que opera entre suas camadas de armazenamento e consumo fornece essa cola e multiplicador que conecta todos os dados para entregar valor no contexto do caso de uso de negócios para cientistas de dados cidadãos e analistas que, de outra forma, não conseguem participar e colaborar em arquiteturas centradas em dados fora de um punhado de especialistas.
Habilite um caso de uso em seguros
Vamos analisar um exemplo do mundo real de uma organização de seguros com várias seguradoras para ilustrar como Stardog e Databricks trabalham juntos. Como a maioria das grandes empresas, muitas seguradoras lutam com desafios semelhantes quando se trata de dados, como a falta de ampla disponibilidade de dados de fontes internas e externas para a tomada de decisão por stakeholders críticos. Todos, desde a avaliação de risco de subscrição até a administração de apólices, gerenciamento de sinistros e agências, lutam para alavancar os dados e insights corretos para tomar decisões críticas. Todos eles precisam de um data fabric em toda a empresa que traga os elementos de uma arquitetura moderna de dados e analytics para tornar os dados FAIR — Findable (Encontráveis), Accessible (Acessíveis), Interoperable (Interoperáveis) e Reusable (Reutilizáveis). A maioria das empresas inicia sua jornada trazendo todas as fontes de dados para um data lake. A abordagem lakehouse da Databricks fornece às empresas uma ótima base para armazenar todos os seus dados analíticos e tornar todos os dados acessíveis a qualquer pessoa dentro da empresa. Nessa camada de dados, ocorrem toda a limpeza, transformação e desambiguação. O próximo passo nessa jornada é a harmonização de dados, conectando dados com base em seu significado para fornecer contexto mais rico. Uma camada semântica, entregue por um grafo de conhecimento, muda o foco para a análise e processamento de dados e fornece um tecido conectado de insights entre domínios para subscritores, analistas de risco, agentes e equipes de atendimento ao cliente para gerenciar riscos e oferecer uma experiência excepcional ao cliente.
Examinaremos como isso funcionaria com um modelo semântico simplificado como ponto de partida.
Modele facilmente entidades específicas de domínio e relacionamentos entre domínios
Criar visualmente um modelo de dados semântico através de uma experiência semelhante a um quadro branco é o primeiro passo na criação de uma camada de dados semântica. Dentro do Designer da Stardog, basta clicar para criar classes específicas (ou entidades) que são críticas para responder às suas perguntas de negócios. Uma vez criada uma classe, você pode adicionar todos os atributos e tipos de dados necessários para descrever essa nova entidade. Ligar classes (ou entidades) é fácil. Com uma entidade selecionada, basta clicar para adicionar um link e arrastar o ponto do novo relacionamento até que ele se encaixe na outra entidade. Dê a esse novo relacionamento um nome que descreva o significado de negócios (por exemplo, um "Cliente" "possui" um "Veículo").
Adicione uma nova classe e vincule-a a uma classe existente para criar um relacionamento
Mapeie metadados da Databricks Lakehouse Platform
O que é um modelo sem dados? Os usuários do Stardog podem se conectar a uma variedade de fontes de dados estruturadas, semiestruturadas e não estruturadas, persistindo ou virtualizando dados, ou alguma combinação, quando e onde fizer sentido. No Designer, é fácil conectar dados de fontes existentes como Delta Lake para conectar os metadados de tabelas especificadas pelo usuário. Isso permite o acesso inicial a esses dados através de sua camada de virtualização sem movê-los ou copiá-los para o grafo de conhecimento. A camada de virtualização traduz automaticamente as consultas recebidas do Stardog de SPARQL baseado em padrões abertos para consultas SQL otimizadas de push-down no Databricks SQL.
Adicione uma nova fonte de dados como um recurso do projeto
Clique para adicionar um novo recurso de projeto e selecione uma das conexões disponíveis, como Databricks. Essa conexão utiliza o novo endpoint SQL recém-lançado pela Databricks. Defina um escopo para os dados e especifique quaisquer propriedades adicionais. Use o painel de visualização para dar uma olhada rápida nos dados antes de adicioná-los ao seu projeto.
Incorpore dados adicionais de uma variedade de locais
O Designer simplifica a incorporação de dados de outras fontes e arquivos como CSVs, para equipes que buscam realizar análises de dados ad hoc, combinando dados do Delta com essas novas informações. Uma vez adicionado como um recurso, você simplesmente adiciona um link e arrasta e solta para uma classe para mapear os dados. Dê ao mapeamento um nome significativo, especifique uma coluna de dados para o identificador primário, o rótulo e quaisquer outras colunas de dados que correspondam aos atributos da entidade.
Mapeie dados de um recurso de projeto para uma classe
Publique seu trabalho
Dentro do Designer, você pode publicar o modelo e os dados deste projeto diretamente em seu servidor Stardog para uso no Explorer da Stardog. O designer também permite que você publique e consuma a saída do grafo de conhecimento de várias maneiras. Você pode publicar diretamente em uma pasta compactada de arquivos, incluindo seu modelo e mapeamentos, em seu sistema de controle de versão.
Publique diretamente em um banco de dados Stardog
Depois que os dados forem publicados no Stardog, os analistas de dados também podem usar ferramentas populares de BI, como o Tableau, para se conectar através do Endpoint BI/SQL do Stardog para extrair dados através da camada semântica para um relatório ou dashboard. O schema gerado automaticamente em qualquer ferramenta compatível com SQL permite que os usuários escrevam consultas SQL contra o Knowledge Graph. As consultas que vêm através da camada SQL são automaticamente traduzidas para SPARQL, a linguagem de consulta do Knowledge Graph, e enviadas usando consultas otimizadas de schema gerado automaticamente, através da camada virtual, para computação na origem, neste caso, Databricks via endpoint Databricks SQL. As mesmas informações também podem ser disponibilizadas para usuários do Databricks em um notebook usando a API Python do Stardog, pystardog. Você também pode incorporar o grafo virtual para uso direto em seus aplicativos usando a API GraphQL do Stardog. A camada semântica sobre o lakehouse fornece um ambiente único para todos os tipos de usuários e suas ferramentas preferidas, mantendo as operações apoiadas por um conjunto consistente de dados.
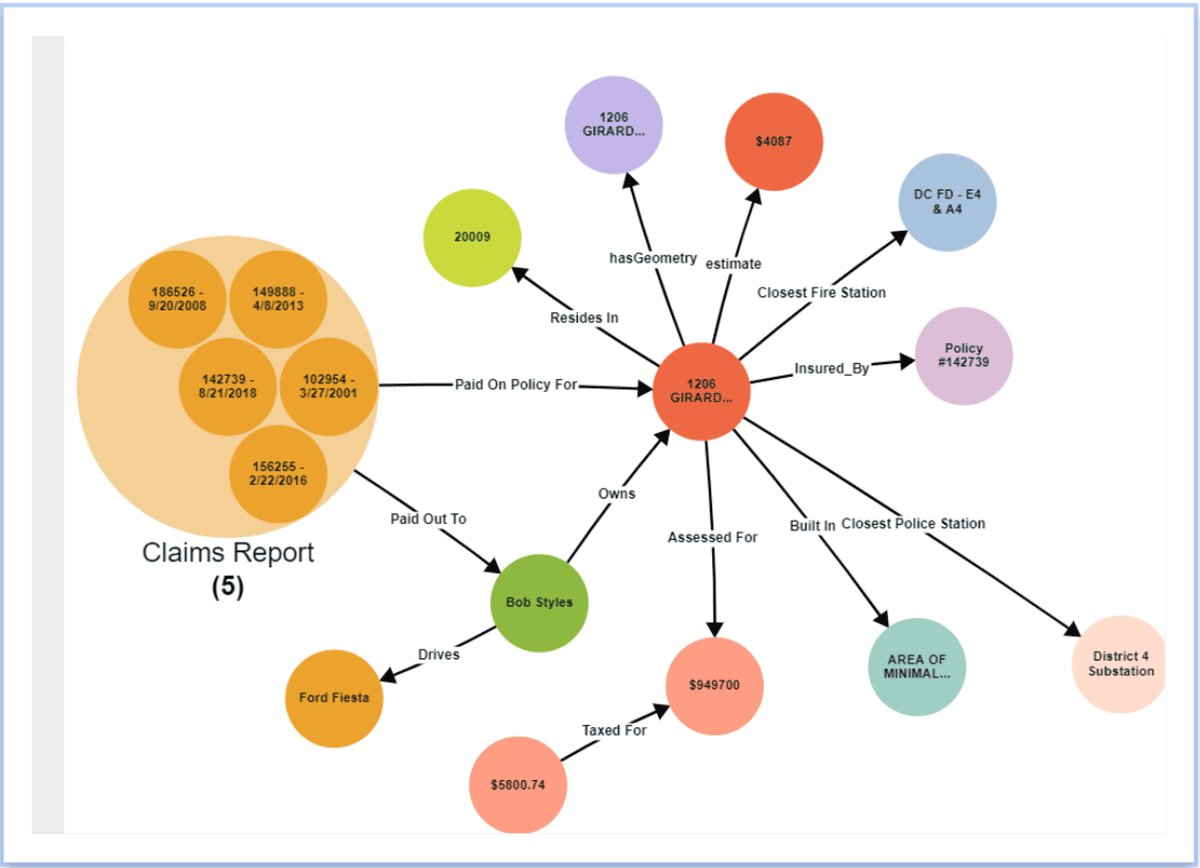
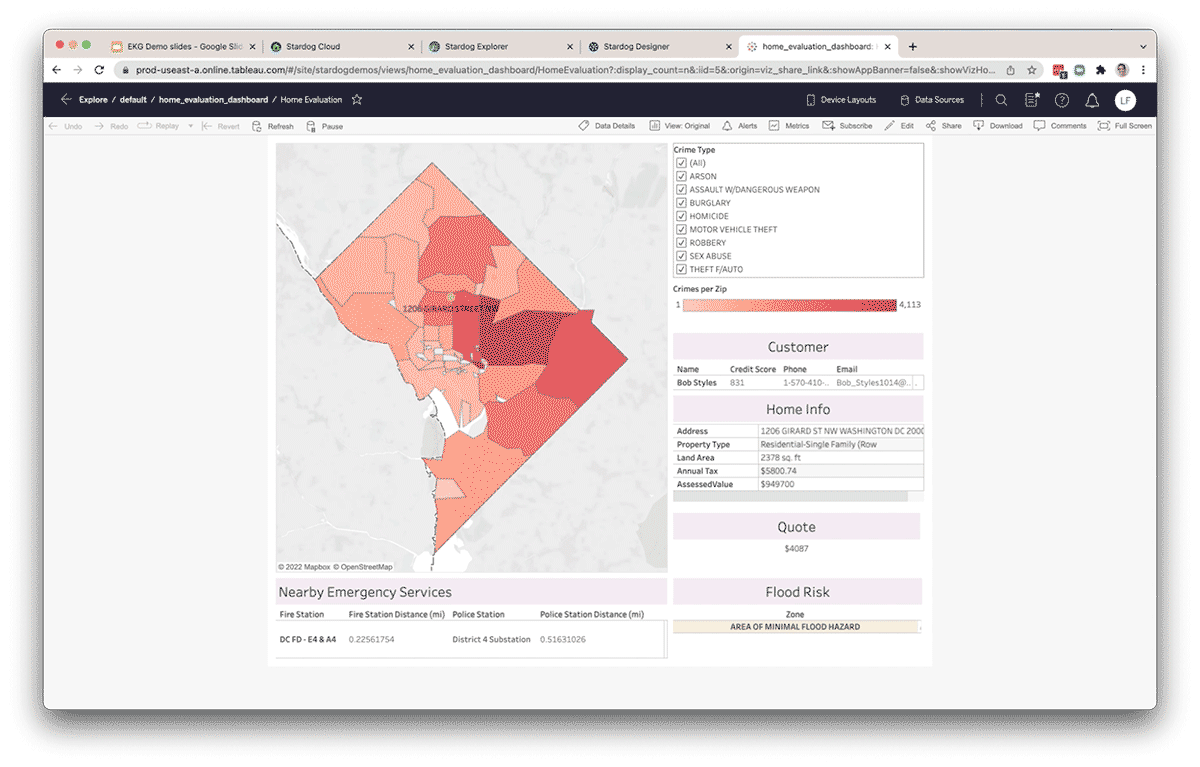
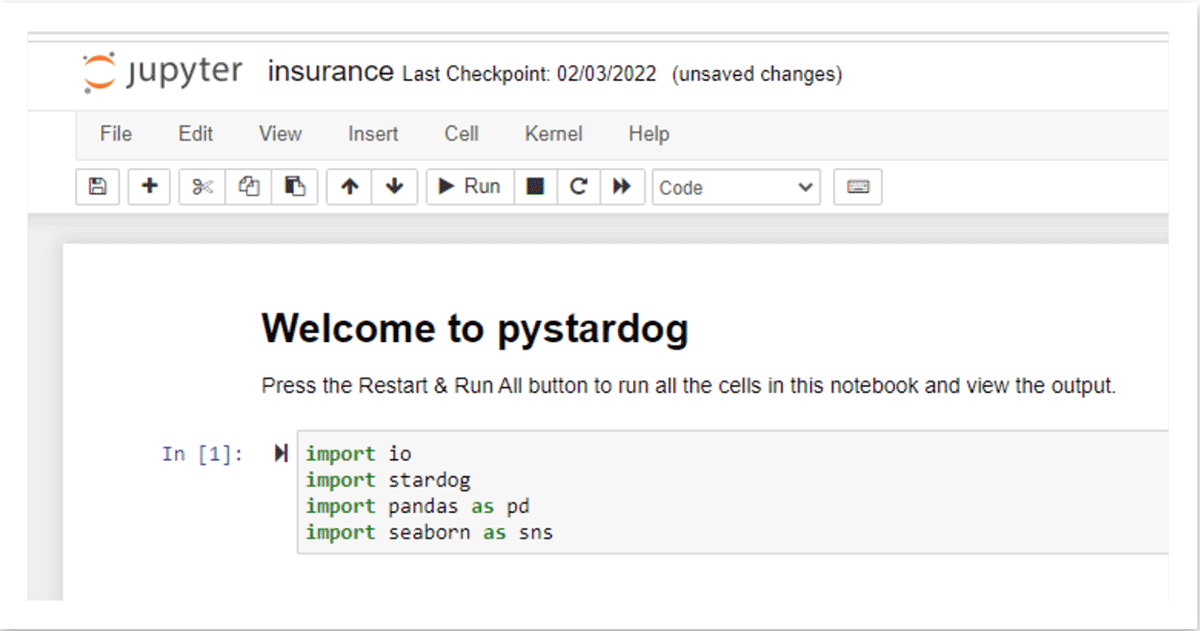
Aumente a produtividade e desenvolva novos insights
Ao organizar os dados em um Knowledge Graph, as equipes de dados aumentam sua produtividade diminuindo o tempo gasto na manipulação de dados de fontes externas para suportar análises ad hoc. Dados fora do Databricks podem ser federados através da camada de virtualização do Stardog e conectados a dados dentro do Databricks. Além disso, novos relacionamentos podem ser inferidos entre entidades sem modelá-los explicitamente no knowledge graph usando técnicas como inferência estatística e/ou lógica. Como Databricks e Stardog funcionam perfeitamente juntos, a combinação oferece uma experiência completa que simplifica consultas e análises complexas entre domínios. Além disso, a camada semântica se torna uma camada viva, compartilhável e fácil de usar como parte de uma fundação de data fabric empresarial, fornecendo conhecimento em toda a empresa para apoiar novas iniciativas orientadas por dados.
Começando com Databricks e Stardog
Neste blog, fornecemos uma visão geral de como o Stardog habilita uma camada de dados semântica com tecnologia de knowledge graph sobre a Databricks Lakehouse Platform. Para uma visão aprofundada, confira nossa demonstração detalhada. O Stardog fornece aos trabalhadores do conhecimento insights críticos just-in-time em um universo conectado de ativos de dados para turbinar suas análises e acelerar o valor de seus investimentos em data lake. Ao usar Databricks e Stardog juntos, equipes de dados e analytics podem estabelecer rapidamente um data fabric que evolui com as necessidades crescentes de sua organização.
Para começar com Databricks e Stardog, solicite um teste gratuito abaixo:
https://www.databricks.com/try-databricks
https://cloud.stardog.com/get-started
https://www.stardog.com/learn-stardog/
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.