Using a Knowledge Graph to Power a Semantic Data Layer for Databricks
by Prasad Kona and Aaron Wallace
This is a collaborative post between Databricks and Stardog. We thank Aaron Wallace, Sr. Product Manager at Stardog, for their contribution.
Knowledge Graphs have become ubiquitous, we just don't know it. We experience it every day when we search on Google or watch the feeds that run through our social media accounts of people we know, companies we follow or the content we like. Similarly, Enterprise Knowledge Graphs provide a foundation for structuring your organization's content, data and information assets by extracting, relating and delivering knowledge as answers, recommendations and insights to every data-driven application from chatbots to recommendation engines or supercharging your BI and Analytics.
In this blog, you will learn how Databricks and Stardog solve the last mile challenge in democratizing data and insights. Databricks provides a lakehouse platform for data, analytics and artificial intelligence (AI) workloads on a multi–cloud platform. Stardog provides a knowledge graph platform that can model complex relationships against data that is wide, and not just big, to describe people, places, things and how they relate. The Databricks Lakehouse Platform, coupled with Stardog's Knowledge Graph-enabled semantic layer, provide organizations with a foundation for an enterprise data fabric architecture that makes it possible for cross-functional, cross-enterprise or cross-organizational teams to ask and answer complex queries across domain silos.
The growing need for a Data Fabric Architecture
Rapid innovation and disruption in the data management space are helping organizations unlock value from data available both inside and outside the enterprise. Organizations operating across physical and digital boundaries are finding new opportunities to serve customers in the way they want to be served.
These organizations have connected all relevant data across the data supply chain to create a complete and accurate picture in the context of their use-cases. Most industries that look to operate and share data across organizational boundaries to harmonize data and enable data sharing are adopting open standards in the form of prescribed ontologies, from FIBO in Financial Services to D3FEND in the Cybersecurity domain. These business ontologies (or semantic models) reflect how we think about data with meaning attached, i.e. "things'' rather than how data is structured and stored, i.e. "strings", and make data sharing and re-use possible.
The idea of a semantic layer is not new. It has been around for over 30 years, often promoted by BI vendors helping companies build purpose-built dashboards. However, broad adoption has been impeded, given the embedded nature of that layer as part of a proprietary BI system. This layer is often too rigid and complex, suffering from the same limitations as a physical relational database system which models data to optimize for its structured query language rather than how data is related in the real world—many-to-many. A knowledge graph-powered semantic data layer that operates between your storage and consumption layers provides that glue and multiplier that connects all data to deliver value in context of the business use-case to citizen data scientists and analysts that otherwise are unable to participate and collaborate in data-centric architectures outside of a handful of specialists.
Enable a use case around insurance
Let's look at a real-world example of a multi-carrier insurance organization to illustrate how Stardog and Databricks work together. Like most large companies, many insurance companies struggle with similar challenges when it comes to data, such as the lack of broad availability of data from internal and external sources for decision-making by critical stakeholders. Everyone from underwriting risk assessment to policy administration to claims management and agencies struggle with leveraging the right data and insights to make critical decisions. They all need an enterprise-wide data fabric that brings the elements of a modern data and analytics architecture to make data FAIR - Findable, Accessible, Interoperable and Reusable. Most companies start their journey by bringing all data sources into a data lake. The Databricks lakehouse approach provides companies with a great foundation for storing all their analytics data and making all data accessible to anyone inside the enterprise. In this data layer, all cleansing, transformation, and disambiguation takes place. The next step in that journey is data harmonization, connecting data based on its meaning to provide richer context. A semantic layer, delivered by a knowledge graph, shifts the focus to data analysis and processing and provides a connected fabric of cross-domain insights to underwriters, risk analysts, agents and customer service teams to manage risk and deliver an exceptional customer experience.
We will examine how this would work with a simplified semantic model as a starting point.
Easily model domain-specific entities and cross-domain relationships
Visually creating a semantic data model through a whiteboard-like experience is the initial step in creating a semantic data layer. Inside the Stardog Designer project, just click to create specific classes (or entities) that are critical in answering your business questions. Once a class is created, you can add all the necessary attributes and data types to describe this new entity. Linking classes (or entities) together is easy. With an entity selected, just click to add a link and drag the point of the new relationship until it snaps to the other entity. Give this new relationship a name that describes the business meaning (e.g., a "Customer" "owns" a "Vehicle").
Add a new class and link it to an existing class to create a relationship
Map metadata from the Databricks Lakehouse Platform
What's a model without data? Stardog users can connect to a variety of structured, semi-structured and unstructured data sources by persisting or virtualizing data, or some combination, when and where it makes sense. In Designer, it is easy to connect data from existing sources like Delta Lake to connect the metadata from user-specified tables. This enables initial access to that data through its virtualization layer without moving or copying it into the knowledge graph. The virtualization layer automatically translates incoming queries from Stardog from its open-standards based SPARQL to optimized push-down SQL queries in Databricks SQL.
Add a new data source as a project resource
Click to add a new project resource and select from one of the available connections, such as Databricks. This connection leverages the new SQL endpoint recently released by Databricks. Define a scope for the data and specify any additional properties. Use the preview pane to quickly glance at the data before adding to your project.
Incorporate additional data from a variety of locations
Designer makes it simple to incorporate data from other data sources and files such as CSVs, for teams looking to conduct ad-hoc data analysis, combining data from Delta with this new information. Once added as a resource, you simply add a link and drag and drop to a class to map the data. Give the mapping a meaningful name, specify a data column for the primary identifier, the label, and any other data columns that match the attributes for the entity.
Map data from a project resource to a class
Publish your work
Within the Designer you can publish this project's model and data directly to your Stardog server for use in Stardog Explorer. The designer also allows you to publish and consume the output of the knowledge graph in various ways. You can publish directly to a zipped folder of files, including your model and mappings, to your version control system.
Publish directly to a Stardog database
Once the data has been published to Stardog, data analysts can also use popular BI tools like Tableau to connect through Stardog's BI/SQL Endpoint to pull data through the semantic layer into a report or dashboard. Auto-generated schema within any SQL-compatible tool allows users to write SQL queries against the Knowledge Graph. Queries coming through the SQL layer are automatically translated to SPARQL, the query language of the Knowledge Graph and pushed down using auto-generated source optimized queries, through the virtual layer, for computation at the source, in this case, Databricks via the Databricks SQL endpoint. The same information can also be made available to Databricks users in a notebook using Stardog's python API, pystardog. You can also embed the virtual graph for use directly inside your applications using Stardog's GraphQL API. The semantic layer on top of the lakehouse provides a single environment for all types of users and their preferred tools, keeping operations backed by a consistent set of data.
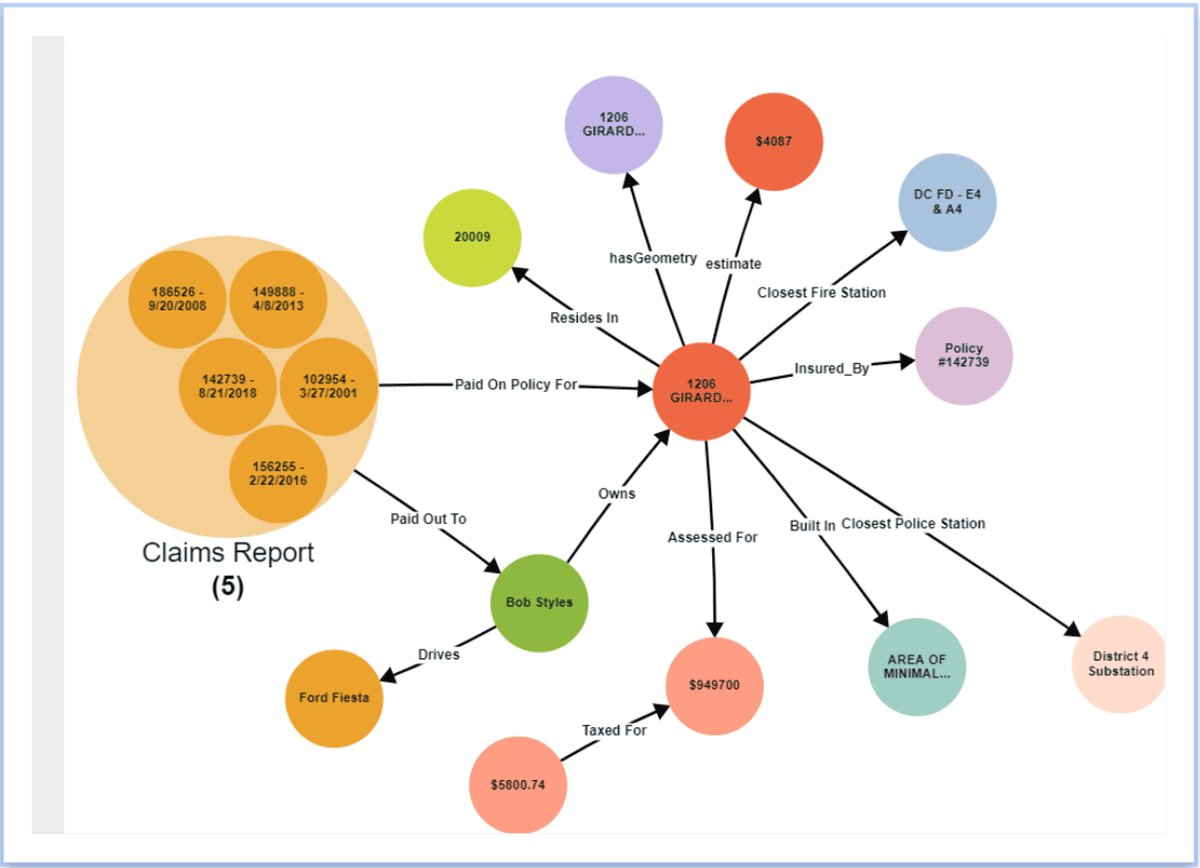
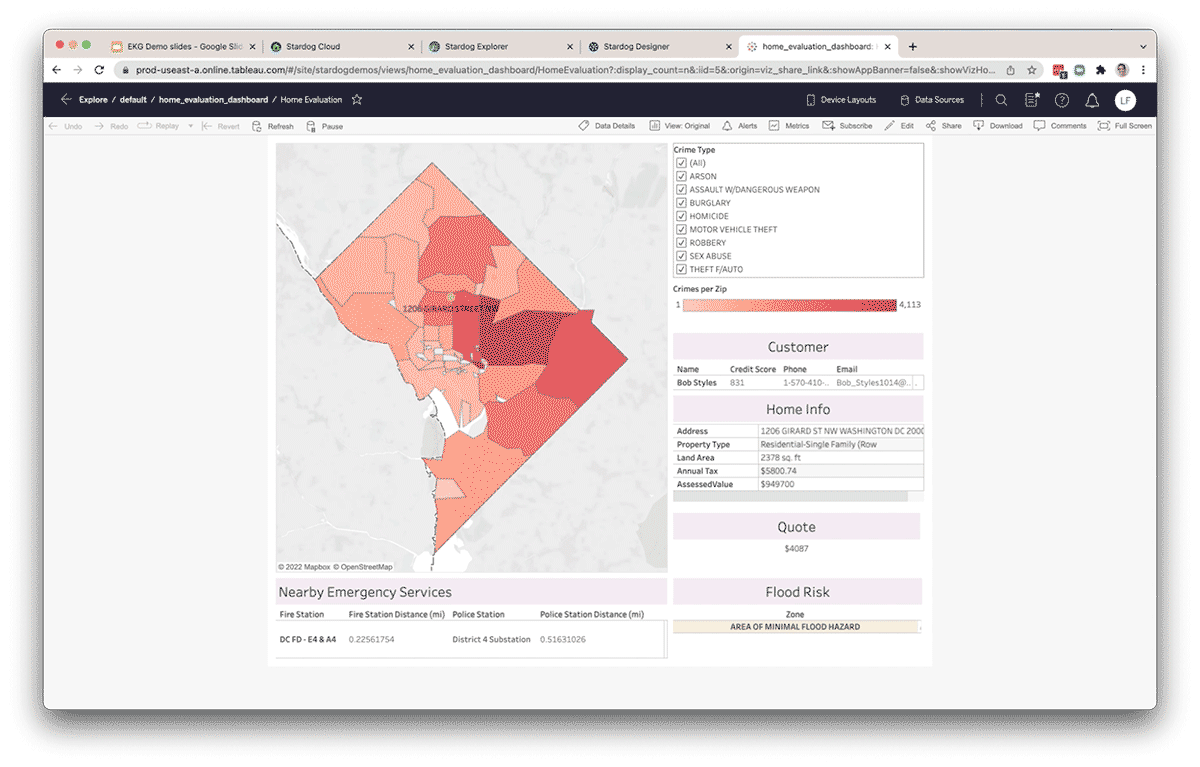
Increase productivity & develop new insights
By organizing data in a Knowledge Graph, data teams increase their productivity by decreasing the amount of time they spend wrangling data from external sources in support of ad hoc data analysis. Data outside Databricks can be federated through Stardog's virtualization layer and connected to data inside Databricks. Additionally, new relationships can be inferred between entities without explicitly modeling them into the knowledge graph using techniques like statistical and/or logical inference. Because Databricks and Stardog work seamlessly together, the combination provides a true end-to-end experience that simplifies complex cross-domain query and analysis. Moreover, the semantic layer becomes a living, sharing and easy-to-use layer as part of an enterprise data fabric foundation, providing enterprise-wide knowledge in support of new data-driven initiatives.
Getting started with Databricks and Stardog
In this blog, we've provided a high-level overview of how Stardog enables a knowledge graph-powered semantic data layer on top of the Databricks Lakehouse Platform. To get an in-depth overview, check out our deep dive demo. Stardog provides knowledge workers with critical just-in-time insight across a connected universe of data assets to supercharge their analytics and accelerate the value of their data lake investments. By using Databricks and Stardog together, data and analytics teams can quickly establish a data fabric that evolves with your organization's growing needs.
To get started with Databricks and Stardog, request a free trial below:
https://www.databricks.com/try-databricks
https://cloud.stardog.com/get-started
https://www.stardog.com/learn-stardog/
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.