Delta Live Tables Anuncia Novos Recursos e Otimizações de Desempenho
DLT anuncia que está desenvolvendo o Enzyme, uma otimização de desempenho projetada especificamente para cargas de trabalho de ETL, e lança vários novos recursos, incluindo Autoscaling Aprimorado
por Paul Lappas e Michael Armbrust
Desde a disponibilidade do Delta Live Tables (DLT) em todas as nuvens em abril (anúncio), introduzimos novos recursos para facilitar o desenvolvimento, aprimoramos o gerenciamento automatizado de infraestrutura, anunciamos uma nova camada de otimização chamada Project Enzyme para acelerar o processamento de ETL e habilitamos vários recursos corporativos e melhorias de UX.
O DLT permite que analistas e engenheiros de dados criem rapidamente pipelines de ETL de streaming ou em lote prontos para produção em SQL e Python. O DLT simplifica o desenvolvimento de ETL, permitindo que você defina sua pipeline de processamento de dados de forma declarativa. O DLT compreende as dependências da sua pipeline e automatiza quase todas as complexidades operacionais.
O Delta Live Tables cresceu para potencializar casos de uso de ETL em produção em empresas líderes em todo o mundo desde sua criação. O DLT é usado por mais de 1.000 empresas, desde startups a grandes corporações, incluindo ADP, Shell, H&R Block, Jumbo, Bread Finance e JLL.
Com o DLT, os engenheiros podem se concentrar em entregar dados em vez de operar e manter pipelines e aproveitar os principais recursos. Habilitamos vários recursos corporativos e melhorias de UX, incluindo suporte para Change Data Capture (CDC) para capturar dados que chegam continuamente de forma eficiente e fácil, e lançamos uma prévia do Enhanced Auto Scaling que oferece desempenho superior para cargas de trabalho de streaming. Vamos analisar as melhorias em detalhes:
Facilite o desenvolvimento
Estendemos nossa interface de usuário para facilitar o gerenciamento do ciclo de vida completo de ETL.
Melhorias de UX. Estendemos nossa interface de usuário para facilitar o gerenciamento de pipelines DLT, visualizar erros e fornecer acesso a membros da equipe com ACLs de pipeline ricas. Também adicionamos uma interface de observabilidade para ver m�étricas de qualidade de dados em uma única visualização e facilitamos o agendamento de pipelines diretamente da interface de usuário. Saiba mais.
Botão Agendar Pipeline. O DLT permite executar pipelines de ETL continuamente ou em modo acionado. Pipelines contínuos processam novos dados à medida que chegam e são úteis em cenários onde a latência de dados é crítica. No entanto, muitos clientes optam por executar pipelines DLT em modo acionado para controlar a execução da pipeline e os custos com mais precisão. Para facilitar o acionamento de pipelines DLT em um cronograma recorrente com Databricks Jobs, adicionamos um botão 'Agendar' na interface de usuário DLT para permitir que os usuários configurem um cronograma recorrente com apenas alguns cliques, sem sair da interface de usuário DLT. Você também pode ver um histórico de execuções e navegar rapidamente para os detalhes do seu Job para configurar notificações por e-mail. Saiba mais.
Change Data Capture (CDC). Com o DLT, os engenheiros de dados podem implementar facilmente o CDC com uma nova API declarativa APPLY CHANGES INTO, em SQL ou Python. Este novo recurso permite que pipelines de ETL detectem facilmente alterações nos dados de origem e as apliquem a conjuntos de dados em todo o lakehouse. O DLT processa as alterações de dados no Delta Lake incrementalmente, marcando registros para inserir, atualizar ou excluir ao lidar com eventos de CDC. Saiba mais.
CDC Slowly Changing Dimensions — Tipo 2. Ao lidar com dados em mudança (CDC), você geralmente precisa atualizar registros para acompanhar os dados mais recentes. SCD Tipo 2 é uma maneira de aplicar atualizações a um destino para que os dados originais sejam preservados. Por exemplo, se uma entidade de usuário no banco de dados se mudar para um endereço diferente, podemos armazenar todos os endereços anteriores desse usuário. O DLT suporta SCD tipo 2 para organizações que precisam manter uma trilha de auditoria de alterações. SCD2 retém um histórico completo de valores. Quando o valor de um atributo muda, o registro atual é fechado, um novo registro é criado com os valores de dados alterados, e este novo registro se torna o registro atual. Saiba mais.
Gerenciamento Automatizado de Infraestrutura
Autoscaling Aprimorado (prévia). Dimensionar clusters manualmente para desempenho ideal, dadas as mudanças e volumes de dados imprevisíveis – como em cargas de trabalho de streaming – pode ser desafiador e levar ao provisionamento excessivo. O autoscaling de cluster atual não tem conhecimento dos SLOs de streaming e pode não escalar rapidamente, mesmo que o processamento esteja ficando para trás da taxa de chegada de dados, ou pode não escalar para baixo quando a carga é baixa. O DLT emprega um algoritmo de autoscaling aprimorado, feito sob medida para streaming. O Autoscaling Aprimorado do DLT otimiza a utilização do cluster, garantindo que a latência ponta a ponta seja minimizada. Ele faz isso detectando flutuações nas cargas de trabalho de streaming, incluindo dados aguardando ingestão, e provisionando a quantidade certa de recursos necessários (até um limite especificado pelo usuário). Além disso, o Autoscaling Aprimorado desligará graciosamente os clusters sempre que a utilização for baixa, garantindo a evacuação de todas as tarefas para evitar impactar a pipeline. Como resultado, as cargas de trabalho que usam Autoscaling Aprimorado economizam custos, pois menos recursos de infraestrutura são usados. Saiba Mais.
Upgrade e Canais de Lançamento Automatizados. Os clusters Delta Live Tables (DLT) usam um runtime DLT baseado no Databricks runtime (DBR). A Databricks atualiza automaticamente o runtime DLT aproximadamente a cada 1-2 meses. O DLT atualizará automaticamente o runtime DLT sem exigir intervenção do usuário final e monitorará a saúde da pipeline após a atualização. Se o DLT detectar que a Pipeline DLT não pode iniciar devido a uma atualização do runtime DLT, reverteremos a pipeline para a versão anterior conhecida como boa. Você pode obter avisos antecipados sobre alterações que quebram scripts de inicialização ou outro comportamento do DBR, aproveitando os canais DLT para testar a versão de prévia do runtime DLT e ser notificado automaticamente se houver uma regressão. A Databricks recomenda o uso do canal CURRENT para cargas de trabalho de produção. Saiba mais.
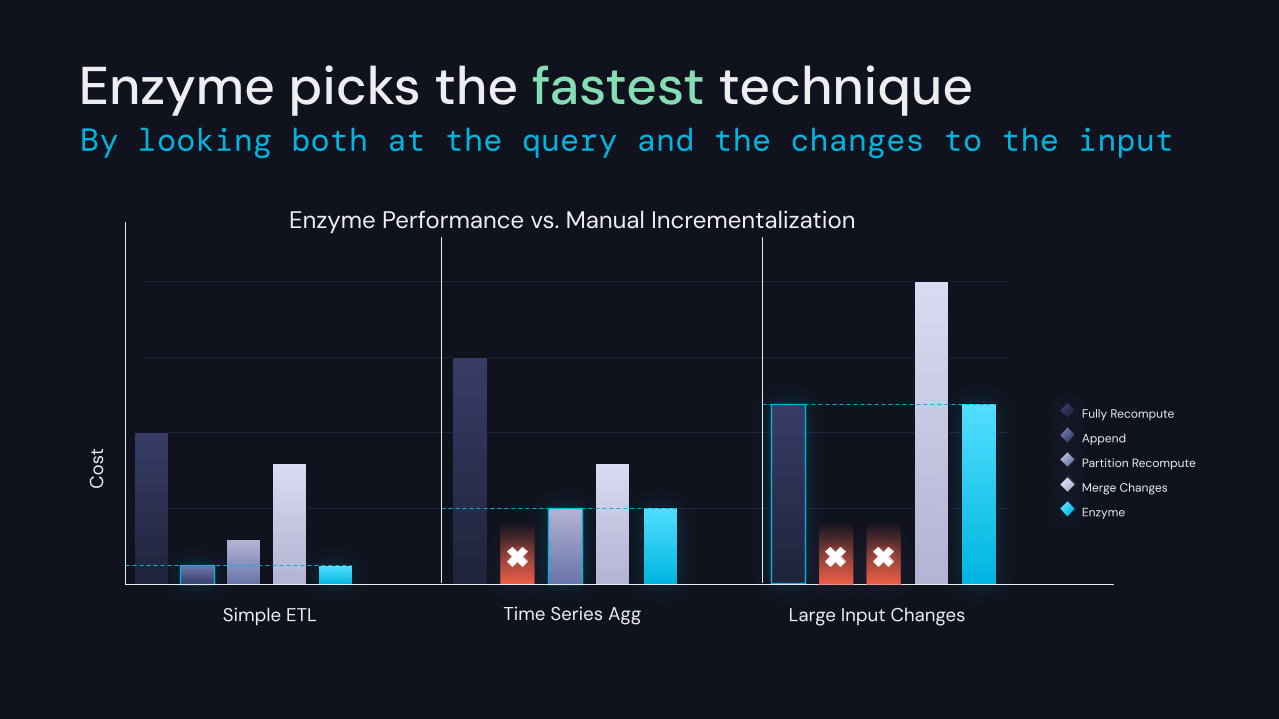
Anunciando o Enzyme, uma nova camada de otimização projetada especificamente para acelerar o processo de fazer ETL
Transformar dados para prepará-los para análise downstream é um pré-requisito para a maioria das outras cargas de trabalho na plataforma Databricks. Embora SQL e DataFrames tornem relativamente fácil para os usuários expressarem suas transformações, os dados de entrada mudam constantemente. Isso requer a recomputação das tabelas produzidas pelo ETL. Recomputar os resultados do zero é simples, mas muitas vezes proibitivo em termos de custo na escala em que muitos de nossos clientes operam.
Temos o prazer de anunciar que estamos desenvolvendo o projeto Enzyme, uma nova camada de otimização para ETL. O Enzyme mantém eficientemente atualizada uma materialização dos resultados de uma determinada consulta armazenada em uma tabela Delta. Ele usa um modelo de custo para escolher entre várias técnicas, incluindo técnicas usadas em views materializadas tradicionais, streaming delta-para-delta e padrões de ETL manuais comumente usados por nossos clientes.
Comece com o Delta Live Tables no Lakehouse
Assista à demonstração abaixo para descobrir a facilidade de uso do DLT para engenheiros de dados e analistas:
Se você é um cliente Databricks, basta seguir o guia para começar. Leia as notas de lançamento para saber mais sobre o que está incluído nesta versão GA. Se você não é um cliente Databricks existente, inscreva-se para um teste gratuito e você pode ver nossa Precificação Detalhada do DLT aqui.
Participe da conversa na Comunidade Databricks, onde colegas obcecados por dados estão conversando sobre os anúncios e atualizações do Data + AI Summit 2022. Aprenda. Conecte-se. Celebre.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.