Implementando Recuperação de Desastres para um Workspace Databricks
por Ankit Shah e Lorin Dawson
Este post é uma continuação de Visão Geral, Estratégias e Avaliação de Recuperação de Desastres e Automação e Ferramentas de Recuperação de Desastres para um Workspace Databricks.
Recuperação de Desastres refere-se a um conjunto de políticas, ferramentas e procedimentos que permitem a recuperação ou continuação de infraestrutura e sistemas de tecnologia críticos após um desastre natural ou causado pelo homem. Mesmo que Provedores de Serviços em Nuvem como AWS, Azure, Google Cloud e empresas SaaS criem salvaguardas contra pontos únicos de falha, falhas ocorrem. A gravidade da interrupção e seu impacto em uma organização podem variar. Para cargas de trabalho nativas da nuvem, um padrão claro de recuperação de desastres é fundamental.
Configuração de Recuperação de Desastres para Databricks
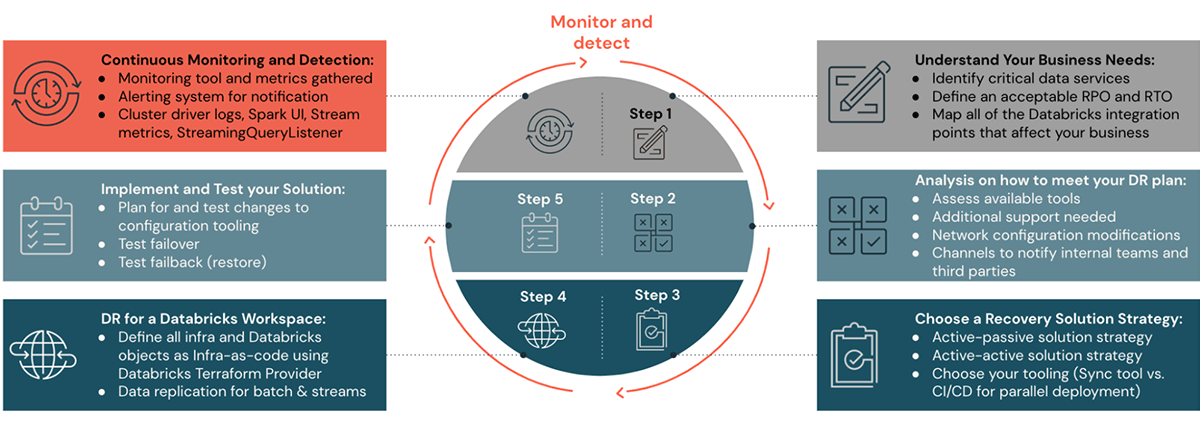
Por favor, consulte os posts anteriores nesta série de blogs sobre DR para entender as etapas de um a quatro sobre como planejar, configurar uma estratégia de solução de DR e automatizar. Nas etapas cinco e seis deste post, veremos como monitorar, executar e validar uma configuração de DR.
Solução de Recuperação de Desastres
Uma implementação típica do Databricks inclui vários ativos críticos, como código-fonte de notebooks, consultas, configurações de jobs e clusters, que devem ser recuperados sem problemas para garantir interrupção mínima e serviço contínuo aos usuários finais.
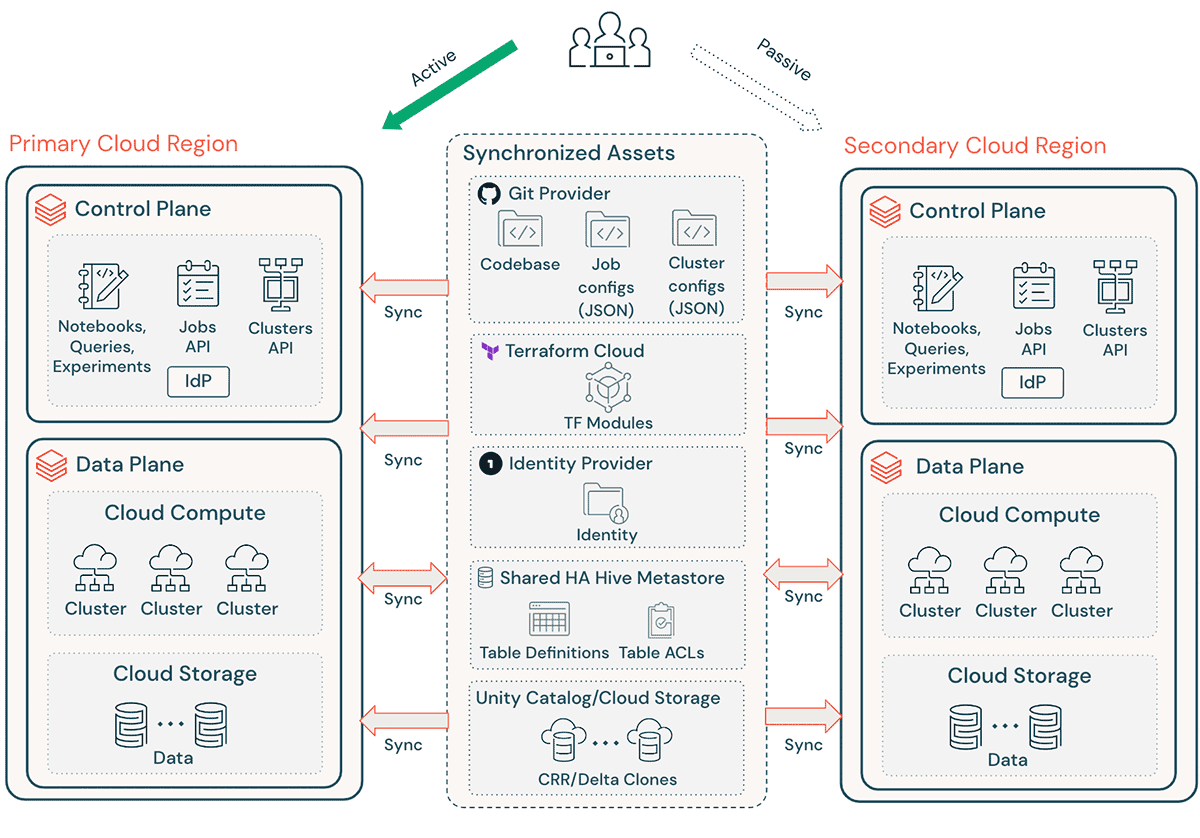
Considerações gerais de DR:
- Garanta que sua arquitetura seja replicável via Terraform (TF), tornando possível criar e recriar este ambiente em outro lugar.
- Use Databricks Repos (AWS | Azure | GCP) para sincronizar Notebooks e código de aplicação em arquivos arbitrários suportados (AWS | Azure | GCP).
- Use Terraform Cloud para acionar execuções de TF (plano e aplicação) para pipelines de infra e app, enquanto mantém o estado
- Replique dados de contas de armazenamento em nuvem como Amazon S3, Azure ADLS e GCS para a região de DR. Se você estiver na AWS, também pode armazenar dados usando S3 Multi-Region Access Points para que os dados abranjam vários buckets S3 em diferentes Regiões AWS.
- Definições de cluster Databricks podem conter informações específicas da zona de disponibilidade. Use o atributo de cluster “auto-az” ao executar Databricks na AWS para evitar quaisquer problemas durante o failover regional.
- Gerencie o desvio de configuração na Região de DR. Certifique-se de que sua infraestrutura, dados e configuração estejam conforme o necessário na Região de DR.
- Para código de produção e ativos, use ferramentas de CI/CD que enviam alterações para sistemas de produção simultaneamente para ambas as regiões. Por exemplo, ao enviar código e ativos de staging/desenvolvimento para produção, um sistema de CI/CD o torna disponível em ambas as regiões ao mesmo tempo.
- Use Git para sincronizar arquivos TF e base de código de infraestrutura, configurações de jobs e configurações de cluster.
- Configurações específicas da região precisarão ser atualizadas antes de executar o `apply` do TF em uma região secundária.
Observação: Certos serviços como Feature Store, pipelines MLflow, rastreamento de experimentos de ML, gerenciamento de modelos e implantação de modelos não podem ser considerados viáveis neste momento para Recuperação de Desastres. Para Structured Streaming e Delta Live Tables, uma implantação ativa-ativa é necessária para manter garantias de exatamente uma vez (exactly-once), mas o pipeline terá consistência eventual entre as duas regiões.
Considerações gerais adicionais podem ser encontradas nos posts anteriores desta série.
Monitoramento e Detecção
É crucial saber o mais cedo possível se suas cargas de trabalho não estão em um estado saudável para que você possa declarar rapidamente um desastre e se recuperar de um incidente. Esse tempo de resposta, juntamente com informações apropriadas, é fundamental para atender a objetivos agressivos de recuperação. É crítico considerar a detecção de incidentes, notificação, escalonamento, descoberta e declaração em seu planejamento e objetivos para fornecer objetivos realistas e alcançáveis.
Notificações de Status do Serviço
A Página de Status do Databricks fornece uma visão geral de todos os serviços principais do Databricks para o plano de controle. Você pode visualizar facilmente o status de um serviço específico visualizando a página de status. Opcionalmente, você também pode assinar atualizações de status em componentes de serviço individuais, o que envia um alerta sempre que o status ao qual você está inscrito muda.
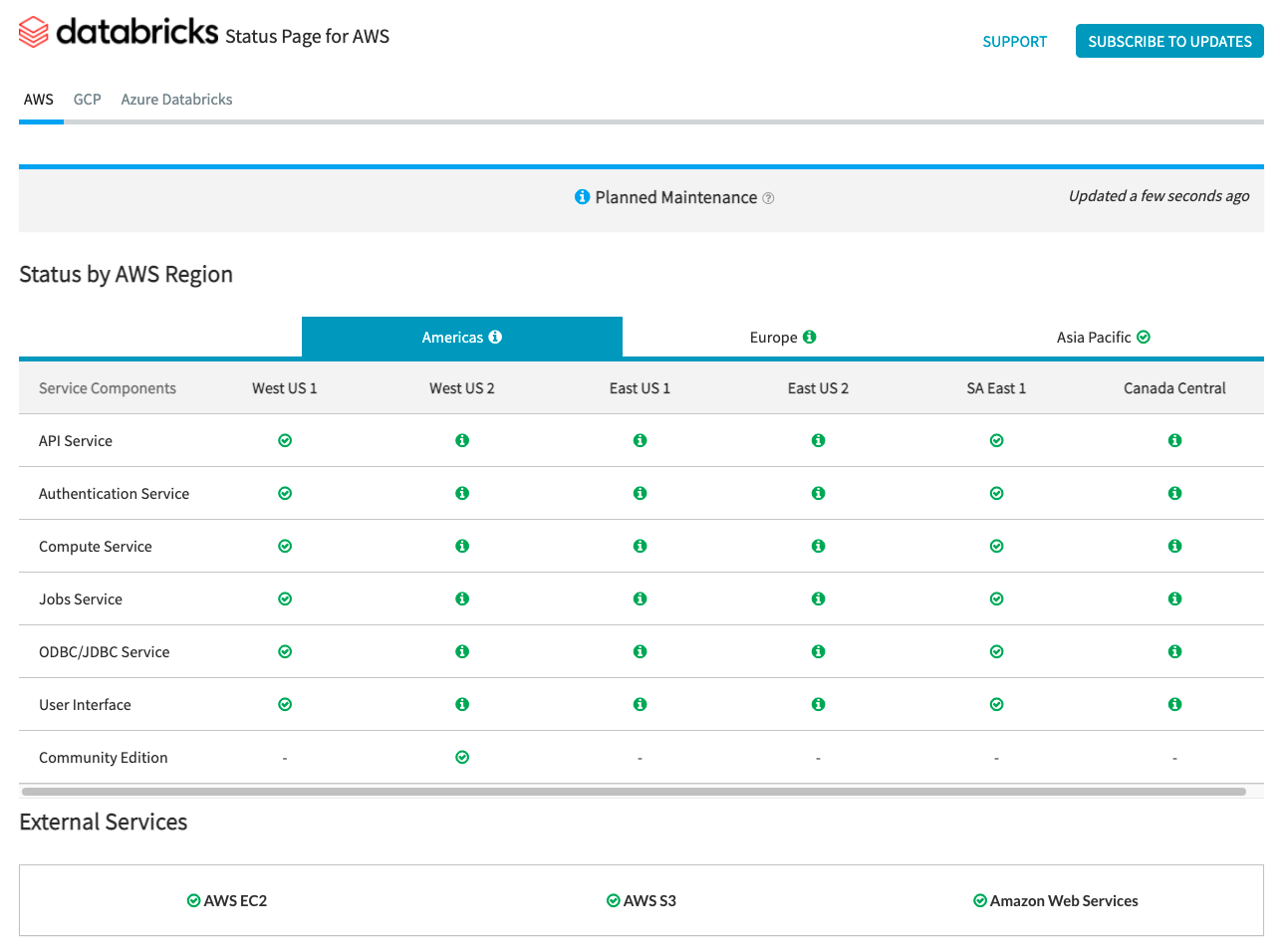
Para verificações de status em relação ao plano de dados, o AWS Health Dashboard, a Página de Status do Azure e a Página de Status de Serviço do GCP devem ser usadas para monitoramento.
AWS e Azure oferecem endpoints de API que as ferramentas podem usar para ingerir e alertar sobre verificações de status.
Monitoramento e Alerta de Infraestrutura
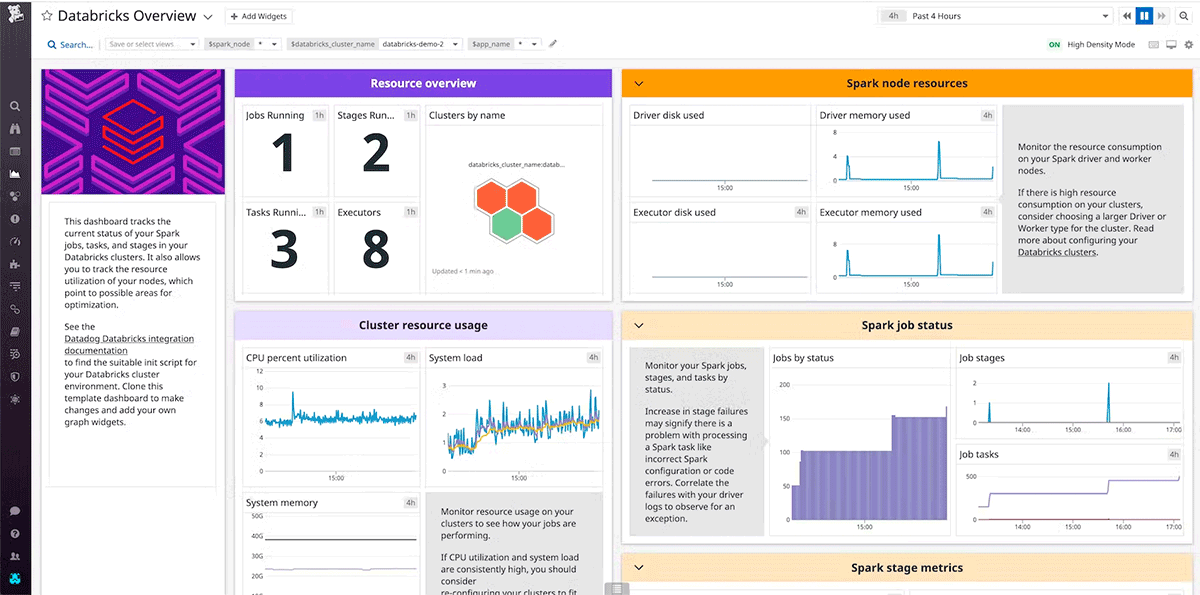
Usar uma ferramenta para coletar e analisar dados da infraestrutura permite que as equipes acompanhem o desempenho ao longo do tempo. Isso capacita proativamente as equipes a minimizar o tempo de inatividade e a degradação do serviço em geral. Além disso, o monitoramento ao longo do tempo estabelece uma linha de base para o desempenho máximo que é necessária como referência para otimizações e alertas.
No contexto de DR, uma organização pode não poder esperar por alertas de seus provedores de serviço. Mesmo que os requisitos de RTO/RPO sejam permissivos o suficiente para esperar um alerta do provedor de serviço, notificar a equipe de suporte do fornecedor sobre a degradação do desempenho com antecedência abrirá uma linha de comunicação mais cedo.
Tanto DataDog quanto Dynatrace são ferramentas de monitoramento populares que fornecem integrações e agentes para AWS, Azure, GCP e clusters Databricks.
Verificações de Integridade
Para os requisitos de RTO mais rigorosos, você pode implementar failover automatizado com base em verificações de integridade dos Serviços Databricks e outros serviços com os quais a carga de trabalho interage diretamente no Plano de Dados, por exemplo, armazenamentos de objetos e serviços de VM de provedores de nuvem.
Projete verificações de integridade que sejam representativas da experiência do usuário e baseadas em Indicadores Chave de Desempenho. Verificações superficiais de heartbeat podem avaliar se o sistema está operando, ou seja, se o cluster está em execução. Enquanto verificações de integridade profundas, como métricas do sistema da CPU de nós individuais, uso de disco e métricas do Spark em cada estágio ativo ou partição em cache, vão além das verificações superficiais de heartbeat para determinar degradação significativa de desempenho. Use verificações de integridade profundas baseadas em múltiplos sinais de acordo com a funcionalidade e o desempenho de linha de base da carga de trabalho.
Tenha cuidado ao automatizar totalmente a decisão de failover usando verificações de integridade. Se ocorrerem falsos positivos ou um alarme for disparado, mas o negócio puder absorver o impacto, não há necessidade de failover. Um falso failover introduz riscos de disponibilidade e riscos de corrupção de dados, além de ser uma operação cara em termos de tempo. Recomenda-se ter um humano no controle, como um gerente de incidentes de plantão, para tomar a decisão se um alarme for disparado. Um failover desnecessário pode ser catastrófico, e a revisão adicional ajuda a determinar se o failover é necessário.
Executando uma Solução de DR
Dois cenários de execução existem em um nível alto para uma solução de Recuperação de Desastres (DR). No primeiro cenário, o site de DR é considerado temporário. Assim que o serviço for restaurado no site principal, a solução deve orquestrar um failover do site de DR para o site principal permanente. Limitar a criação de novos artefatos enquanto o site de DR estiver ativo deve ser desencorajado, pois é temporário e complica o failback neste cenário. Inversamente, no segundo cenário, o site de DR será promovido a novo principal, permitindo que os usuários retomem o trabalho mais rapidamente, pois não precisam esperar que os serviços sejam restaurados. Além disso, este cenário não requer failback, mas o antigo site principal deve ser preparado como o novo site de DR.
Em qualquer cenário, cada região dentro do escopo da solução de DR deve suportar todos os serviços necessários, e um processo que valide se o workspace de destino está em boas condições operacionais deve existir como uma salvaguarda. A validação pode incluir autenticação simulada, consultas automatizadas, chamadas de API e verificações de ACL.
Failover
Ao acionar um failover para o site de DR, a solução não pode assumir que a capacidade de desligar o sistema de forma graciosa é possível. A solução deve tentar desligar os serviços em execução no site principal, registrar o status do desligamento para cada serviço e, em seguida, continuar tentando desligar os serviços sem o status apropriado em um intervalo de tempo definido. Isso reduz o risco de que os dados sejam processados simultaneamente nos sites principal e de DR, minimizando a corrupção de dados e facilitando o processo de failback assim que os serviços forem restaurados.
Etapas de alto nível para ativar o site de DR incluem:
- Execute um processo de desligamento no site principal para desabilitar pools, clusters e trabalhos agendados na região principal para que, se o serviço com falha voltar online, a região principal não comece a processar novos dados.
- Confirme se a infraestrutura e as configurações do site de DR estão atualizadas.
- Verifique a data dos últimos dados sincronizados. Consulte Terminologia da indústria de recuperação de desastres. Os detalhes desta etapa variam com base em como você sincroniza os dados e nas necessidades exclusivas do negócio.
- Estabilize suas fontes de dados e garanta que todas estejam disponíveis. Inclua todas as fontes de dados externas críticas, como armazenamento de objetos, bancos de dados, sistemas pub/sub, etc.
- Informe os usuários da plataforma.
- Inicie os pools relevantes (ou aumente o número de instâncias mínimas ociosas para os números relevantes).
- Inicie os clusters, trabalhos e SQL Warehouses relevantes (se não terminados).
- Altere a execução concorrente para trabalhos e execute os trabalhos relevantes. Estes podem ser execuções únicas ou periódicas.
- Ative os agendamentos de trabalhos.
- Para qualquer ferramenta externa que use uma URL ou nome de domínio para o seu workspace Databricks, atualize as configurações para contabilizar o novo plano de controle. Por exemplo, atualize URLs para APIs REST e conexões JDBC/ODBC. A URL voltada para o cliente do aplicativo web Databricks muda quando o plano de controle muda, portanto, notifique os usuários da sua organização sobre a nova URL.
Failback
Retornar ao site principal durante o Failback é mais fácil de controlar e pode ser feito em uma janela de manutenção. O Failback seguirá um plano muito semelhante ao Failover, com quatro exceções importantes:
- A região de destino será a região principal.
- Como o Failback é um processo controlado, o desligamento é uma atividade única que não requer verificações de status para desligar serviços à medida que eles voltam online.
- O site de DR precisará ser redefinido conforme necessário para quaisquer failovers futuros.
- Quaisquer lições aprendidas devem ser incorporadas à solução de DR e testadas para futuros eventos de desastre.
Conclusão
Teste sua configuração de recuperação de desastres regularmente em condições do mundo real para garantir que ela funcione corretamente. Não adianta manter uma solução de recuperação de desastres que não pode ser usada quando é necessária. Algumas organizações testam sua infraestrutura de DR realizando failover e failback entre regiões a cada poucos meses. Regularmente, o failover para o site de DR testa suas suposições e processos para garantir que eles atendam aos requisitos de recuperação em termos de RPO e RTO. Isso também garante que as políticas e procedimentos de emergência da sua organização estejam atualizados. Teste quaisquer alterações organizacionais que sejam necessárias em seus processos e configurações em geral. Seu plano de recuperação de desastres tem um impacto em seu pipeline de implantação, portanto, certifique-se de que sua equipe esteja ciente do que precisa ser mantido em sincronia.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.