Modelagem visual de dados usando erwin Data Modeler da Quest na Databricks Lakehouse Platform
Modelagem de Dados usando erwin no Databricks
por Vani Mishra, Abhishek Dey, Leo Mao, Soham Bhatt e Pradeep Anandapu
Este é um post colaborativo entre Databricks e Quest Software. Agradecemos a Vani Mishra, Diretora de Gerenciamento de Produtos na Quest Software, por suas contribuições.
Modelagem de Dados usando erwin Data Modeler
À medida que os clientes modernizam seus ambientes de dados para o Databricks, eles estão consolidando vários data marts e EDWs em uma única arquitetura de lakehouse escalável que suporta ETL, BI e IA. Geralmente, uma das primeiras etapas dessa jornada começa com um inventário dos modelos de dados existentes dos sistemas legados e sua racionalização e conversão nas zonas Bronze, Silver e Gold da arquitetura Databricks Lakehouse. Uma ferramenta robusta de modelagem de dados que pode visualizar, projetar, implantar e padronizar os ativos de dados do lakehouse simplifica muito a jornada de design e migração do lakehouse, além de acelerar os aspectos de governança de dados.
Temos o prazer de anunciar nossa parceria e integração do erwin Data Modeler da Quest com a Databricks Lakehouse Platform para atender a essas necessidades. Modeladores de dados agora podem modelar e visualizar estruturas de dados do lakehouse com o erwin Data Modeler para construir modelos de dados lógicos e físicos para acelerar a migração para o Databricks. Modeladores e arquitetos de dados podem rapidamente reengenheirar ou reconstruir bancos de dados e suas tabelas e visualizações subjacentes no Databricks. Agora você pode acessar facilmente o erwin Data Modeler no Databricks Partner Connect!
Aqui estão alguns dos principais motivos pelos quais ferramentas de modelagem de dados como o erwin Data Modeler são importantes:
- Melhor compreensão dos dados: Ferramentas de modelagem de dados fornecem uma representação visual de estruturas de dados complexas, facilitando para as partes interessadas a compreensão das relações entre diferentes elementos de dados.
- Aumento da precisão e consistência: Ferramentas de modelagem de dados podem ajudar a garantir que os bancos de dados sejam projetados com precisão e consistência em mente, reduzindo o risco de erros e inconsistências nos dados.
- Facilita a colaboração: Com ferramentas de modelagem de dados, várias partes interessadas podem colaborar no design de um banco de dados, garantindo que todos estejam na mesma página e que o esquema resultante atenda às necessidades de todas as partes interessadas.
- Melhor desempenho do banco de dados: Bancos de dados projetados corretamente podem melhorar o desempenho de aplicativos que dependem deles, levando a um processamento de dados mais rápido e eficiente.
- Manutenção mais fácil: Com um banco de dados bem projetado, tarefas de manutenção como adicionar novos elementos de dados ou modificar os existentes se tornam mais fáceis e menos propensas a erros.
- Governança de dados aprimorada, inteligência de dados e gerenciamento de metadados.
Neste blog, demonstraremos três cenários de como o erwin Data Modeler pode ser usado com o Databricks:
- O primeiro cenário é onde uma equipe deseja criar um Diagrama de Entidade-Relacionamento (ERD) novo com base na documentação da equipe de negócios. O objetivo é criar um diagrama ER para o modelo lógico para que uma unidade de negócios entenda e aplique relacionamentos, definições e regras de negócios conforme aplicadas no sistema. Com base neste modelo lógico, também construiremos um modelo físico para o Databricks.
- No segundo cenário, a unidade de negócios está construindo um modelo de dados visual por engenharia reversa a partir de seu ambiente Databricks atual, para entender definições de negócios, relacionamentos e perspectivas de governança, a fim de colaborar com a equipe de relatórios e governança.
- No terceiro cenário, a equipe de arquitetura de plataforma está consolidando seus vários Enterprise Data Warehouse (EDW) e data marts, como Oracle, SQL Server, Teradata, MongoDB etc., na plataforma Databricks Lakehouse e construindo um modelo mestre consolidado.
Após a conclusão da criação do ERD, mostraremos como gerar um arquivo DDL/SQL para a equipe de design físico do Databricks.
Cenário #1: Criar um novo Modelo de Dados Lógico e Físico para implementar no Databricks
O primeiro passo será selecionar um modelo Lógico/Físico, como mostrado aqui:
Após a seleção, você pode começar a construir suas entidades, atributos, relacionamentos, definições e outros detalhes neste modelo.
A captura de tela abaixo mostra um exemplo de um modelo avançado:
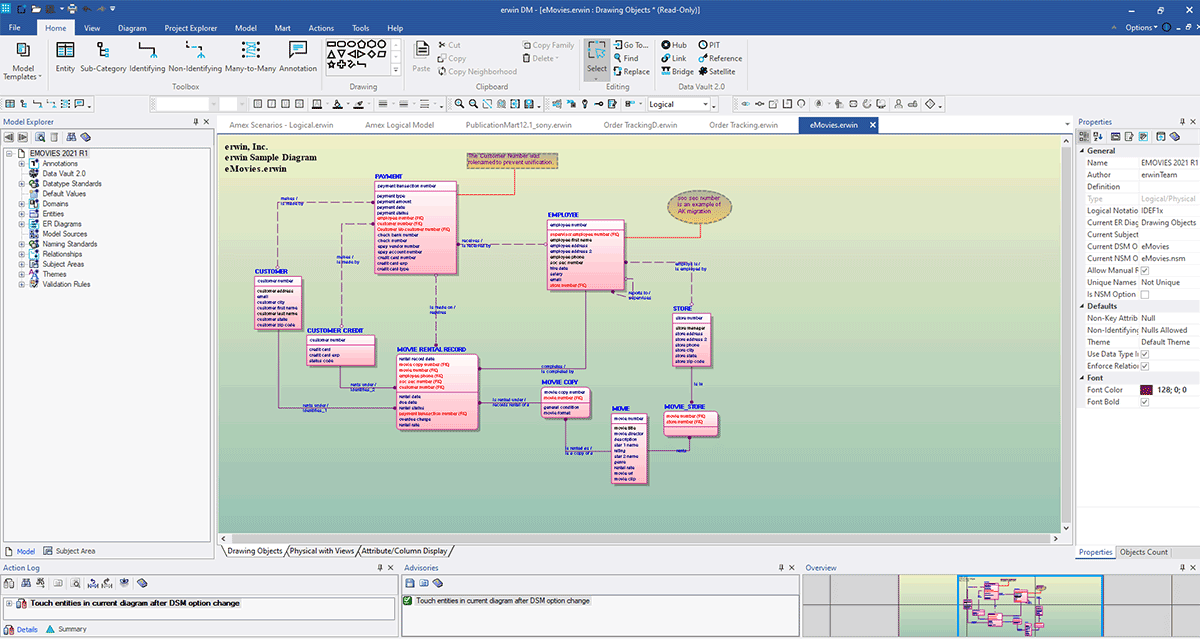
Aqui você pode construir seu modelo e documentar os detalhes conforme necessário. Para saber mais sobre como usar o erwin Data Modeler, consulte a documentação de ajuda online deles.
Cenário #2: Engenharia Reversa de um Modelo de Dados da Databricks Lakehouse Platform
Engenharia reversa de um modelo de dados é a criação de um modelo de dados a partir de um banco de dados ou script existente. A ferramenta de modelagem cria uma representação gráfica dos objetos de banco de dados selecionados e dos relacionamentos entre os objetos. Essa representação gráfica pode ser um modelo lógico ou físico.
Conectaremos ao Databricks a partir do erwin Data Modeler via Partner Connect:
Opções de Conexão:
| Parâmetro | Descrição | Informações Adicionais |
|---|---|---|
| Tipo de Conexão | Especifica o tipo de conexão que você deseja usar. Selecione Usar Fonte de Dados ODBC para conectar usando a fonte de dados ODBC que você definiu. Selecione Usar Conexão JDBC para conectar usando JDBC. | |
| Fonte de Dados ODBC | Especifica a fonte de dados à qual você deseja se conectar. A lista suspensa exibe as fontes de dados definidas em seu computador. | Esta opção está disponível apenas quando o Tipo de Conexão está definido como Usar Fonte de Dados ODBC. |
| Invocar Administrador ODBC. | Especifica se você deseja iniciar o software Administrador ODBC e exibir a caixa de diálogo Selecionar Fonte de Dados. Você pode então selecionar uma fonte de dados definida anteriormente ou criar uma fonte de dados. | Esta opção está disponível apenas quando o Tipo de Conexão está definido como Usar Fonte de Dados ODBC. |
| String de Conexão | Especifica a string de conexão com base em sua instância JDBC no seguinte formato: jdbc:spark://<server-hostname>:443/default;transportMode=http;ssl=1;httpPath=<http-path> | Esta opção está disponível apenas quando o Tipo de Conexão está definido como Usar Conexão JDBC. Por exemplo: jdbc:spark://<url>.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/<workspaceid>/xxxx |
A captura de tela abaixo mostra a conectividade JDBC via erwin DataModeler ao Databricks SQL Warehouse.
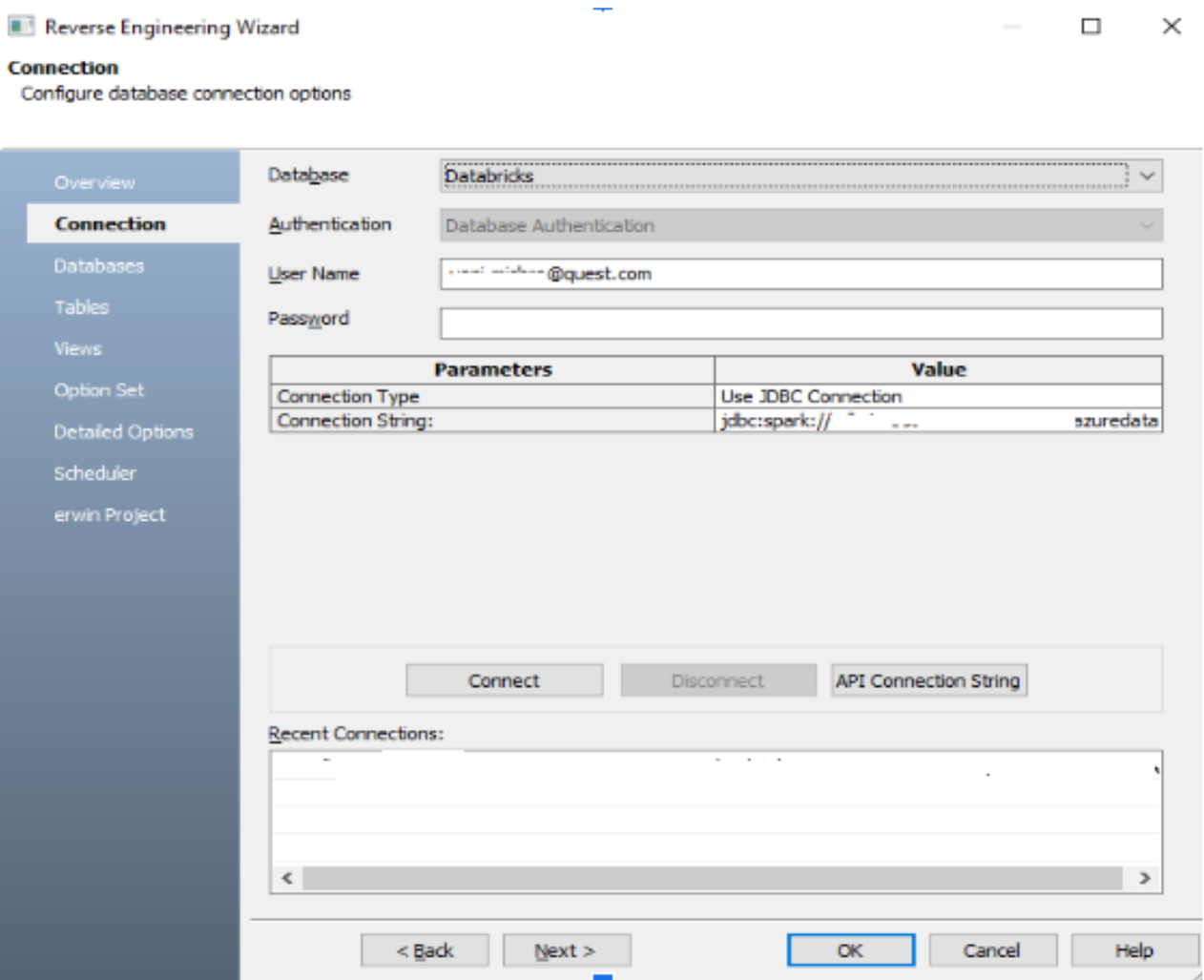
Ele nos permite visualizar todos os bancos de dados disponíveis e selecionar em qual banco de dados queremos construir nosso modelo ERD, como mostrado abaixo.
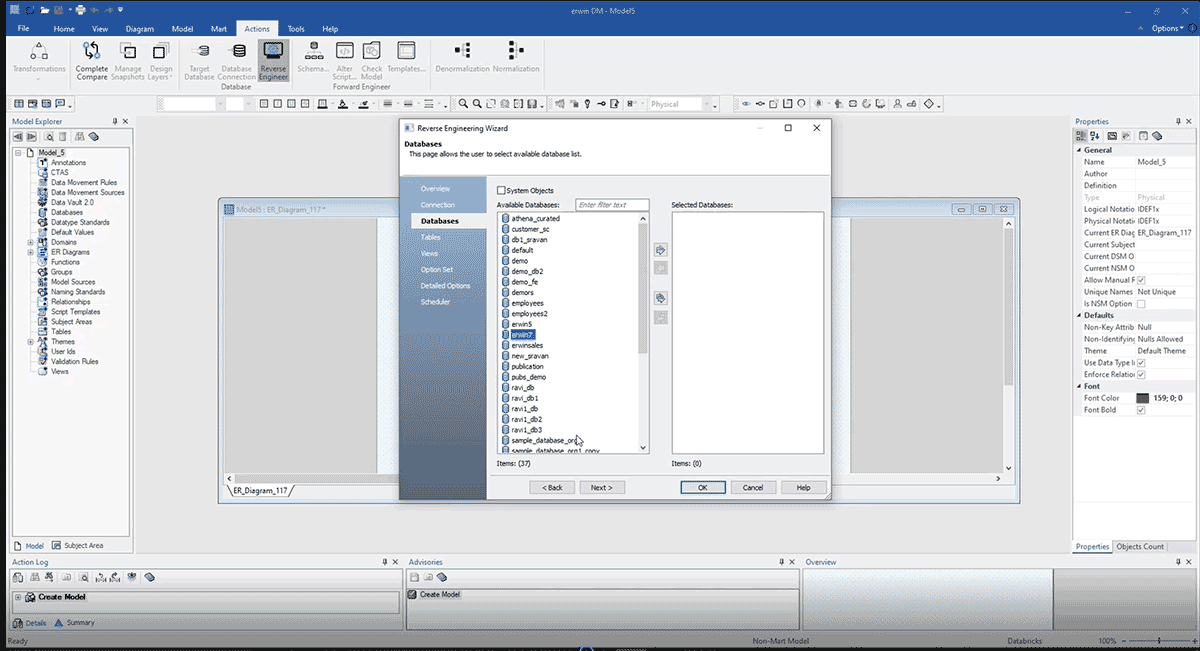
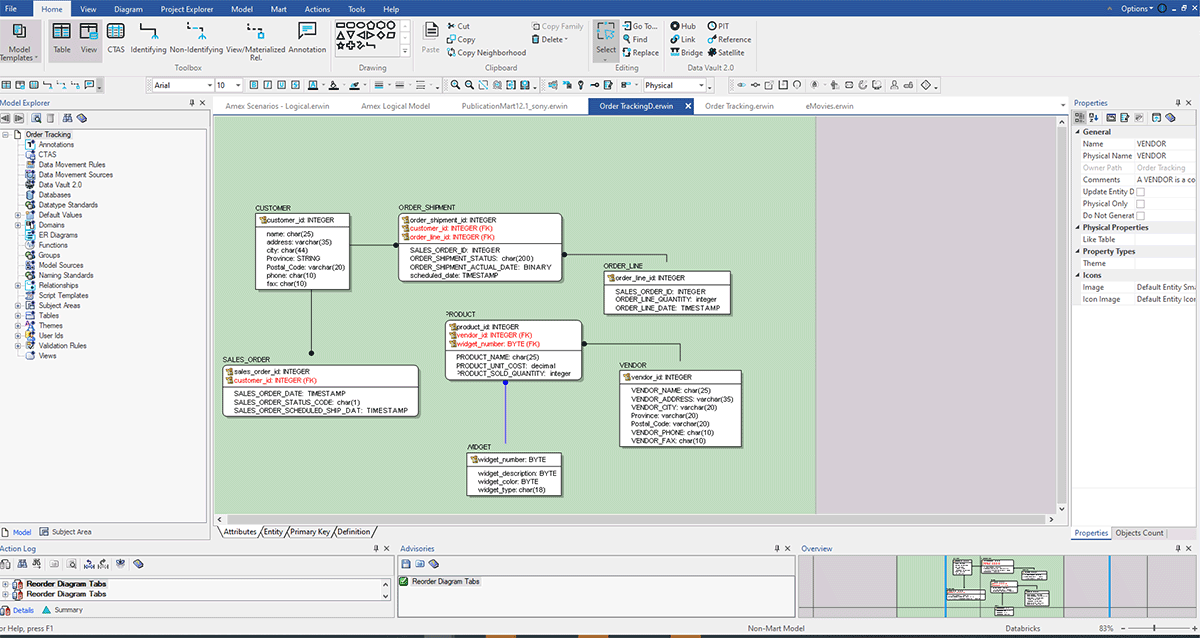
A captura de tela acima mostra um ERD construído após engenharia reversa do Databricks com o método acima. Aqui estão alguns benefícios da engenharia reversa de um modelo de dados:
- Melhor compreensão dos sistemas existentes: Ao fazer engenharia reversa de um sistema existente, você pode entender melhor como ele funciona e como seus vários componentes interagem. Isso ajuda a identificar quaisquer problemas potenciais ou áreas para melhoria.
- Economia de custos: A engenharia reversa pode ajudar a identificar ineficiências em um sistema existente, levando a economia de custos por meio da otimização de processos ou da identificação de áreas de recursos desperdiçados.
- Economia de tempo: A engenharia reversa pode economizar tempo permitindo que você reutilize código ou estruturas de dados existentes em vez de começar do zero.
- Melhor documentação: A engenharia reversa pode ajudar você a criar documentação precisa e atualizada para um sistema existente, o que pode ser útil para manutenção e desenvolvimento futuro.
- Migração mais fácil: A engenharia reversa pode ajudar você a entender as estruturas e relacionamentos dos dados em um sistema existente, facilitando a migração de dados para um novo sistema ou banco de dados.
No geral, a engenharia reversa é valiosa e um passo fundamental para a modelagem de dados. A engenharia reversa permite um entendimento mais profundo de um sistema existente e seus componentes, acesso controlado ao processo de design corporativo, transparência total durante o ciclo de vida da modelagem, melhorias na eficiência, economia de tempo e custo, e melhor documentação, o que leva a melhores objetivos de governança.
Cenário #3: Migrar Modelos de Dados Existentes para Databricks.
Os cenários acima assumem que você está trabalhando com uma única fonte de dados, mas a maioria das empresas possui diferentes data marts e EDWs para dar suporte às suas necessidades de relatórios. Imagine que sua empresa se encaixa nessa descrição e está agora embarcando na criação de um Databricks Lakehouse para consolidar suas plataformas de dados na nuvem em uma plataforma unificada para BI e IA. Nessa situação, será fácil utilizar o erwin Data Modeler para converter seus modelos de dados existentes de um EDW legado para um modelo de dados Databricks. No exemplo abaixo, um modelo de dados criado para um EDW como SQL Server, Oracle ou Teradata pode agora ser implementado no Databricks alterando o banco de dados de destino para Databricks.
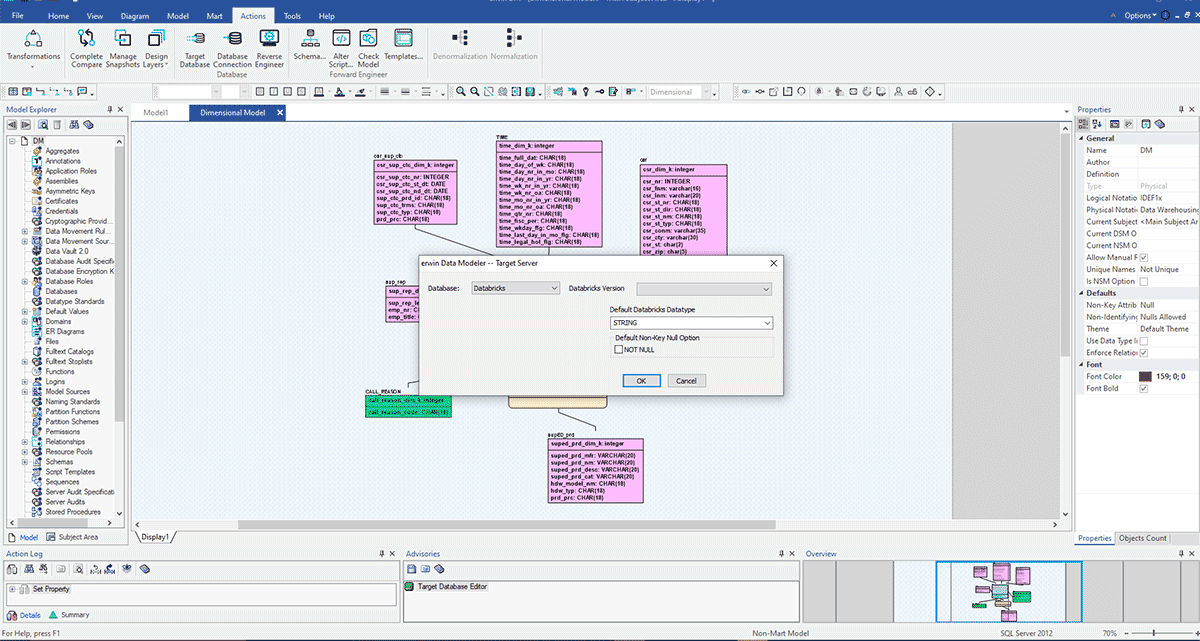
Como você pode ver na área circulada em destaque, este modelo foi criado para SQL Server. Agora, converteremos este modelo e migraremos sua implantação para Databricks alterando o servidor de destino. Esse tipo de conversão fácil de seus modelos de dados ajuda as organizações a migrar modelos de dados de bancos de dados legados ou on-premise para a nuvem de forma rápida e segura, e a governar esses conjuntos de dados ao longo de seu ciclo de vida.
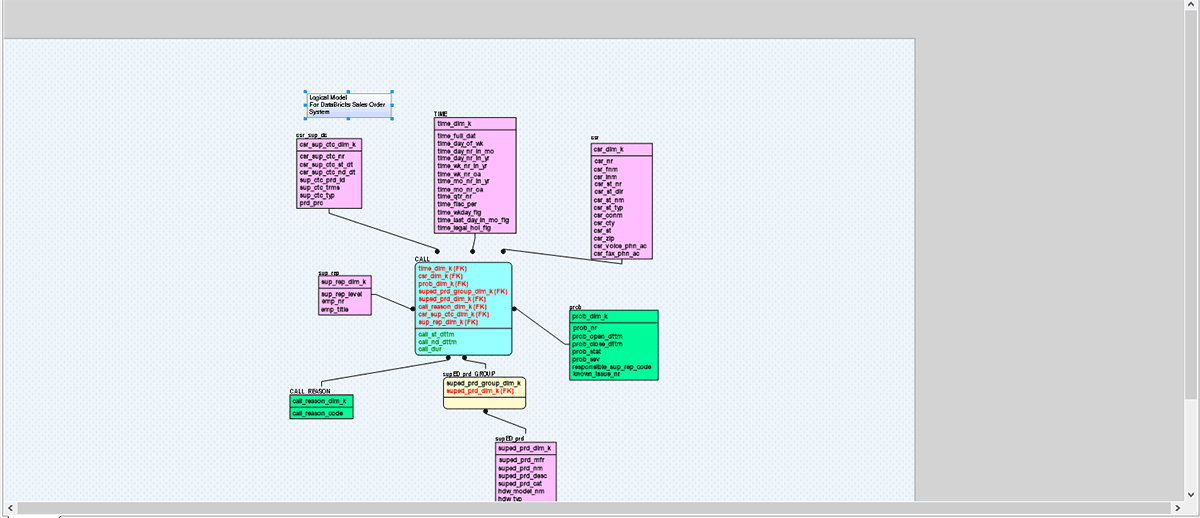
Na imagem acima, tentamos converter um modelo de dados legado baseado em SQL Server para Databricks com alguns passos simples. Esse tipo de caminho de migração fácil permite e ajuda as organizações a migrar rapidamente e com segurança seus dados e ativos para Databricks, incentiva a colaboração remota e aprimora a segurança.
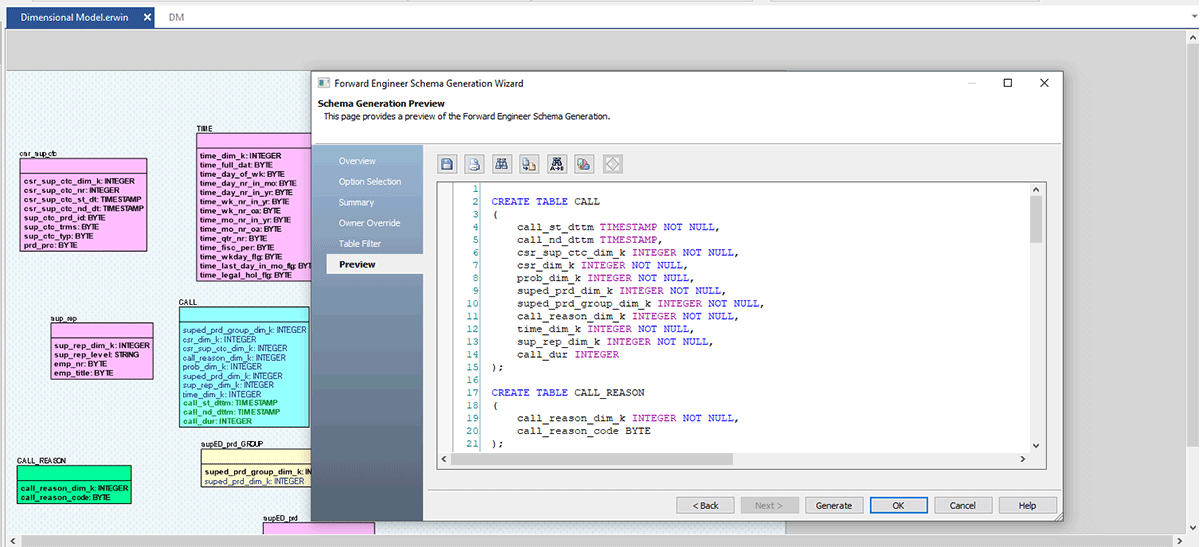
Agora, vamos para nossa parte final; assim que o Modelo ER estiver pronto e aprovado pela equipe de arquitetura de dados, você pode gerar rapidamente um arquivo .sql do erwin DM ou se conectar ao Databricks e fazer a engenharia direta deste modelo para o Databricks.
Siga as capturas de tela abaixo, que explicam o processo passo a passo para criar um arquivo DDL ou um modelo de banco de dados para Databricks.
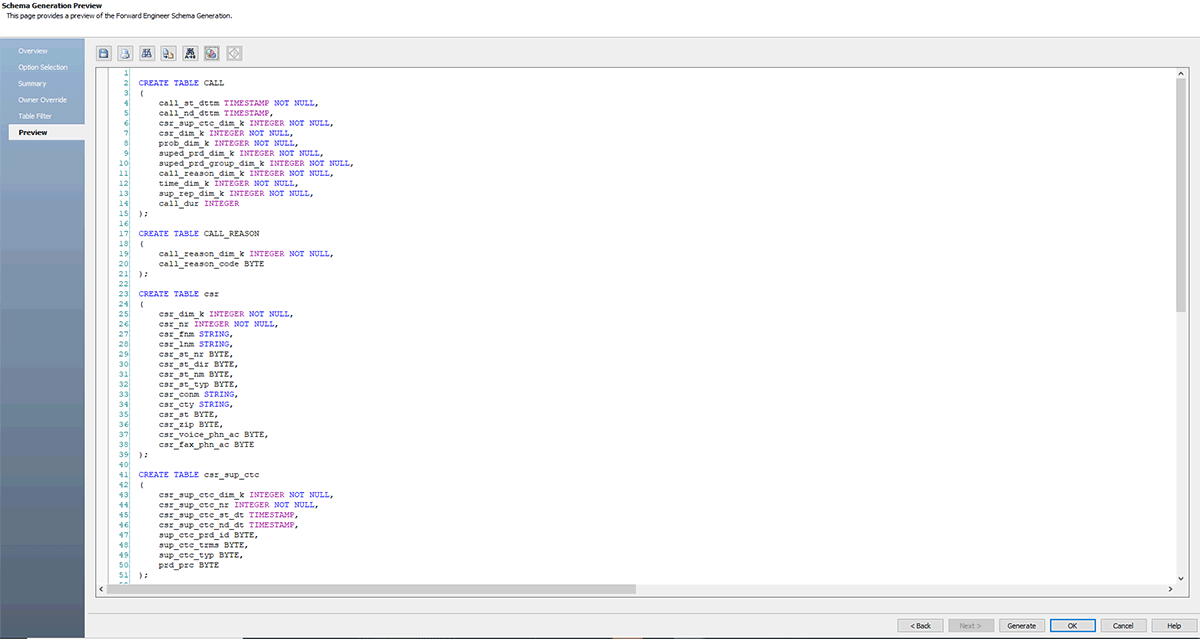
O erwin Data Modeler Mart também suporta GitHub. Esse suporte permite que sua equipe de DevOps atenda ao requisito de controlar seus scripts em repositórios de controle de origem corporativos de sua escolha. Agora, com o suporte do Git, você pode colaborar facilmente com os desenvolvedores e seguir fluxos de trabalho de controle de versão.
Conclusão
Neste blog, demonstramos como é fácil criar, fazer engenharia reversa ou engenharia direta de modelos de dados usando o erwin Data Modeler e criar modelos de dados visuais para migrar suas definições de tabela para Databricks e fazer engenharia reversa de modelos de dados para Governança de Dados e criação de camada semântica.
Esse tipo de prática de modelagem de dados é o elemento chave para agregar valor à sua:
- Prática de governança de dados
- Redução de custos e obtenção de um tempo de valorização mais rápido para seus dados e metadados
- Entendimento e melhoria dos resultados de negócios e seus metadados associados
- Redução de complexidades e riscos
- Melhora da colaboração entre a equipe de TI e os stakeholders de negócios
- Melhor documentação
- Finalmente, um caminho fácil para migrar de bancos de dados legados para a plataforma Databricks
Comece a usar o erwin no Databricks Partner Connect.
Experimente o Databricks gratuitamente por 14 dias.
Experimente o erwin Data modeler
** O erwin DM 12.5 virá com suporte ao Unity Catalog do Databricks, onde você poderá visualizar suas chaves primárias e estrangeiras.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.