Ingestão de Imagens Médicas 7x Mais Rápida com a API Python Data Source
Aproveite as bibliotecas padrão da indústria, pydicom e zipfile com a API Python Data Source para acelerar o pipeline de ingestão de dados DICOM
por Douglas Moore e Allison Wang
- Organizações de saúde e ciências da vida lidam com diversos formatos de dados além de dados estruturados, como imagens DICOM, instrumentos de laboratório, saídas genômicas e arquivos biomédicos, muitas vezes armazenados em formato zip, o que representa desafios para plataformas tradicionais.
- A API de Fonte de Dados Python integra bibliotecas Python de saúde no Spark, permitindo o processamento de arquivos comprimidos em uma única etapa, em vez de pipelines ETL complexos com descompactação e UDFs.
- O uso da API de Fonte de Dados Python alcança um processamento 7x mais rápido, eliminando arquivos temporários (economia de 57x) através de operações em memória e minimizando operações de I/O.
O Desafio dos Dados de Saúde: Além dos Formatos Padrão
Organizações de saúde e ciências da vida lidam com uma diversidade extraordinária de formatos de dados que vão muito além dos dados estruturados tradicionais. Padrões de imagens médicas como DICOM, instrumentos de laboratório proprietários, saídas de sequenciamento genômico e formatos de arquivos biomédicos especializados representam um desafio significativo para as plataformas de dados tradicionais. Embora o Apache Spark™ ofereça suporte robusto para aproximadamente 10 tipos de fontes de dados padrão, o domínio da saúde requer acesso a centenas de formatos e protocolos especializados.
Imagens médicas, abrangendo modalidades como CT, Raio-X, PET, Ultrassom e MRI, são essenciais para muitos processos de diagnóstico e tratamento na área da saúde, em especialidades que vão desde ortopedia até oncologia e obstetrícia. O desafio se torna ainda mais complexo quando essas imagens médicas são comprimidas, arquivadas ou armazenadas em formatos proprietários que requerem bibliotecas Python especializadas para processamento.
Os arquivos DICOM contêm uma seção de cabeçalho com metadados ricos. Existem mais de 4200 tags DICOM definidas como padrão. Alguns clientes implementam tags de metadados personalizadas. A fonte de dados “zipdcm” foi criada para acelerar a extração dessas tags de metadados.
O Problema: Processamento Lento de Imagens Médicas
As organizações de saúde costumam armazenar imagens médicas em arquivos ZIP compactados contendo milhares de arquivos DICOM. O processamento desses arquivos em grande escala normalmente requer várias etapas:
- Extrair arquivos ZIP para armazenamento temporário
- Processar arquivos DICOM individuais usando bibliotecas Python como pydicom
- Carregar resultados no Delta Lake para análise
A Databricks lançou um Acelerador de Soluções, dbx.pixels, que facilita a integração de centenas de formatos de imagem em grande escala. No entanto, o processo ainda pode ser lento devido às operações de disco I/O e ao manuseio de arquivos temporários.
A Solução: Python Data Source API
A nova API de Fonte de Dados Python resolve isso, permitindo a integração direta de bibliotecas Python específicas para saúde no framework de processamento distribuído do Spark. Em vez de construir pipelines ETL complexos para primeiro descompactar arquivos e depois processá-los com Funções Definidas pelo Usuário (UDFs), você pode processar imagens médicas comprimidas em uma única etapa.
Uma fonte de dados personalizada, implementada usando a API de Fonte de Dados Python, combinando a extração de arquivos ZIP com o processamento DICOM, oferece resultados impressionantes: processamento 7x mais rápido em comparação com a abordagem tradicional.
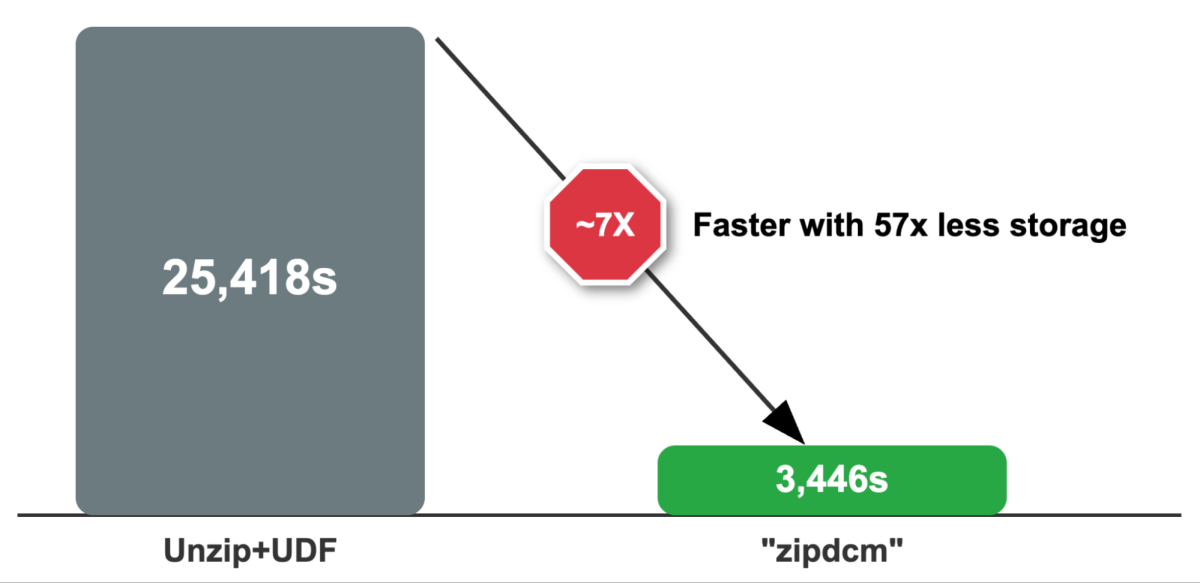
O leitor ”zipdcm” processou 1.416 arquivos zip contendo mais de 107.000 arquivos DICOM totais em 2,43 segundos por arquivo DICOM. Testadores independentes relataram desempenho 10 vezes mais rápido. O cluster usado tinha dois nós de trabalho, cada um com 8 v-cores. O tempo de execução do leitor ”zipdcm” foi de apenas 3,5 minutos.
Ao manter os dados de origem compactados, e não expandindo os arquivos zip de origem, percebemos uma redução notável (4TB descompactado vs 70GB compactado) de 57 vezes nos custos de armazenamento em nuvem.
Implementando a Fonte de Dados DICOM Compactada
Aqui está como construir uma fonte de dados personalizada que processa arquivos ZIP contendo imagens DICOM encontradas no github
O cerne da leitura de arquivos DICOM em um arquivo Zip (fonte original):
Altere este loop para processar outros tipos de arquivos aninhados em um arquivo zip, zip_fp é o manipulador de arquivo do arquivo dentro do arquivo zip. Com o trecho de código acima, você pode começar a ver como os membros individuais do arquivo zip são endereçados individualmente.
Alguns aspectos importantes deste design de código:
- Os metadados DICOM são retornados via
yield, que é uma técnica eficiente em termos de memória, pois não estamos acumulando a totalidade dos metadados na memória. Os metadados de um único arquivo DICOM são apenas alguns kilobytes. - Descartamos os dados de pixel para reduzir ainda mais a pegada de memória desta fonte de dados.
Com modificações adicionais no partitions() método, você pode até ter várias tarefas Spark operando no mesmo arquivo zip. Para DICOMs, normalmente, arquivos zip são usados para manter fatias individuais ou quadros de uma varredura 3D todos juntos em um arquivo.
Em geral, em um alto nível, o <name_of_data_source>) como mostrado no trecho de código abaixo:
Onde a pasta de dados se parece com (a fonte de dados pode ler arquivos dcm simples e compactados):
Por que 7x mais rápido?
Vários fatores contribuem para a melhoria de 7x mais rápido ao implementar uma fonte de dados personalizada usando Python Data Source API. Eles incluem o seguinte:
- Sem arquivos temporários: As abordagens tradicionais escrevem arquivos DICOM descompactados no disco. A fonte de dados personalizada processa tudo na memória.
- Redução no número de arquivos para abrir: Em nosso conjunto de dados [DOI: 10.7937/cf2p-aw56]1 do The Cancer Imaging Archive (TCIA), encontramos 1.412 arquivos zip contendo 107.000 arquivos DICOM e de texto de licença individuais. Isso é uma expansão de 100x no número de arquivos para abrir e processar.
- Leituras parciais: Nossa fonte de dados zipdcm de metadados DICOM descarta as tags de dados de imagem maiores relacionadas
"60003000,7FE00010,00283010,00283006") - Menor IO para e do armazenamento: Antes, com o descompactar, tínhamos que escrever 107.000 arquivos, totalizando 4TB de armazenamento. Os dados comprimidos baixados do TCIA eram apenas 71 GB. Com o leitor
zipdcm, economizamos mais de 210.000 operações de IO de arquivo individuais. - Paralelismo Consciente de Partição: Como o iterador expõe tanto os ZIPs de nível superior quanto os membros dentro de cada arquivo, a fonte de dados pode criar várias partições lógicas contra um único arquivo ZIP. Portanto, o Spark distribui a carga de trabalho entre muitos núcleos de execução sem primeiro inflar o arquivo em um disco compartilhado.
Juntas, essas otimizações deslocam o gargalo do disco e da rede I/O para a análise pura da CPU, proporcionando uma redução observada de 7x no tempo de execução de ponta a ponta no conjunto de dados de referência, mantendo o uso da memória previsível e limitado.
Além da Imagem Médica: O Ecossistema Python de Saúde
A API de Fonte de Dados Python abre acesso ao rico ecossistema de pacotes Python para saúde e ciências da vida:
- Imagem Médica: pydicom, SimpleITK, scikit-image para processamento de vários formatos de imagem médica
- Genômica: BioPython, pysam, genomics-python para processamento de dados de sequenciamento genômico
- Dados de Laboratório: Analisadores especializados para citometria de fluxo, espectrometria de massa e instrumentos de laboratório clínico
- Farmacêutica: RDKit para informática química e fluxos de trabalho de descoberta de medicamentos
- Dados Clínicos: Bibliotecas de processamento HL7 para padrões de interoperabilidade em saúde
Cada um desses domínios possui bibliotecas Python maduras e testadas em batalha que agora podem ser integradas em pipelines Spark escaláveis. A dominância do Python na ciência de dados de saúde finalmente se traduz em engenharia de dados em escala de produção.
Introdução
O post do blog discute como a API de Fonte de Dados Python, combinada com o Apache Spark, melhora significativamente a ingestão de imagens médicas. Destaca uma aceleração de 7x na indexação e hashing de arquivos DICOM, processando mais de 100.000 arquivos DICOM em menos de quatro minutos e reduzindo o armazenamento em 57x. O mercado para análises de imagens de radiologia é avaliado em mais de $40 bilhões anualmente, tornando esses ganhos de desempenho uma oportunidade para ajudar a reduzir custos enquanto acelera a automação de fluxos de trabalho. Os autores agradecem aos criadores do conjunto de dados de benchmark usado em seu estudo.
Rutherford, M. W., Nolan, T., Pei, L., Wagner, U., Pan, Q., Farmer, P., Smith, K., Kopchick, B., Laura Opsahl-Ong, Sutton, G., Clunie, D. A., Farahani, K., & Prior, F. (2025). Data in Support of the MIDI-B Challenge (MIDI-B-Synthetic-Validation, MIDI-B-Curated-Validation, MIDI-B-Synthetic-Test, MIDI-B-Curated-Test) (Version 1) [Dataset]. The Cancer Imaging Archive. https://doi.org/10.7937/CF2P-AW56
Experimente as fontes de dados ("fake", "zipcsv" e "zipdcm") com dados de amostra fornecidos, todos encontrados aqui: https://github.com/databricks-industry-solutions/python-data-sources
Entre em contato com a equipe de sua conta Databricks para compartilhar seu caso de uso e estratégias sobre como aumentar a ingestão de suas fontes de dados favoritas para seus casos de uso analítico.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.