Acelerando o MDM de Provedor em Saúde com Databricks e IA
Começando com o Gerenciamento de Dados Mestres (MDM) na indústria de saúde utilizando Databricks
por Haritha Sama, Roz King e Aaron Zavora
- Saiba mais sobre LakeFusion MDM, construído nativamente no Databricks
- Entenda como dominar os dados do provedor em escala, impulsionar a excelência operacional e habilitar análises avançadas
- Desbloqueie o potencial total de uma solução aceleradora MDM de Provedor abrangente e de ponta a ponta
As operações de saúde e o cuidado ao paciente dependem de dados precisos, completos e unificados. De garantir o processamento oportuno de reclamações e o encaminhamento eficiente de referências a fornecer análises de desempenho perspicazes e manter a conformidade regulatória, uma única fonte confiável de verdade é primordial.
As informações do provedor continuam sendo um dos conjuntos de dados mais complexos e desafiadores para as organizações de saúde, criando barreiras para uma única fonte de verdade. Os dados do provedor são gerenciados em muitas fontes distintas: Registros Médicos Eletrônicos (EMRs), o Sistema Nacional de Enumeração de Planos e Provedores (NPPES), sistemas de reclamações, bancos de dados de credenciamento, diretórios externos e mais. Todos esses sistemas representam os provedores de maneira ligeiramente diferente e criam inúmeros desafios na interoperabilidade que servem como uma barreira para análises e insights valiosos de saúde.
A oportunidade com o Gerenciamento de Dados Mestre (MDM) para enfrentar este desafio
As soluções de Gerenciamento de Dados Mestres (MDM) enfrentam esses problemas movendo dados de sistemas de origem e sistemas analíticos, processando-os e depois os movendo de volta. Esta abordagem de "mover primeiro" introduz desafios significativos: pipelines de dados complexos, aumento da latência, obstáculos de governança e custos de infraestrutura substanciais. É um modelo que luta para acompanhar o volume, velocidade e variedade dos dados modernos de saúde.
É aí que a Plataforma de Inteligência de Dados Databricks, construída sobre a arquitetura lakehouse, pode ajudar. Ao reunir dados e processamento, a Databricks permite que as organizações superem as limitações das arquiteturas tradicionais e desbloqueiem novas possibilidades para o gerenciamento de dados. Utilizando o princípio da "gravidade dos dados", Databricks permite que você processe os dados onde eles estão, reduzindo o custoso e complexo movimento de dados.
Para ajudar as organizações de saúde a acelerar sua jornada na Databricks e enfrentar o problema do MDM do provedor, estamos animados em apresentar um produto da Frisco Analytics LakeFusion e um Accelerator Provider 360 acompanhante. Construído nativamente na Databricks, esta ferramenta alimentada por IA representa um passo significativo para alcançar um MDM de Provedor abrangente.
O Desafio Persistente dos Dados do Provedor
Os sistemas MDM tradicionais muitas vezes lutam com a ambiguidade inerente e a variabilidade nos dados do provedor. Inserir novas fontes de informação do provedor e permutações da representação do provedor se torna cada vez mais difícil, demorado e caro. Confiar apenas em correspondências exatas, regras rígidas ou algoritmos difusos como a distância de Levenshtein (a distância entre 2 frases) pode perder muitas duplicatas (por exemplo, variações na ortografia do nome, formatação de endereço) e requer manutenção constante à medida que as fontes de dados mudam e não escala para níveis empresariais.
Acelerando a Qualidade de Dados do Provedor com Databricks e IA
Seja as organizações estão consumindo informações do diretório do provedor ou transparência de preços do mandato CMS-9115-F, construindo modelos de atribuição para iniciativas de Cuidado Baseado em Valor (VBC), impulsionando melhores métricas de qualidade e utilização através de um registro dourado do provedor, ou limpando representações de sistema interno de dados do provedor, resolução de entidade alimentada por IA do Lakefusion na Databricks brilha. Em vez de depender de regras frágeis, podemos aproveitar técnicas avançadas como modelos de incorporação e busca de vetores para entender a similaridade semântica entre os registros do provedor. Isso nos permite identificar registros que são semelhantes, mesmo que não correspondam exatamente aos identificadores tradicionais.
As principais capacidades do LakeFusion incluem:
- Resolução de Entidade Avançada Alimentada por IA: Construindo sobre os conceitos de modelos de incorporação e busca vetorial, LakeFusion utiliza grandes modelos de linguagem (LLMs) e algoritmos de correspondência sofisticados para uma resolução de entidade altamente precisa e escalável, mesmo para hierarquias e relações de provedores complexas.
- Framework Robusto de Qualidade de Dados: Perfil, limpeza, validação e monitoramento da qualidade dos dados usando regras configuráveis e processos automatizados.
- Sobrevivência Configurável: Defina regras para determinar automaticamente os atributos do "registro dourado" ao mesclar registros duplicados de várias fontes.
- Administração de Dados Gráfica e Intuitiva: Forneça aos administradores de dados uma interface amigável para revisar possíveis correspondências, resolver exceções e gerenciar problemas de qualidade de dados.
- Integração de Governança de Dados Sem Costura: Aproveita totalmente o Catálogo Unity da Databricks para governança de dados centralizada, rastreamento de linhagem, controle de acesso e auditoria em seus dados dominados.
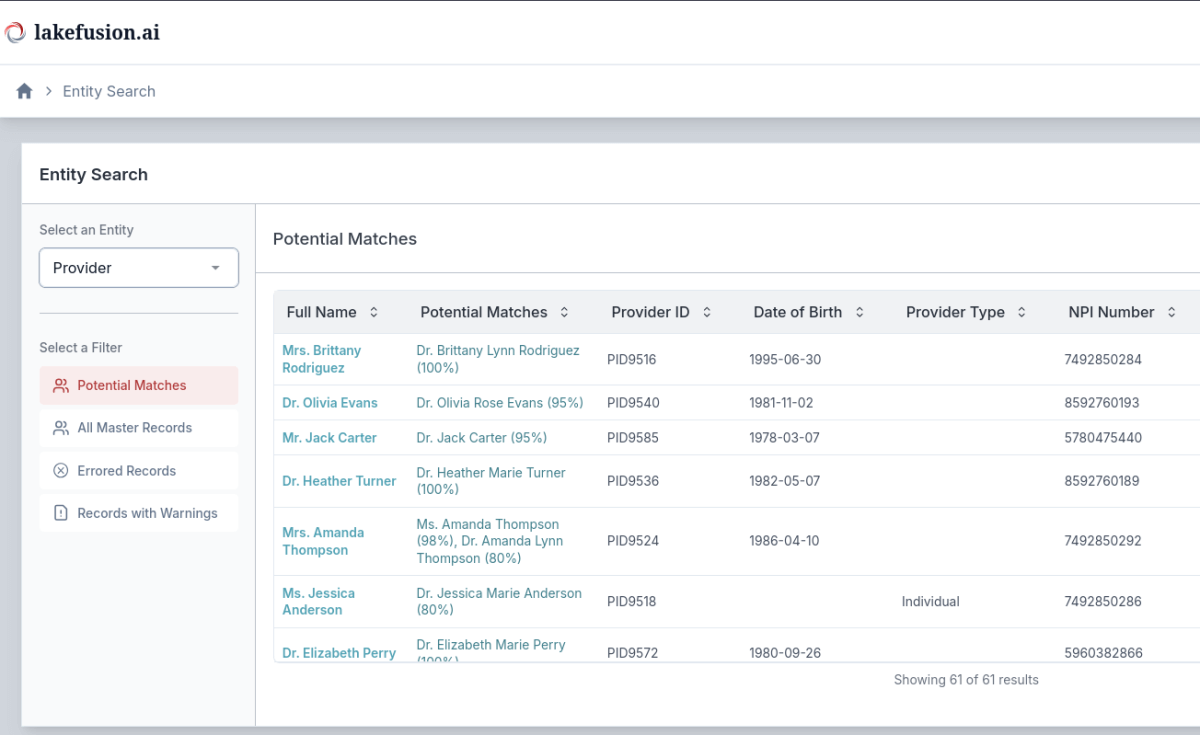
O Provider 360 Accelerator é de código aberto e demonstra essa capacidade em ação. Sua função principal é aplicar a desduplicação de registros alimentada por IA aos seus dados de provedor usando Busca Vetorial e modelos de incorporação de última geração disponíveis no Databricks. O conjunto de notebooks de código aberto inclui:
- Notebook 1 - Geração de Candidatos a Duplicatas: Realiza a correspondência difusa alimentada por IA em seus dados, utilizando a Busca Vetorial para encontrar possíveis duplicatas para cada registro.
- Notebook 2 - Análise de Candidatos Duplicados: Fornece insights analíticos sobre as pontuações de similaridade dos pares de candidatos, ajudando você a entender a extensão das duplicatas e determinar os limiares de confiança certos para seus dados.
- Notebook 3 - Desduplicação Baseada em Limiar: Aplica seus limiares escolhidos para filtrar os dados originais, gerando um conjunto de dados mais limpo ao remover prováveis duplicatas.
O desafio de gerenciar dados complexos de provedores de saúde é real, mas a solução está ao nosso alcance. Ao utilizar o poder do Databricks e os últimos avanços em IA, as organizações podem acelerar significativamente sua jornada em direção a dados de provedor confiáveis.
Para organizações prontas para desbloquear o potencial total de uma solução MDM de Provedor abrangente e de ponta a ponta, LakeFusion MDM, construído nativamente no Databricks, oferece as capacidades necessárias para dominar os dados do provedor em escala, impulsionar a excelência operacional e habilitar análises avançadas.
Pronto para acelerar sua jornada de MDM do Provedor?
- Explore os notebooks Provider 360 Deduplication Accelerator de código aberto no GitHub/Databricks Repo
- Saiba mais sobre LakeFusion MDM no Marketplace Databricks
- Conecte-se com Frisco Analytics para discutir seus desafios de dados de saúde e como LakeFusion pode ajudar via https://www.lakefusion.ai/ ou https://www.friscoanalytics.com/
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.