Plataforma de serving de AI que se adapta ao seu modelo
Uma plataforma para todos os modelos de IA — ML clássico, deep learning e agentes — mais de 300 mil QPS, menos de 10ms, sem ajustes
por Anshul Gupta
- O que é: Uma plataforma totalmente gerenciada que executa qualquer modelo em produção, desde um classificador scikit-learn de 2 MB em um único núcleo de CPU até um LLM de 70B com ajuste fino em oito GPUs, sem ajustes manuais.
- O desafio que resolve: Modelos personalizados têm perfis de recursos e padrões de tráfego extremamente diferentes, por isso nenhuma configuração estática única serve para todos. Em vez disso, a plataforma se adapta, mantendo a latência baixa e garantindo a eficiência de cada nó.
- Os resultados: Mais de 300 mil QPS com sobrecarga de latência p99 de <10ms e redução de até 90% nos custos de infraestrutura para clientes que migram de infraestruturas autogerenciadas.
Desafios na execução de inferências de modelos personalizados
Quando você implanta um modelo de machine learning em produção, está se comprometendo com um contrato: cada solicitação é concluída em poucos milissegundos, independentemente de picos de tráfego, e sua fatura permanece baixa quando o tráfego está baixo. O serviço de modelos é a infraestrutura que mantém esse contrato e, durante a maior parte da história do setor, mantê-lo tem sido tão difícil quanto criar o próprio modelo.
Modelos personalizados são fundamentalmente diferentes de modelos de fundação. Uma plataforma que hospeda um modelo de fundação (Llama, Mistral, uma variante do CLIP) sabe exatamente o que está executando: a arquitetura, o consumo de memória, as características de inferência, e pode otimizar profundamente para esse modelo específico. As plataformas de modelos personalizados são o oposto. A mesma plataforma precisa servir um classificador scikit-learn de 2 MB em um único núcleo de CPU e um LLM de 70B com ajuste fino em oito GPUs; um modelo de ranqueamento de baixa latência que não tolera filas e um modelo de embeddings que se beneficia de um processamento em lote agressivo. Uma plataforma que precisa servir todos os tipos de modelos, sendo que nenhum deles compartilha o mesmo perfil de recursos, formato de tráfego ou orçamento de latência.
As plataformas tradicionais transferem essa complexidade de volta para o cliente: contagem de réplicas, simultaneidade por réplica, limites de escalonamento automático. Isso ainda é DIY, apenas em um nível de abstração mais alto. E nunca para: cada novo modelo e mudança de tráfego exige uma nova análise de perfil e novos ajustes, de modo que seus melhores engenheiros acabam apagando incêndios em produção antes e depois do lançamento, e a disponibilização dos modelos se torna a âncora que atrasa cada lançamento. O resultado é o custo que mais importa: modelos validados em desenvolvimento ficam parados por semanas antes de chegarem à produção.
Nossa missão: eliminar a taxa do Stack de ML
Ajustar manualmente a infraestrutura de serviço é uma taxa cobrada sobre cada modelo que uma organização executa; em escala, isso se torna estrutural, com equipes criando grupos dedicados de serviço cujo único trabalho é manter os modelos ativos e com bom desempenho em produção. Chamamos isso de Taxa do Stack de ML.
O Databricks Custom Model Serving é uma plataforma de inferência em tempo real totalmente gerenciada para qualquer modelo empacotado no MLflow. Nossa missão é eliminar essa taxa nas três etapas da vida de um modelo, para que as equipes de serviço dos nossos clientes possam se concentrar em gerar valor de forma mais sofisticada:
- Simplificar a pré-produção. Um modelo treinado no Databricks é implantado com um único clique — nós combinamos o ambiente de forma exata, sem surpresas no tempo de execução, e otimizamos o tempo de implantação para que a iteração e o rollback continuem rápidos.
- Tornar a produção confiável, escalável e econômica. A infraestrutura se adapta a cada modelo e ao seu tráfego em tempo de execução, mantendo a latência baixa e os custos reduzidos, sem a necessidade de configurações manuais. (O foco deste post.)
- Simplificar a pós-produção. Cada endpoint emite telemetria para o Unity Catalog de forma nativa (métricas, logs e rastreamentos nativos de OTel, tabelas de inferência instantâneas capturando cada solicitação para o Delta e MLflow Tracing). O Genie Code opera sobre tudo isso para fornecer uma observabilidade operacional baseada em agentes pioneira no mercado. A observabilidade para IA é um problema de contexto, e todo o contexto reside em uma única plataforma.
Isso funciona porque o Custom Model Serving é integrado nativamente ao Databricks: dados, features, treinamento, empacotamento do MLflow, serviço e agentes formam um único stack governado, e não sistemas separados interligados.
Este post aborda a segunda etapa sobre como alcançamos mais de 300 mil QPS com baixa latência em uma ampla variedade de modelos usando uma abordagem sem configurações manuais. É isso que faz a taxa desaparecer.
Arquitetura
Três restrições moldam cada decisão na arquitetura: baixa latência, alta escala e eficiência de custos. Elas se contrapõem (a maneira mais fácil de reduzir a latência é o superprovisionamento, e a maneira mais fácil de reduzir custos é o subprovisionamento) e equilibrar as três ao mesmo tempo, para todos os tipos de modelos, sem qualquer desperdício de recursos, é o verdadeiro desafio de engenharia.
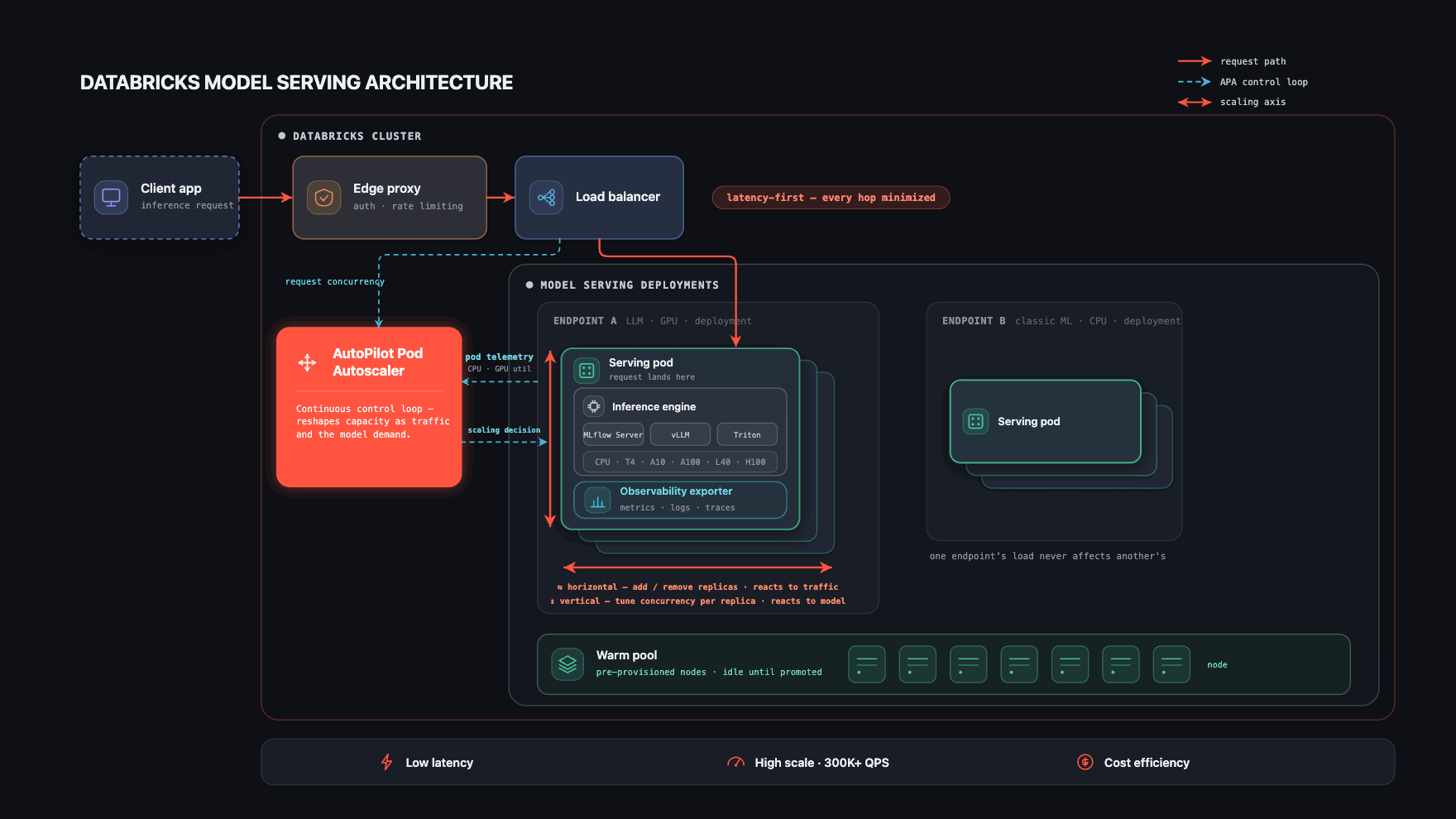
Três fatores fazem isso funcionar.
- Um caminho de solicitação curto e isolado que mantém o impacto na latência mínimo em cada salto.
- Seleção automática de tempo de execução (runtime) - cada modelo é servido no mecanismo de inferência mais adequado para ele.
- O coração da plataforma — um autoscaler que se adapta tanto ao modelo quanto ao seu tráfego em tempo real, mantendo a latência baixa e a escala alta, enquanto reduz os custos.
Os dois primeiros mantêm uma única solicitação rápida; o terceiro mantém todo o sistema rápido e econômico à medida que os modelos e o tráfego mudam. A maior parte desta seção é sobre o terceiro fator.
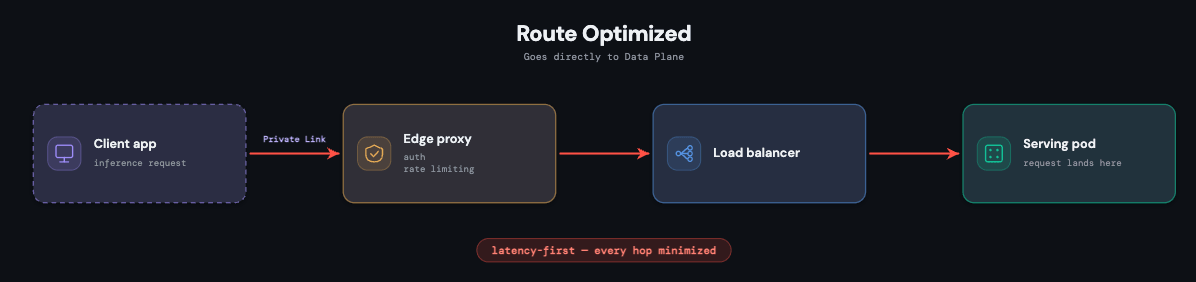
Caminho de solicitação curto e isolado
Cada endpoint de serviço é uma implantação do Kubernetes totalmente isolada com seus próprios pods e uma imagem de contêiner específica para a versão do modelo. Esse isolamento é deliberado: o tráfego, as falhas ou a pressão de recursos de um endpoint não podem afetar os de outro, mantendo as cargas de trabalho personalizadas seguras.
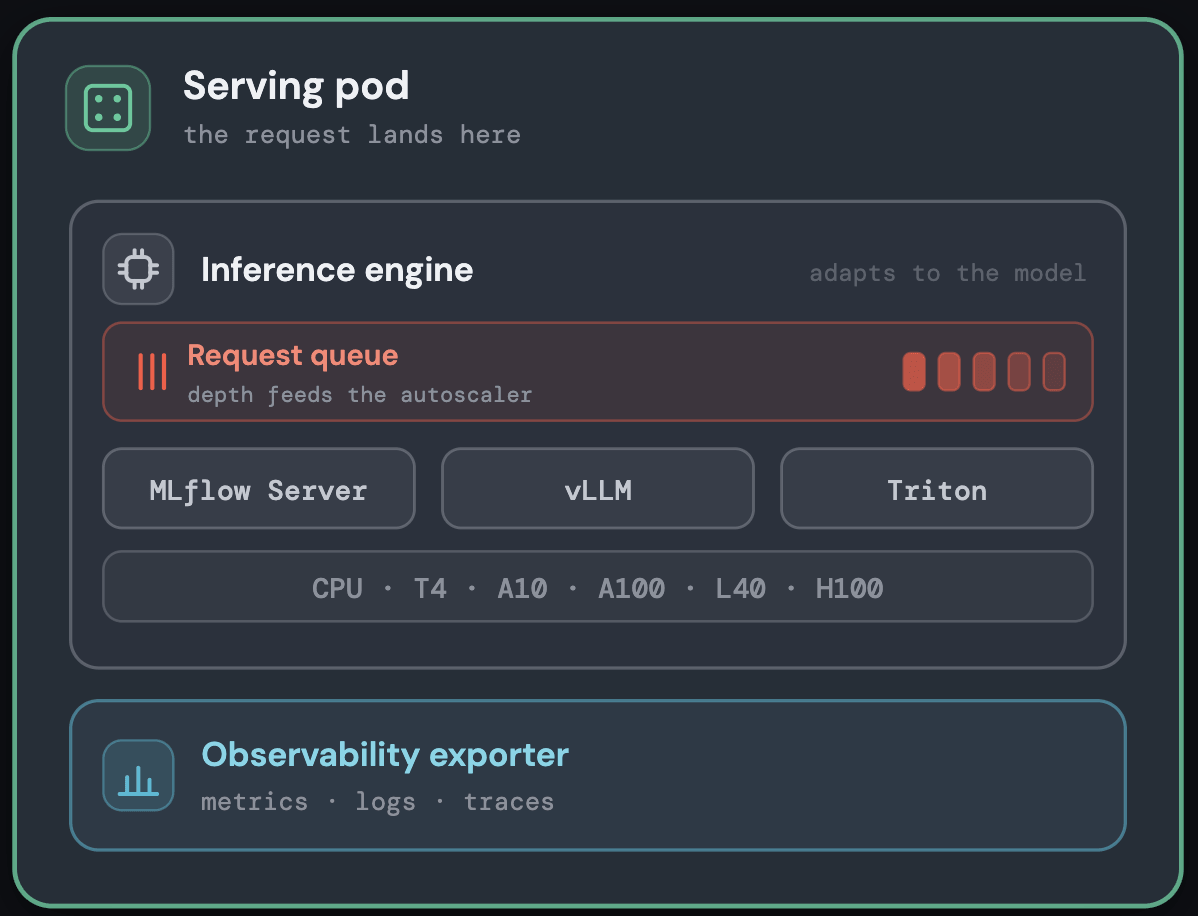
O caminho em si é mantido o mais curto possível, pois a latência é uma restrição de primeira classe em todas as camadas. Uma solicitação chega por meio de um proxy PoP; uma vez autenticada, ela passa por um balanceador de carga compartilhado para gerenciamento de conexões e chega imediatamente ao pod que a atende. Cada pod também executa um sidecar de observabilidade que exporta métricas, logs, logs de payload e rastreamentos, tanto para o monitoramento da plataforma quanto para painéis voltados ao cliente.
Seleção eficiente de tempo de execução (runtime) do modelo
Dentro de cada pod, o modelo é executado no mecanismo de inferência mais adequado ao seu tipo — um servidor assíncrono Gunicorn MLflow para modelos de ML clássicos e mecanismos otimizados para GPU para modelos grandes com suporte para vLLM, Triton ou o próprio runtime do cliente — tudo por trás de uma interface de serviço uniforme.
Associar cada modelo ao runtime correto mantém o overhead por solicitação baixo, sem a necessidade de ajustes manuais; os detalhes são mostrados no diagrama abaixo.
O Autoscaler: adaptando-se ao modelo e ao tráfego
Um controlador personalizado do Kubernetes que desenvolvemos — o AutoPilot Pod Autoscaler (APA) — fica no centro da plataforma. Ele coleta continuamente sinais do balanceador de carga (simultaneidade ativa, profundidade da fila) e dos próprios pods (utilização de CPU, utilização de GPU, memória de GPU e muitos outros) e os transforma em decisões de escalonamento.
O autoscaler existe para absorver dois tipos de imprevisibilidade ao mesmo tempo:
- O modelo é imprevisível. Você não conhece o perfil de recursos de um modelo personalizado com antecedência. Um modelo xgboost com uso intenso de CPU pode atender a apenas 1 solicitação por núcleo, um agente pode executar centenas de solicitações por núcleo, enquanto um LLM de 13B com ajuste fino se beneficia de várias solicitações agrupadas em lote. O APA aprende o limite de cada modelo em tempo de execução e ajusta quantas solicitações cada réplica deve aceitar: escalonamento vertical ciente do modelo.
- O tráfego é imprevisível. Ele apresenta picos, rajadas e cai para zero sem aviso prévio. Um endpoint de fraude pode aumentar 10 vezes em segundos no início de uma promoção; um caso de uso específico de uma região é muito acessado por uma hora e depois fica ocioso durante a noite. O APA reage no instante em que a demanda muda: escalonamento horizontal baseado em solicitações.
É por isso que o autoscaler é o coração do sistema: ele é o único componente que gerencia as três restrições — latência, escala e custo — ao mesmo tempo, para cada modelo na plataforma.
Dois eixos de elasticidade
Os autoscalers tradicionais realizam o escalonamento automático baseado em solicitações ou em recursos, mas cada um tem um ponto fraco. O escalonamento baseado em solicitações reage rapidamente, mas é ineficiente — ele trata cada solicitação de forma idêntica, independentemente de quão carregada cada réplica esteja, fazendo com que você superprovisione ou cause oscilações constantes no número de réplicas. O escalonamento baseado em recursos (utilização de CPU, GPU) é eficiente, mas apresenta atrasos — as métricas de utilização acompanham o tráfego com atraso, de modo que, no momento em que o autoscaler é acionado, o impacto no p99 já ocorreu.
O APA usa ambos os sinais ao mesmo tempo, cada um atuando onde é melhor — e esses são exatamente os dois eixos.
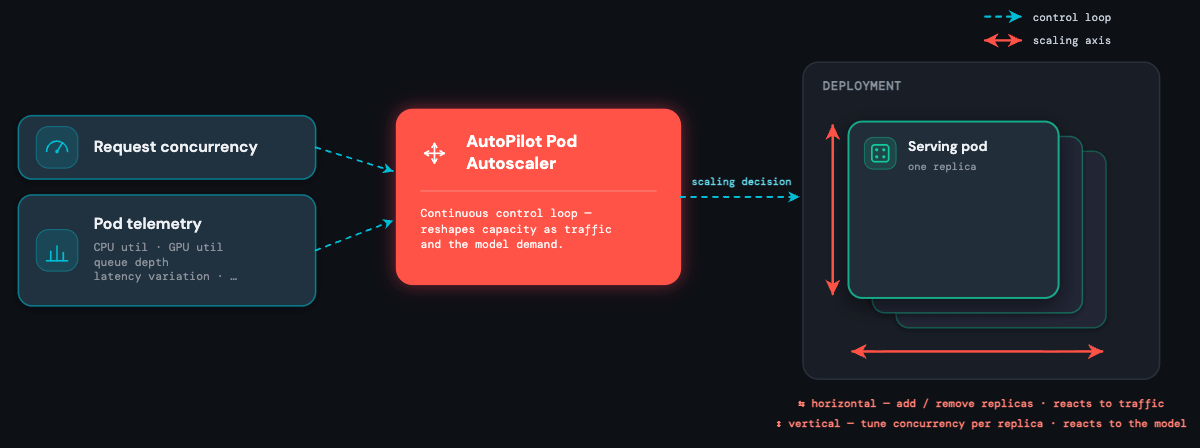
O escalonamento horizontal reage às solicitações. Ele monitora as solicitações simultâneas ativas por endpoint e adiciona ou remove réplicas no momento em que a demanda muda. A fórmula segue o Horizontal Pod Autoscaler do Kubernetes:
O dimensionamento vertical baseado no modelo reage às características do modelo. Periodicamente, o autoscaler analisa um conjunto de métricas para determinar quanta carga uma única réplica pode realmente suportar e ajusta o target_concurrency na fórmula acima de acordo. Isso é fundamentalmente diferente do dimensionamento vertical tradicional, que altera o tipo de hardware. Aqui o hardware permanece o mesmo: o que muda é quantas solicitações simultâneas cada pod aceita, ajustadas ao perfil de recursos do modelo em execução nele.
As métricas em que nos baseamos incluem, entre outras:
- Métricas de hardware — utilização de CPU e GPU, utilização de memória, espera de I/O
- Latência atual e perfil de profundidade da fila
- Métricas específicas de GPU — largura de banda de memória, utilização de FLOPS de FP16/BF16
Salvaguardas. As alterações de concorrência por nó são sensíveis, e variações grandes ou frequentes podem deteriorar o desempenho do sistema. As métricas dos pods podem flutuar devido a breves mudanças no tráfego ou quando o custo por solicitação varia muito para um modelo. Nós nos protegemos contra esse ruído de métricas. Um breve pico de CPU não deve reduzir imediatamente o limite de concorrência para depois expandi-lo novamente segundos mais tarde. Adotamos três etapas para isso:
A concorrência é ajustada apenas quando uma métrica ultrapassa um limite estável, e os limites são ajustados por métrica.
- Limitamos a alteração máxima de concorrência por ciclo de decisão
- Sempre aplicamos limites mínimos/máximos de concorrência para uma carga de trabalho
- As alterações de concorrência ocorrem em uma cadência menor (a cada 30s) em comparação com o dimensionamento horizontal. Isso também é importante porque elas dependem de métricas históricas, ao contrário do tráfego atual, como o HPA.
Os dois eixos estão acoplados: a saída de concorrência do dimensionamento vertical alimenta o cálculo no dimensionamento horizontal por meio do denominador target_concurrency. O dimensionamento horizontal garante disponibilidade e baixa latência no momento em que o tráfego muda. O dimensionamento vertical baseado no modelo garante que cada nó seja usado de forma eficiente, ajustando adequadamente a concorrência à medida que o comportamento do modelo evolui. Juntos, eles evitam a falsa escolha entre rápido-mas-desperdiçador e eficiente-mas-lento.
Limites de aumento (scale-up) e redução (scale-down) de escala
A fórmula bruta do HPA não é suficiente por si só: ela não é resiliente a picos repentinos de tráfego. Um breve pico de 10× calcula um aumento de 10× nas réplicas; uma breve queda de 95% calcula uma redução de 95%. Ambos são perigosos, seja pelo custo ou pela latência e disponibilidade.
O aumento de escala (scale-up) horizontal é agressivo Em produção, a alta latência pode significar um impacto comercial negativo massivo. Muitos casos de uso têm, naturalmente, padrões de tráfego com picos altamente instáveis que são críticos de suportar. Para lidar com picos, coletamos solicitações recebidas a cada 1 segundo e o APA toma uma decisão de aumento de escala a cada 5 segundos com base no tráfego dos últimos 20 segundos. Isso reduz significativamente as filas e os erros 429 durante os picos — muitos clientes notaram uma diferença de até 5x. Também limitamos o quanto podemos aumentar a escala em um único ciclo em relação à carga atual. No geral, podemos ir de 10 para 10 mil QPS em 60 segundos (dependendo do tempo de carregamento do modelo)
A redução de escala (scale-down) é conservadora. Um pico geralmente sinaliza a chegada de mais tráfego. Para a redução de escala, o APA ainda decide a cada 5 segundos, mas considera o tráfego dos últimos ~5 minutos antes de remover réplicas.
A assimetria é intencional. Os picos são repentinos; as quedas costumam ser temporárias. O custo de uma redução de escala prematura (um cold start no pior momento possível) supera o custo de manter algumas réplicas ociosas temporariamente.
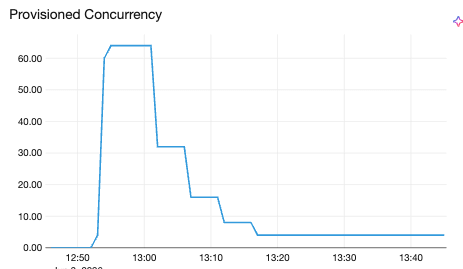
Aumento (scale-up) e redução (scale-down) de concorrência vertical. A mesma filosofia assimétrica se aplica ao dimensionamento vertical: agir rapidamente para reduzir a concorrência quando um pod apresenta estresse (direcionar menos solicitações para uma réplica já carregada protege a latência), mas nunca abaixo de um mínimo. Essas decisões ocorrem em um intervalo de 30 segundos, mais lento do que o loop horizontal de 5 segundos. Isso é intencional: o dimensionamento vertical é uma otimização de estado estável que se adapta ao perfil de recursos de um modelo ao longo do tempo, não uma reação em tempo real a picos.
Minimizando o tempo de inicialização a frio (cold start)
O cold start é o pior evento de latência em um sistema de serving; não há como otimizar para contorná-lo depois que ele já está acontecendo. Nós o atacamos em duas frentes: manter o máximo possível pré-aquecido e tornar as partes inevitáveis o mais rápidas possível.
Pools de nós aquecidos (warm node pools). Um algoritmo preditivo mantém um pool de nós pré-provisionados por cluster Databricks, pré-carregados com a imagem de runtime base. Quando o autoscaler adiciona uma réplica, ele escolhe a partir deste pool: o nó já está ativo, a imagem base já foi baixada e o único trabalho restante é baixar o modelo. Não cobramos dos clientes pela capacidade do pool aquecido; é um valor direto que eles obtêm do Databricks.
Download rápido de modelos. As imagens de contêiner do modelo são armazenadas em uma camada de cache ativo (hot cache) no armazenamento em nuvem e baixadas em blocos paralelos na inicialização do pod, reduzindo significativamente o tempo de download da imagem para contêineres de modelos grandes. As alterações de configuração que não afetam o modelo ou suas dependências (atualizações de metadados de endpoint, alterações de regras de roteamento) são aplicadas sem reiniciar o pod, já que evitar uma reinicialização é a melhor forma de manter o sistema aquecido.
Concorrência provisionada. Para endpoints críticos de latência que não podem tolerar nenhum cold start, os usuários configuram um limite mínimo de concorrência. Isso mantém uma linha de base de pods totalmente prontos com o modelo carregado e prontos para atender imediatamente, sem filas na primeira solicitação.
Atualizações e manutenção sem tempo de inatividade (zero-downtime). As atualizações e a manutenção ocorrem totalmente sem tempo de inatividade. Todos os pods com a nova versão do modelo ficam ativos e prontos antes que o tráfego seja transferido dos pods antigos.
O que aprendemos em produção
Os clientes observaram benefícios em todas as dimensões:
- Custo: temos clientes que obtiveram mais de 90% de economia de custos em comparação com suas cargas de trabalho DIY.
- Latência: a latência p99 e p50 melhorou em até 2x para muitos clientes.
- Escala: os clientes escalaram para mais de 100 mil QPS em produção com pouca ou nenhuma manutenção.
- Mantemos 99,99% de disponibilidade em produção.
O autoscaling de dois eixos se generaliza para todos os tipos de modelo. Não tínhamos certeza se a abordagem horizontal + vertical funcionaria para tudo, desde classificadores de CPU até LLMs de GPU. E funciona: o eixo horizontal lida com o tráfego da mesma forma para cada modelo, enquanto o eixo vertical se estabiliza em uma concorrência maior para modelos leves e menor para modelos pesados em GPU. Mesmo controlador, mesma lógica, o comportamento correto para cada um.
A maioria dos modelos é homogênea. Pensávamos que os limites de concorrência oscilariam constantemente com o tráfego; na prática, o perfil de recursos de um modelo sob a mesma carga permanece praticamente semelhante. O eixo vertical mostra seu valor durante a integração (onboarding) e depois se estabiliza.
Não é possível eliminar totalmente os cold starts por meio de otimização. Esperávamos que os pools aquecidos, os downloads paralelos de imagens e a reutilização de implantações reduzissem os cold starts a quase zero. Eles ajudam muito — mas a física tem um limite: inicializar um pod leva um tempo que cresce com o tamanho do modelo, chegando a minutos para grandes modelos de GPU. Além desse limite, a única resposta é manter uma capacidade mínima totalmente pronta, que é exatamente o motivo pelo qual a concorrência provisionada mínima existe.
O tráfego é mais previsível do que parece. O mínimo correto não é estático: os aplicativos B2C desaceleram durante a noite, os pipelines em lote (batch) são executados em horários programados. Esses padrões podem ser aprendidos, e estamos desenvolvendo previsões de tráfego para aumentar a concorrência mínima antes da demanda, em vez de correr atrás dela. Fique atento a isso.
Conclusão
Nosso objetivo era eliminar a taxa da pilha de ML (ML Stack Tax): o ajuste constante e a equipe de serving dedicada que ela exige. Para toda a diversidade de modelos em execução no Custom Model Serving hoje, o autoscaler de dois eixos, os pools aquecidos e as implantações sem tempo de inatividade fazem exatamente isso. A infraestrutura se adapta ao modelo, e não o contrário. Você traz um modelo, define um intervalo de concorrência e a plataforma cuida do resto.
No entanto, o serving de modelos não é um campo totalmente resolvido. Modelos maiores, novos hardwares e cargas de trabalho de agentes (agentic workloads) continuam a elevar a escala e a complexidade além do que a infraestrutura de serving tradicional foi projetada para suportar. Os problemas em aberto são reais e a ambição é alta: tempos de cold start menores, previsão de tráfego para dimensionamento preditivo, mais de 1 milhão de QPS por endpoint e mais de 10 milhões de QPS por cluster, agrupamento inteligente (bin-packing) de cargas de trabalho de GPU heterogêneas e redução do p99 para menos de 5 ms.
E este é um problema que a Databricks está em uma posição única para resolver. Adaptar a infraestrutura a um modelo significa conhecer o modelo: como ele foi treinado, do que ele depende e como se comporta sob carga. Na Databricks, tudo isso reside em uma única plataforma governada: dados e features, treinamento, empacotamento do MLflow, serving, agentes e a telemetria que os monitora. Uma camada de serving independente vê apenas um container; nós vemos todo o ciclo de vida. Esse contexto é o que permite que a plataforma se ajuste a cada modelo, e por que nenhum produto de serving complementar consegue eliminar a taxa da pilha de ML tão bem.
Se esse tipo de problema de infraestrutura interessa a você, estamos contratando.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.