AiChemy: Agente de Próxima Geração com MCP, Habilidades e Dados Personalizados para Descoberta de Medicamentos
AiChemy acelera a descoberta de medicamentos integrando dados personalizados e externos (OpenTargets, PubChem, PubMed) através de um sistema multiagente utilizando MCP, Skills, AI Search e Genie no Databricks
por Yen Low e Sean Zhang
- Um guia para construir AiChemy, um sistema multiagente no Databricks que integra bases de conhecimento externas (OpenTargets, PubChem, PubMed) via Model Context Protocol (MCP) com dados estruturados e não estruturados no Databricks.
- O desafio que ele resolve: Acelera a pesquisa de descoberta de medicamentos interdisciplinar, permitindo a colaboração autônoma entre diversos agentes de IA, permitindo que eles analisem conjuntos de dados massivos e díspares e forneçam descobertas rastreáveis e baseadas em evidências.
- Resultados: Pesquisadores podem identificar alvos de doenças, avaliar candidatos a medicamentos, recuperar propriedades detalhadas e realizar avaliações de segurança, levando a uma descoberta de medicamentos e geração de leads mais eficientes.
Sistemas multiagentes aceleram a pesquisa interdisciplinar
Imagine sistemas de IA multiagentes colaborando como uma equipe de especialistas interdisciplinares, vasculhando autonomamente enormes conjuntos de dados para descobrir padrões e hipóteses inovadoras. Isso agora é convenientemente alcançável com o Model Context Protocol (MCP), um novo padrão para integrar facilmente diversas fontes de dados e ferramentas. O crescente ecossistema de servidores MCP — de bases de conhecimento a geradores de relatórios — oferece capacidades infinitas.
O que o AiChemy faz
Conheça o AiChemy, um assistente multiagente que combina servidores MCP externos como OpenTargets, PubChem e PubMed com suas próprias bibliotecas químicas no Databricks, de modo que as bases de conhecimento combinadas possam ser melhor analisadas e interpretadas em conjunto. Ele também possui Skills que podem ser carregadas opcionalmente para fornecer instruções detalhadas para a produção de relatórios específicos para tarefas, formatados de forma consistente para necessidades de pesquisa, regulatórias ou de negócios.
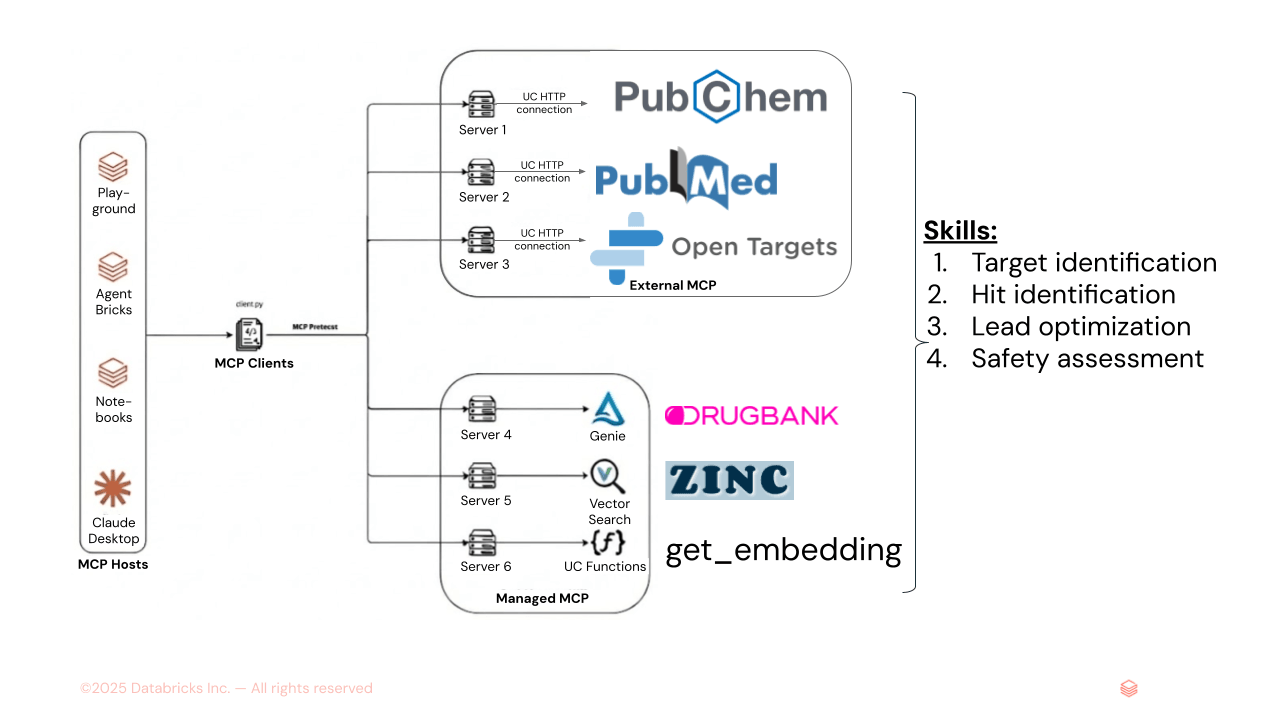
Figura 1. AiChemy é um supervisor multiagente que compreende servidores MCP externos PubChem, PubMed e OpenTargets, e servidores MCP gerenciados pelo Databricks do Genie Space (text-to-SQL para dados estruturados do DrugBank) e do AI Search (para dados não estruturados como embeddings moleculares ZINC). Skills também podem ser carregados para especificar a sequência de tarefas e a formatação e estilo do relatório para garantir resultados consistentes.
Suas principais capacidades incluem a identificação de alvos de doenças e candidatos a medicamentos, a recuperação de suas propriedades químicas e farmacocinéticas detalhadas, e a oferta de avaliações de segurança e toxicidade. Crucialmente, o AiChemy fundamenta suas descobertas com evidências de apoio rastreáveis a fontes de dados verificáveis, tornando-o ideal para pesquisa.
Caso de Uso 1: Entender mecanismos de doenças, encontrar alvos tratáveis e geração de leads
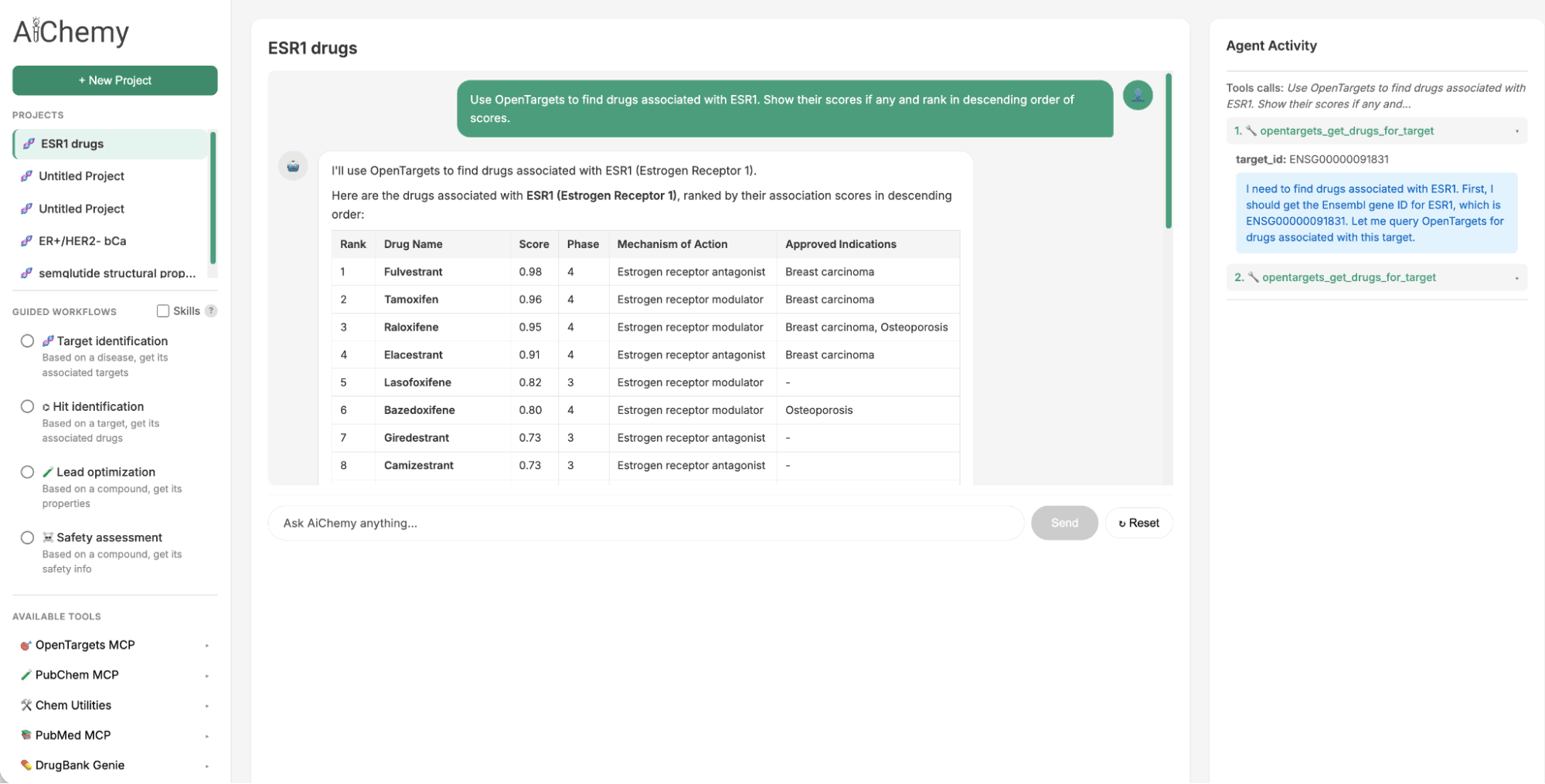
O painel Tarefas Guiadas fornece os prompts e Skills de agente necessários para executar as etapas-chave em um fluxo de trabalho de descoberta de medicamentos: doença -> alvo -> medicamento -> validação de literatura.
- Identificar Alvos Terapêuticos: Começando com um subtipo de doença específico, como câncer de mama com Receptor de Estrogênio positivo (ER+)/HER2-negativo (HER2-) (onde ER e HER2 s�ão biomarcadores proteicos chave), encontrar alvos terapêuticos associados (por exemplo, ESR1).
- Encontrar Medicamentos Associados: Usar o alvo identificado (por exemplo, ESR1) para encontrar potenciais candidatos a medicamentos.
- Validar com Literatura: Para um determinado candidato a medicamento (por exemplo, camizestrant), verificar a literatura científica em busca de evidências de apoio.
Caso de Uso 2: Geração de leads por similaridade química
Para identificar um sucessor para o Modulador Seletivo do Receptor de Estrogênio (SERM) oral aprovado em 2023, Elacestrant, podemos alavancar a similaridade química. Buscamos na grande biblioteca química ZINC15 por moléculas semelhantes a medicamentos (drug-like) estruturalmente ao Elacestrant, pois os princípios de Relação Quantitativa Estrutura-Atividade (QSAR) sugerem que elas compartilharão propriedades semelhantes. Isso é alcançado consultando o Databricks AI Search, que usa o embedding molecular Extended-Connectivity Fingerprint (ECFP) de 1024 bits do Elacestrant (como vetor de consulta) para encontrar os embeddings mais semelhantes dentro do índice de 250.000 moléculas do ZINC.
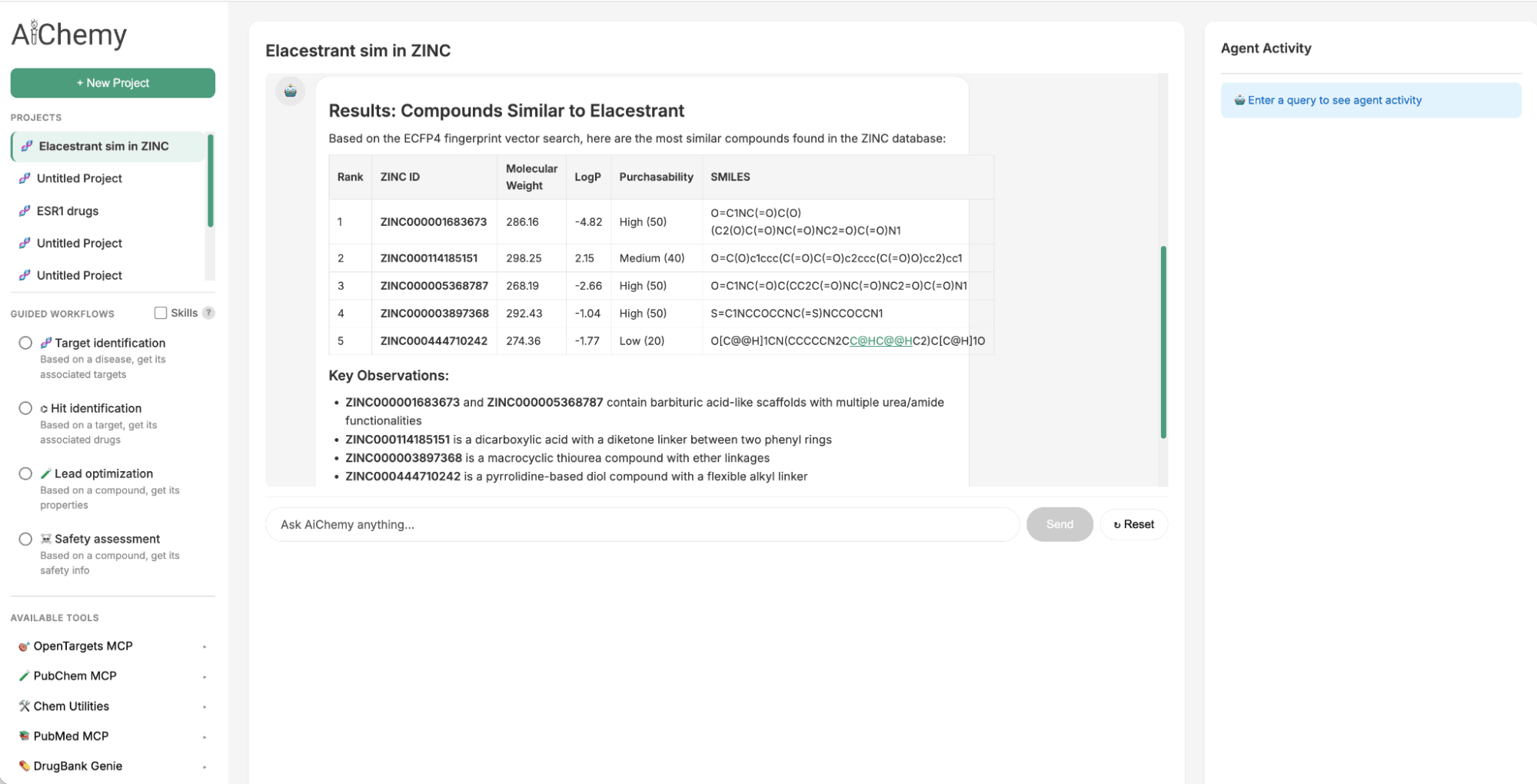
Figura 2. O AiChemy inclui a busca vetorial no banco de dados ZINC de 250.000 moléculas comercialmente disponíveis. Isso nos permite gerar compostos líderes por similaridade química. Nesta captura de tela, pedimos ao AiChemy para encontrar no AI Search do ZINC os compostos mais semelhantes ao Elacestrant com base no embedding molecular ECFP4.
Construa seu próprio supervisor multiagente de pesquisa
Personalizaremos um supervisor multiagente no Databricks integrando servidores MCP públicos com dados proprietários no Databricks. Para conseguir isso, você tem a opção de usar o Agent Bricks sem código ou opções de codificação como Notebooks. O Databricks Playground permite prototipagem e iteração rápidas de seus agentes.
Etapa 1: Preparar os componentes necessários para o supervisor multiagente
O sistema multiagente possui 5 workers:
- OpenTargets: servidor MCP externo de um grafo de conhecimento doença-alvo-medicamento
- PubMed: servidor MCP externo de literatura biomédica
- PubChem: servidor MCP externo de compostos químicos
- Biblioteca de Medicamentos (Genie): Uma biblioteca química com propriedades de medicamentos estruturadas, transformada em um espaço Genie para fornecer funcionalidades de text-to-SQL.
- Biblioteca Química (AI Search): Uma biblioteca proprietária de dados químicos não estruturados com embeddings de impressão digital molecular, preparada como um índice vetorial para facilitar a busca por similaridade por embeddings.
Etapa 1a: Conecte-se com segurança a servidores MCP públicos via conexões do Unity Catalog (UC) na UI ou em um Databricks Notebook (por exemplo, 4_connect_ext_mcp_opentarget.py).
Etapa 1b: Certifique-se de que sua(s) tabela(s) estruturada(s) (por exemplo, DrugBank) seja(m) transformada(s) em um espaço Genie com funcionalidade text-to-SQL usando a UI. Veja 1_load_drugbank and descriptors.py
Etapa 1c: Certifique-se de que sua biblioteca química não estruturada seja criada como um índice vetorial na UI ou em um Notebook para habilitar a busca por similaridade. Veja 2_create VS zinc15.py
Etapa 2 (Opção Fácil): Construa o supervisor multiagente usando o Supervisor Agent sem código em 2 minutos
Para montá-los, experimente o Agent Bricks sem código, que constrói um agente supervisor com os componentes acima pela interface do usuário e o implanta em um endpoint de API REST, tudo em poucos minutos.
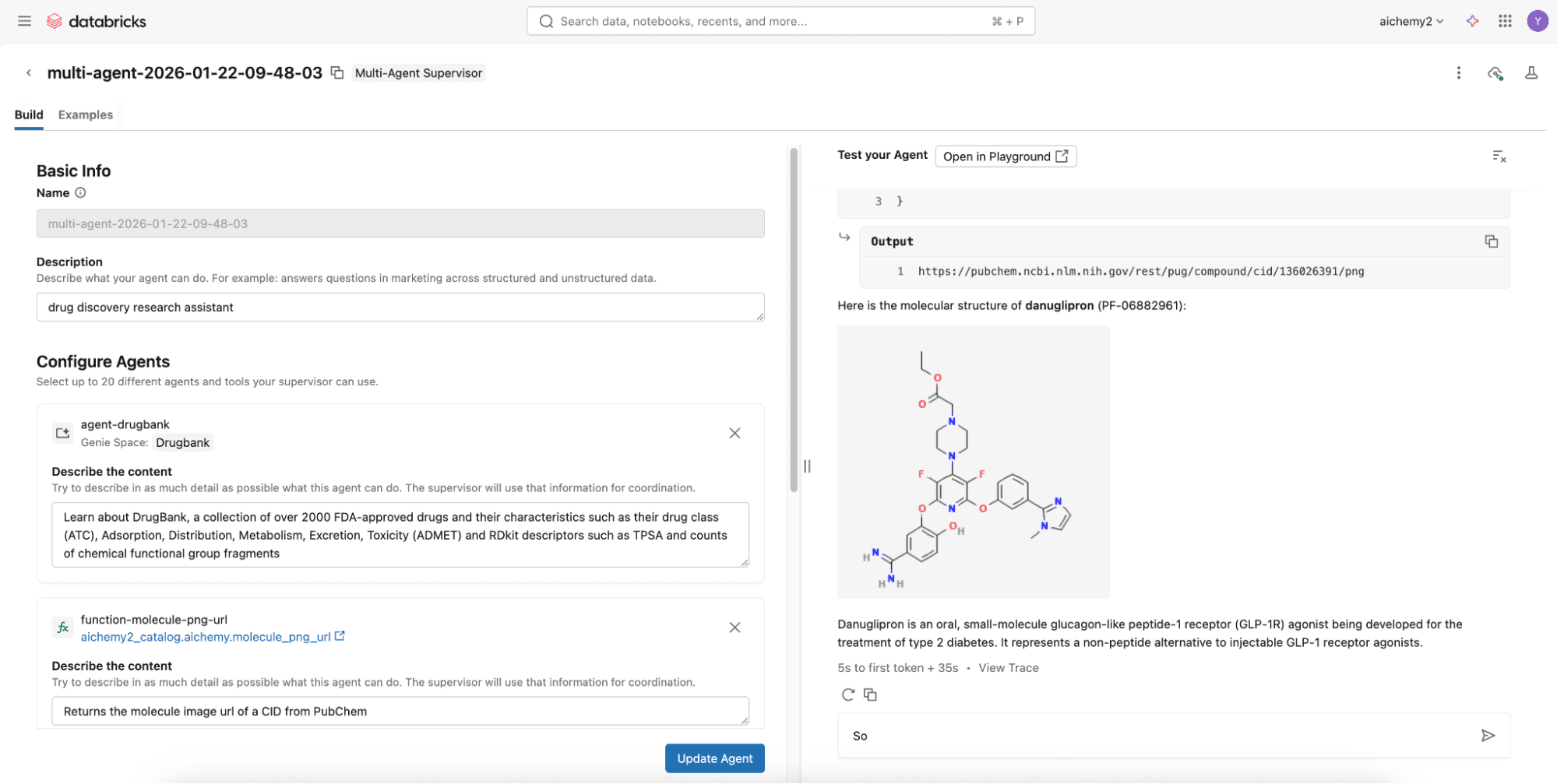
Etapa 2 (Opção Avançada): Construa o supervisor multiagente usando Databricks Notebooks
Para recursos mais avançados, como memória agentiva e Skills, desenvolva um supervisor Langgraph no Databricks Notebooks para integrar com Lakebase, o banco de dados Postgres Serverless da Databricks. Confira este repositório de código onde você pode simplesmente definir os componentes multiagente (veja a Etapa 1) no config.yml.
Após definir o config.yml, você pode implantar o supervisor multiagente como um MLflow AgentServer (wrapper FastAPI) com uma interface de usuário web React (UI). Implante ambos no Databricks Apps via UI ou Databricks CLI. Defina as permissões apropriadas para que os usuários usem o Databricks App e para que o principal de serviço do aplicativo acesse os recursos subjacentes (por exemplo, experimento para registrar traces, escopo secreto, se houver).
Etapa 3: Avalie e monitore seu agente
Cada invocação ao agente é registrada automaticamente e rastreada para um experimento MLflow da Databricks usando padrões OpenTelemetry. Isso permite a fácil avaliação das respostas offline ou online para melhorar o agente ao longo do tempo. Além disso, seu agente multiagente implantado usa o LLM por trás do AI Gateway para que você possa aproveitar os benefícios de governança centralizada, salvaguardas integradas e observabilidade completa para prontidão de produção.
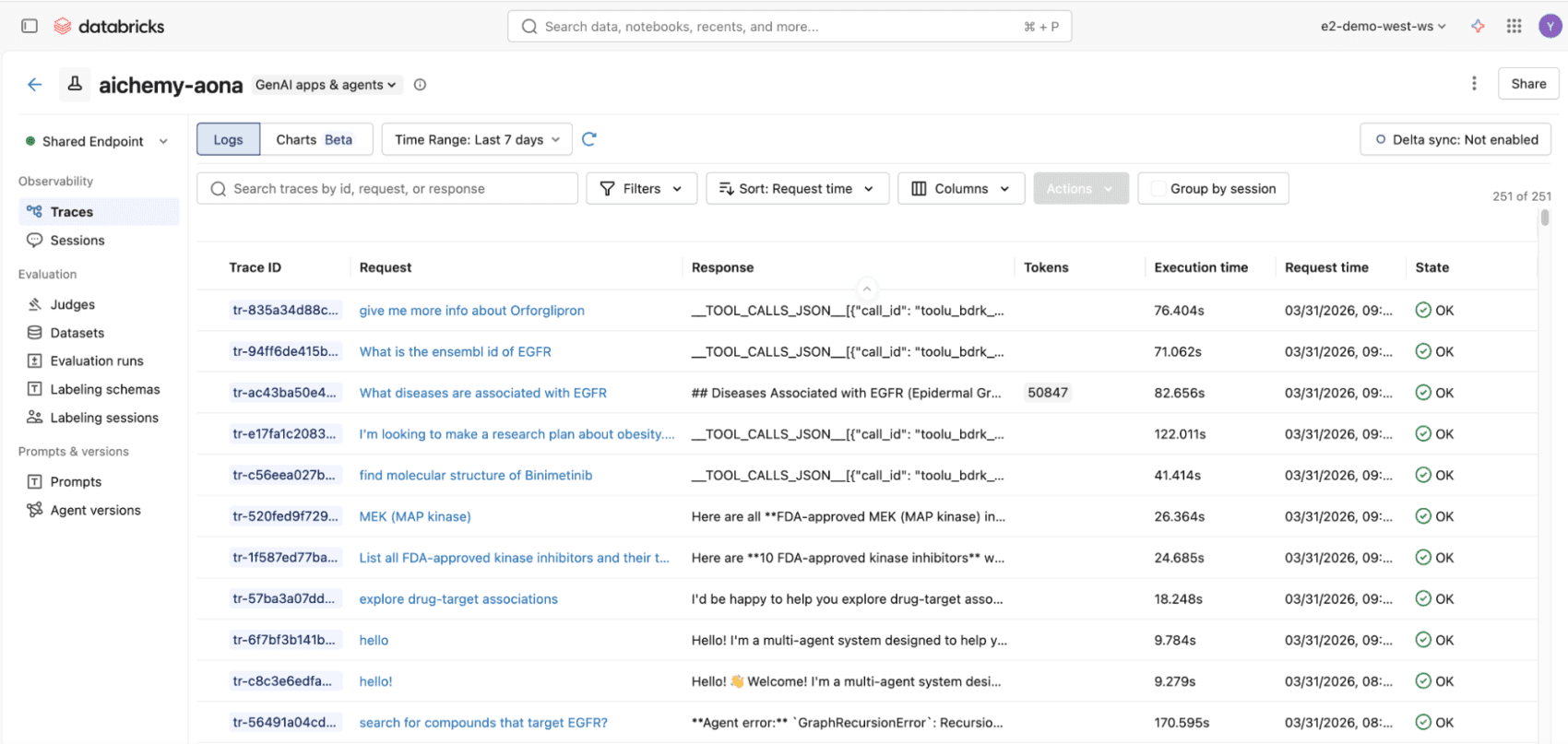
Figura 3. Todas as invocações ao agente multiagente, seja via UI React ou API REST, serão registradas em MLflow traces, em conformidade com os padrões OpenTelemetry, para observabilidade de ponta a ponta.
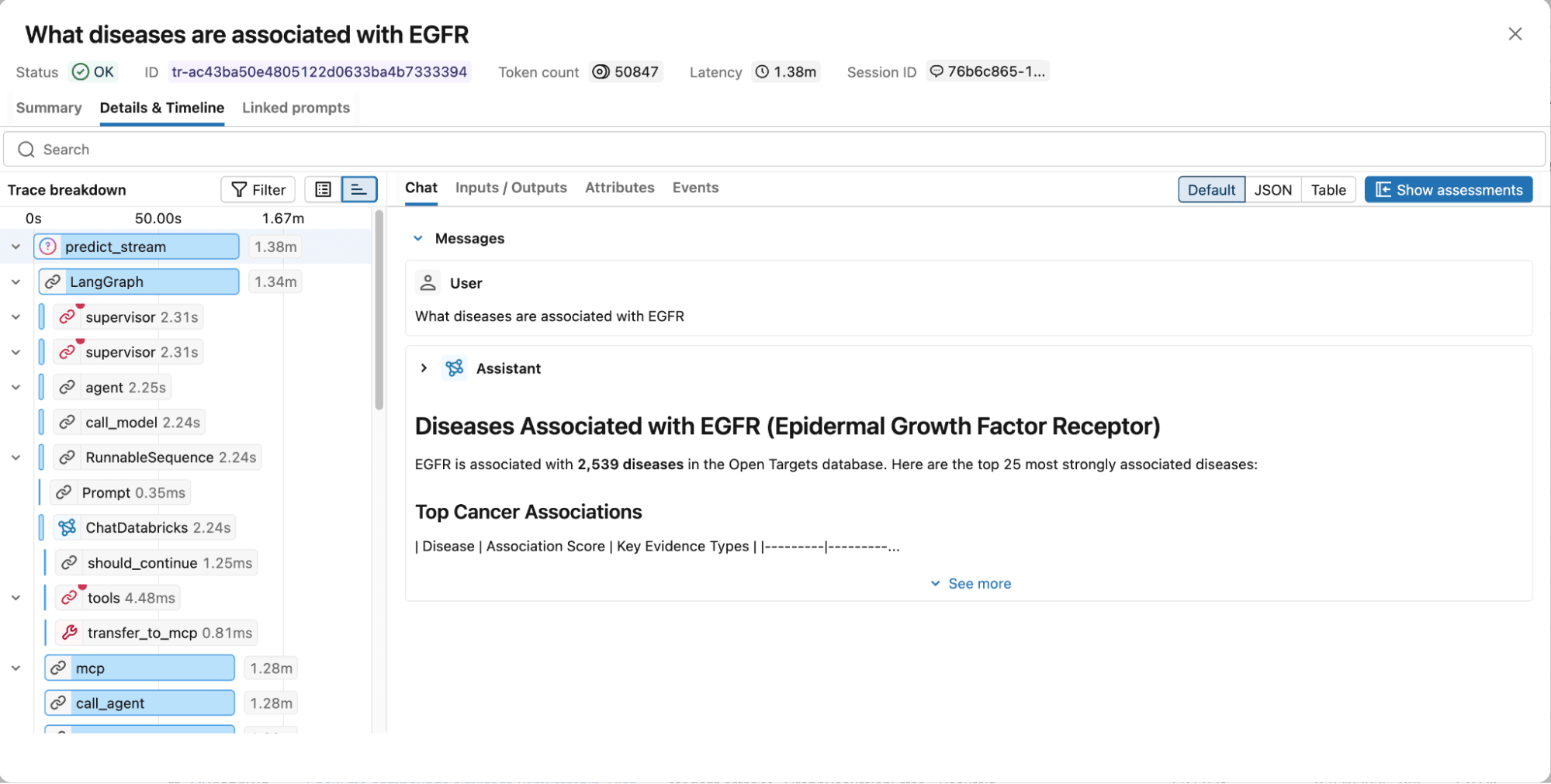
Figura 4. MLflow traces capturam o grafo de execução completo, incluindo etapas de raciocínio, chamadas de ferramentas, documentos recuperados, latência e uso de tokens para facilitar a depuração e otimização.
Próximas etapas
Convidamos você a explorar o aplicativo web AiChemy e o repositório Github. Comece a construir seu sistema multiagente personalizado com o framework intuitivo e sem código Agent Bricks no Databricks para que você possa parar de vasculhar e começar a descobrir!

(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.