Anunciando DBRX: Um novo padrão para LLMs de código aberto eficientes
Construa aplicações de IA generativa de alta qualidade com o DBRX personalizado para seus dados únicos
por Jonathan Frankle, Ali Ghodsi, Naveen Rao, Hanlin Tang, Abhinav Venigalla e Matei Zaharia
A missão da Databricks é fornecer inteligência de dados a todas as empresas, permitindo que as organizações entendam e usem seus dados exclusivos para criar seus próprios sistemas de IA. Hoje, estamos entusiasmados em avançar em nossa missão com o código aberto DBRX, um modelo de Large Language Model (LLM) criado por nossa equipe da Databricks AI Research que supera todos os modelos de código aberto estabelecidos em benchmarks padrão. Acreditamos que ultrapassar os limites dos modelos de código aberto permite que a IA Generativa seja personalizável e transparente para todas as empresas.
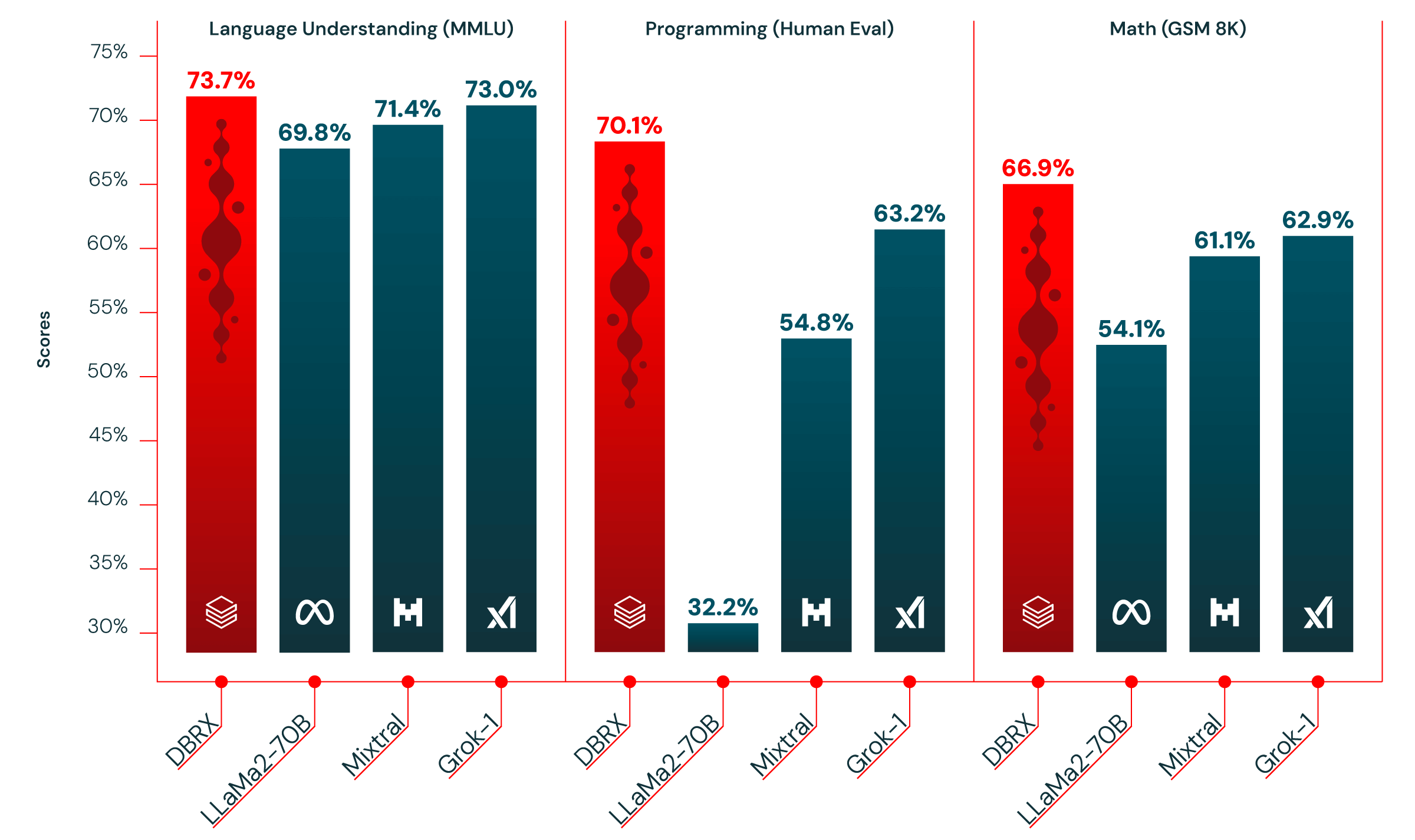
Estamos entusiasmados com a DBRX por três motivos distintos. Em primeiro lugar, ele supera com folga os modelos de código aberto, como LLaMA2-70B, Mixtral e Grok-1, em compreensão de linguagem, programação, matemática e lógica (consulte a Figura 1). De fato, nosso benchmark de código aberto Gauntlet contém mais de 30 benchmarks distintos de última geração (SOTA) e o DBRX supera todos esses modelos. Isso mostra que os modelos de código aberto continuam a melhorar a qualidade, uma tendência da qual nos orgulhamos de fazer parte.
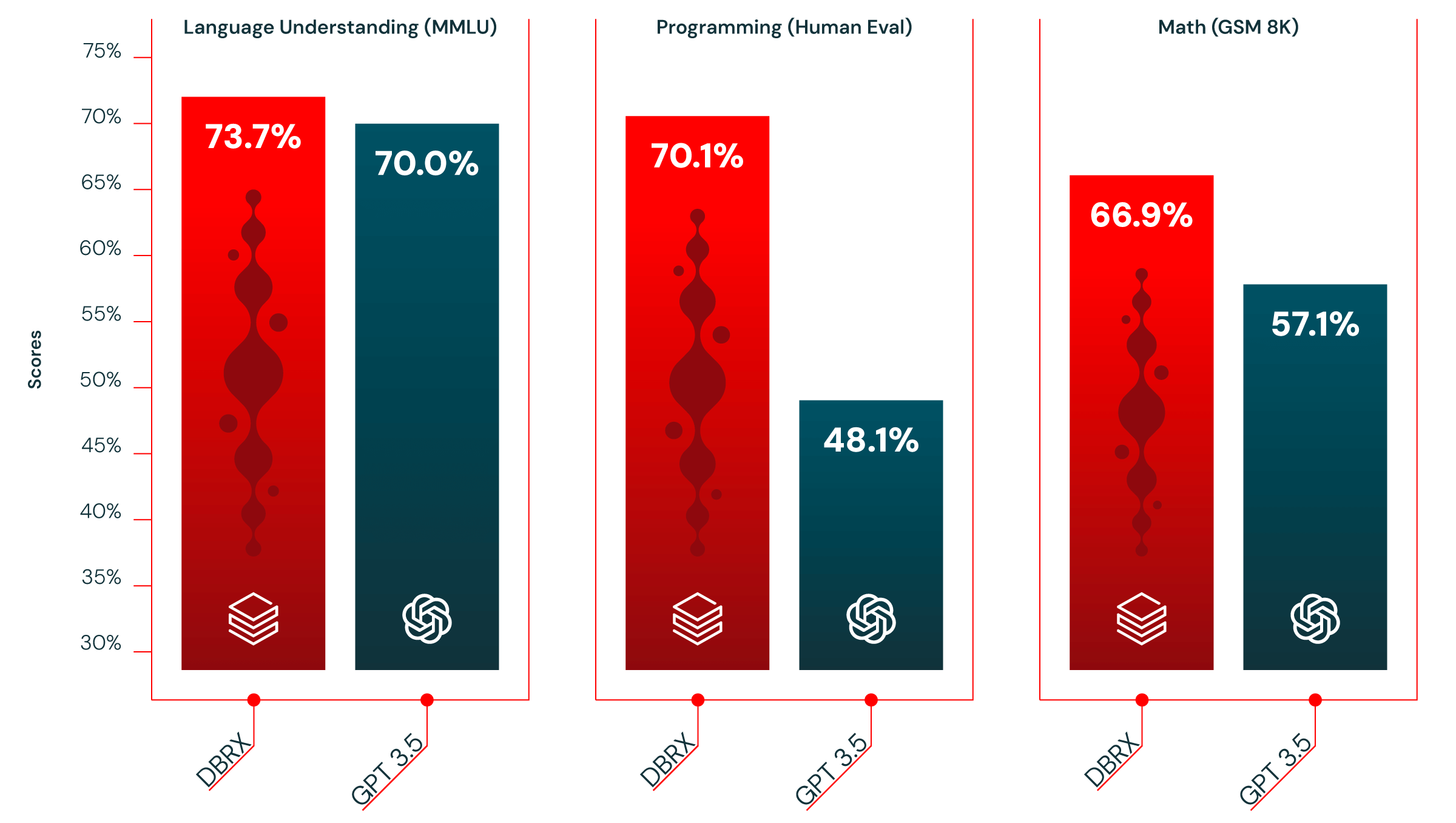
Em segundo lugar, o DBRX supera o GPT-3.5 na maioria dos benchmarks (consulte a Figura 2). Isso é importante, pois observamos uma grande mudança de comportamento no último trimestre em nossa base de mais de 12.000 clientes. As empresas e organizações estão cada vez mais substituindo os modelos proprietários por modelos de código aberto para obter maior eficiência e controle. Em nossa experiência, muitos clientes podem superar a qualidade e a velocidade dos modelos proprietários personalizando modelos de código aberto em sua tarefa específica. Esperamos que a DBRX acelere ainda mais essa tendência.
Em terceiro lugar, o DBRX é um modelo MoE (Mixture-of-Experts, mistura de especialistas) criado com base no projeto de pesquisa e código aberto MegaBlocks, o que torna o modelo extremamente rápido em termos de tokens/segundo. Acreditamos que isso abrirá o caminho para que os modelos de código aberto de última geração sejam MoEs no futuro. Isso é significativo porque os MoEs permitem que você ensine modelos maiores e os atenda com mais rapidez. O DBRX usa apenas 36 bilhões de parâmetros em um determinado momento. Mas o modelo em si tem 132 bilhões de parâmetros, permitindo que você tenha o bolo e o coma também em termos de velocidade (tokens/segundo) versus desempenho (qualidade).

Os três motivos mencionados acima nos levam a acreditar que os LLMs de código aberto continuarão ganhando força. Em particular, acreditamos que eles oferecem uma excelente oportunidade para as organizações personalizarem LLMs de código aberto que podem se tornar seu IP, que elas usam para serem competitivas em seus setores.
Para isso, projetamos o DBRX para ser facilmente personalizável, de modo que as empresas possam melhorar a qualidade de seus aplicativos de IA. A partir de hoje, na plataforma Databricks, as empresas podem interagir com o DBRX, aproveitar seus recursos de contexto longo em sistemas RAG e criar modelos DBRX personalizados em seus próprios dados privados. Esses recursos de personalização são alimentados pela plataforma de treinamento do MoE mais eficiente disponível comercialmente. A comunidade pode acessar o DBRX por meio do nosso repositório github e do Hugging Face.
Criamos o DBRX totalmente com base na Databricks, para que todas as empresas possam usar as mesmas ferramentas e técnicas para criar ou aprimorar seus próprios modelos de alta qualidade. Os dados de treinamento foram gerenciados de forma centralizada em Unity Catalog, processados e limpos com o Apache Spark™ e o recém-adquirido Lilac IA. O treinamento e o ajuste fino do modelo de grande escala usaram nosso serviço de treinamento Databricks. O feedback humano sobre qualidade e segurança foi coletado por meio do Databricks Model Serving e de tabelas de inferência. Clientes e parceiros, como JetBlue, Block, NASDAQ e Accenture, já estão usando essas mesmas ferramentas para criar sistemas de IA de alta qualidade.
Databricks é um dos principais parceiros da NASDAQ em alguns de nossos sistemas de dados mais importantes. Eles continuam na vanguarda das indústrias no gerenciamento de dados e no aproveitamento da AI, e estamos entusiasmados com o lançamento do DBRX. A combinação de um forte desempenho do modelo e uma economia de serviço favorável é o tipo de inovação que estamos buscando à medida que aumentamos nosso uso de IA generativa na Nasdaq", disse Mike O'Rourke, diretor de IA e serviços de dados da NASDAQ.
A Databricks é a única plataforma completa para criar aplicativos de IA de alta qualidade, e o lançamento de hoje do DBRX, o modelo de código aberto da mais alta qualidade até o momento, é uma expressão dessa capacidade. Estamos animados para saber o que a comunidade de código aberto e nossos clientes corporativos podem fazer com o DBRX.
Para saber mais, leia nossos blogs técnicos, acesse o modelo, join nosso DBRX webinar, e leia nossa documentação (AWS | Azure) sobre como começar a usar o DBRX em Databricks.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.