Anúncio da Disponibilidade Geral do Modo de Tempo Real para Apache Spark Structured Streaming no Databricks
Potencialize suas cargas de trabalho mais críticas em termos de tempo, desde a detecção de fraudes até a personalização, com latência inferior a um segundo
- Latência abaixo de um segundo no Spark: O Modo em Tempo Real (RTM) no Apache Spark Structured Streaming está agora em Disponibilidade Geral, trazendo desempenho de milissegundos de ponta a ponta para APIs familiares do Spark e eliminando a necessidade de outro motor especializado, como o Apache Flink.
- Inovação arquitetônica: O RTM atinge velocidades de processamento abaixo de 100ms por meio de três inovações: fluxo de dados contínuo, agendamento de pipeline e shuffle de streaming.
- Comprovado em escala: Líderes da indústria como Coinbase, DraftKings e MakeMyTrip estão usando o RTM para potencializar casos de uso operacionais de missão crítica, com alguns alcançando uma redução de latência de mais de 80%.
Por anos, o Apache Spark Structured Streaming tem impulsionado algumas das cargas de trabalho de streaming mais exigentes do mundo. No entanto, para casos de uso de latência ultrabaixa, as equipes precisavam manter motores separados e especializados — mais comumente o Apache Flink, ao lado do Spark, duplicando bases de código, modelos de governança e sobrecarga operacional. Agora, a Databricks remove esse fardo para os clientes.
Hoje, estamos entusiasmados em anunciar a Disponibilidade Geral do Modo em Tempo Real (RTM) no Spark Structured Streaming, trazendo latência de milissegundos para as APIs do Spark que você já usa. Seja detectando fraudes em tempo real ou gerando contexto fresco em tempo real para direcionar seus agentes de IA, você agora pode usar o Spark para impulsionar todos esses casos de uso.
Impulsionando clientes e casos de uso líderes do setor
O RTM já foi adotado por equipes em organizações líderes do setor em serviços financeiros, e-commerce, mídia e ad tech para impulsionar detecção de fraudes, personalização ao vivo, computação de features de ML e atribuição de anúncios.
A Coinbase, uma das principais exchanges de criptomoedas do mundo, usa o RTM para escalar seus motores de gerenciamento de risco e detecção de fraudes de alta frequência — processando volumes massivos de eventos de blockchain e de exchange com a latência sub-100ms necessária para proteger milhões de transações de ativos digitais.
Ao alavancar o Modo em Tempo Real no Spark Structured Streaming, alcançamos uma redução de mais de 80% nas latências de ponta a ponta, atingindo P99s sub-100ms e otimizando nossa estratégia de ML em tempo real em escala massiva. Esse desempenho nos permite computar mais de 250 features de ML, todos impulsionados por um motor Spark unificado.”—Daniel Zhou, Engenheiro Sênior de Plataforma de Machine Learning, Coinbase
A DraftKings, uma das maiores plataformas de sportsbook e fantasy sports da América do Norte, usa o modo em tempo real para impulsionar a computação de features para seus modelos de detecção de fraudes — processando streams de eventos de apostas de alto volume com a latência e confiabilidade necessárias para decisões de apostas com dinheiro real.
Em apostas esportivas ao vivo, a detecção de fraudes exige velocidade extrema. A introdução do Modo em Tempo Real, juntamente com a API transformWithState no Spark Structured Streaming, foi um divisor de águas para nós. Alcançamos melhorias substanciais tanto em latência quanto em design de pipeline e, pela primeira vez, construímos pipelines de features unificados para treinamento de ML e inferência online, alcançando latências ultrabaixas que simplesmente não eram possíveis antes.”—Maria Marinova, Engenheira de Software Líder Sênior, DraftKings
A MakeMyTrip, uma das principais plataformas de viagens online da Índia para hotéis, voos e experiências, adotou o Modo em Tempo Real para impulsionar experiências de busca personalizadas. O RTM processou buscas de viajantes de alto volume para entregar recomendações em tempo real.
Em buscas de viagens, cada milissegundo conta. Ao alavancar o Modo em Tempo Real do Spark (RTM), entregamos experiências personalizadas com latências P50 sub-50ms, impulsionando um aumento de 7% nas taxas de cliques. O RTM também transformou nossas operações de dados, permitindo uma arquitetura unificada onde o Spark lida com tudo, desde ETL de alto volume até pipelines de latência ultrabaixa. À medida que avançamos para a era dos agentes de IA, direcioná-los efetivamente requer a construção de contexto em tempo real a partir de fluxos de dados. Estamos experimentando o RTM do Spark para fornecer aos nossos agentes o contexto mais rico e recente necessário para tomar as melhores decisões possíveis. —Aditya Kumar, Diretor Associado de Engenharia, MakeMyTrip
O RTM pode suportar qualquer carga de trabalho que se beneficie de transformar dados em decisões em milissegundos. Alguns exemplos de casos de uso incluem:
- Experiências personalizadas em varejo e mídia: Um provedor de streaming OTT atualiza recomendações de conteúdo imediatamente após um usuário terminar de assistir a um programa. Uma plataforma líder de e-commerce recalcula ofertas de produtos enquanto os clientes navegam — mantendo o engajamento alto com loops de feedback sub-segundo.
- Monitoramento de IoT: Uma empresa de transporte e logística ingere telemetria ao vivo para impulsionar a detecção de anomalias, passando de tomada de decisão reativa para proativa em milissegundos.
- Detecção de fraudes: Um banco global processa transações de cartão de crédito do Kafka em tempo real e sinaliza atividades suspeitas, tudo dentro de 200 milissegundos — reduzindo o risco e o tempo de resposta sem replataformar.
O que é o Modo em Tempo Real (RTM)?
O RTM é uma evolução do motor Spark Structured Streaming que permite atingir desempenho sub-segundo em benchmarks de cargas de trabalho exigentes de engenharia de features de clientes.
O modo de microbatch padrão (MBM) do Structured Streaming é como um ônibus de transporte de aeroporto que espera um certo número de passageiros embarcar antes de partir. Por outro lado, o RTM opera como uma esteira rolante de alta velocidade, eliminando a limitação de esperar o ônibus encher. O RTM processa cada evento à medida que chega, fornecendo latência de milissegundos de ponta a ponta sem sair do ecossistema Spark.
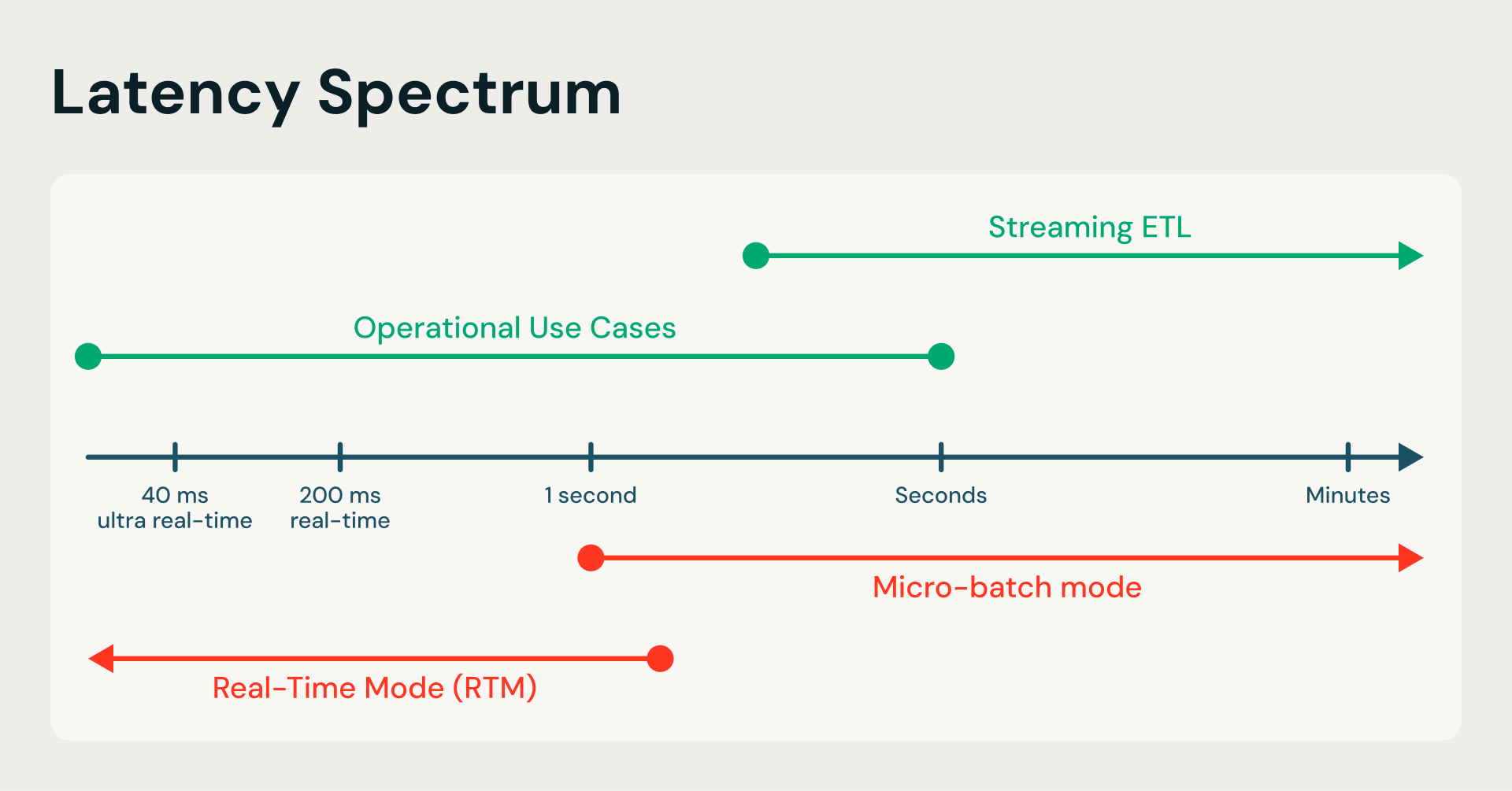
De segundos para milissegundos: O RTM transforma o motor Spark substituindo o batching periódico por um fluxo contínuo de dados, eliminando os gargalos de latência do ETL tradicional.
Os ganhos de desempenho do RTM vêm de três inovações arquitetônicas chave:
- Fluxo contínuo de dados: Os dados são processados à medida que chegam, em vez de em blocos discretos e periódicos.
- Agendamento de pipeline: Estágios são executados simultaneamente sem bloqueio, permitindo que tarefas downstream processem dados imediatamente sem esperar que os estágios upstream terminem.
- Shuffle de streaming: Os dados são passados entre tarefas imediatamente, contornando os gargalos de latência dos shuffles tradicionais baseados em disco.
Juntos, eles transformam o Spark em um motor de alto desempenho e baixa latência capaz de lidar com os casos de uso operacionais mais exigentes.
Spark RTM: Até 92% mais rápido que o Flink, permitindo que equipes operem menos infraestrutura e se movam mais rápido
Para validar o desempenho do Spark RTM, comparamos o desempenho com um motor especializado popular, o Apache Flink, com base em cargas de trabalho reais de clientes realizando computação de features. Esses padrões de computação de features são representativos da maioria dos casos de uso de ETL de baixa latência, como detecção de fraudes, personalização e análises operacionais. Ao comparar o Spark RTM com o Flink, os resultados demonstram que a arquitetura evoluída do Spark fornece um perfil de latência comparável a frameworks de streaming especializados. Para mais informações sobre os conjuntos de dados e consultas referenciados, veja este repositório GitHub.
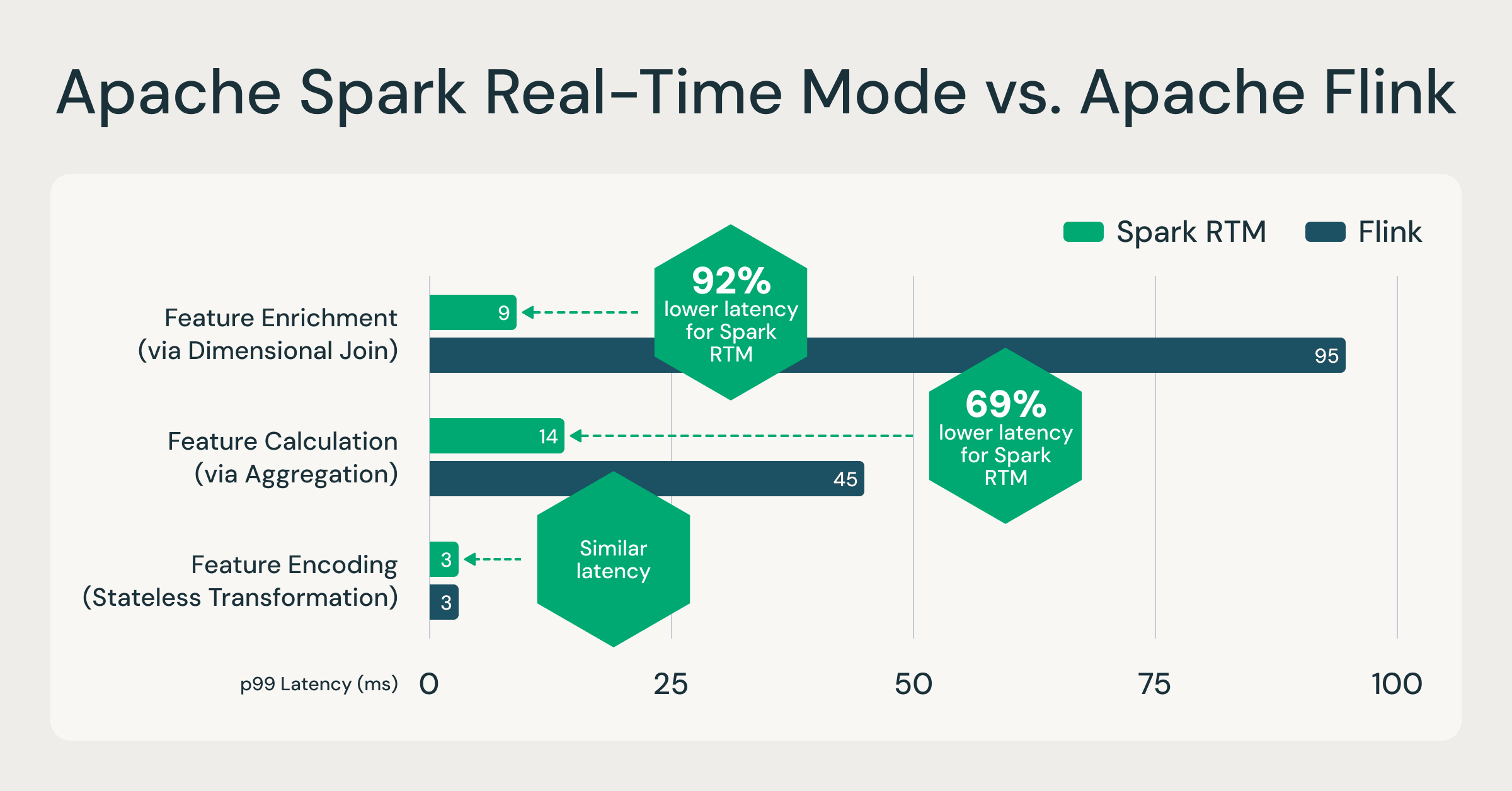
Um motor, até 92% mais rápido: O RTM supera motores especializados como o Flink, provando que análises operacionais em nível de milissegundo não exigem mais um motor de streaming separado. Fonte: Benchmarks internos baseados em padrões de computação de features de clientes. Consultas completas disponíveis no GitHub.
Embora a velocidade bruta importe, a maior vantagem do Spark RTM sobre motores como o Flink é a simplicidade que ele oferece aos desenvolvedores. Ele permite que as equipes usem a mesma API do Spark tanto para treinamento em batch quanto para inferência em tempo real, eliminando efetivamente o "desvio de lógica" e a duplicação de código. O Spark RTM permite escalabilidade contínua, onde uma única linha de código pode mudar um pipeline de batches horários para streaming sub-segundo sem ajuste manual de infraestrutura. Em última análise, ao reduzir a complexidade operacional e a necessidade de múltiplos sistemas especializados, as equipes podem desenvolver e implantar aplicações em tempo real significativamente mais rápido com o Spark RTM.
Começando com o Spark RTM
Começar a usar o RTM é simples. Se você já usa o Structured Streaming, pode habilitá-lo com uma única atualização de configuração — sem reescritas necessárias.
Etapa 1: Configure seu cluster
O RTM está atualmente disponível em computação Clássica, em ambos os modos de acesso Dedicado e Padrão. O RTM é suportado no Databricks Runtime (DBR) 16.4 e superior; no entanto, recomendamos o DBR 18.1 para os recursos e otimizações mais recentes. Durante a criação do cluster, adicione a seguinte configuração do Spark:
Etapa 2: Use o novo Real-Time Trigger em sua consulta de streaming
Novidades no Spark RTM
Desde o lançamento em Preview Público em agosto de 2025, a Databricks continuou a expandir os recursos do RTM, com base no feedback dos clientes.
Veja as novidades desta versão GA:
- Suporte a OSS em Apache Spark 4.1 (transformações stateless): O RTM para transformações stateless agora está disponível no Apache Spark 4.1 de código aberto. Equipes que desenvolvem em OSS Spark podem aproveitar o modo em tempo real para pipelines de projeção, filtragem e baseados em UDF.
- Suporte ao modo de acesso padrão: O RTM agora funciona nos modos de acesso dedicado e padrão em computação clássica em Python, oferecendo mais flexibilidade para as equipes utilizarem recursos de computação em cargas de trabalho de streaming.
- Checkpoint e acompanhamento de progresso de estado assíncronos: O checkpoint de estado e progresso da consulta agora são realizados de forma assíncrona, desvinculados do caminho crítico de processamento de eventos. Isso melhora a latência do modo em tempo real para pipelines stateless e stateful.
- Carregamento inicial de estado em transformWithState: transformWithState é um poderoso operador do Spark Structured Streaming para construir lógica stateful personalizada. Os usuários agora podem carregar o estado inicial do checkpoint de uma consulta pré-existente ou de uma delta table ao usar transformWithState com o Modo em Tempo Real. Essa capacidade é fundamental para engenharia de features stateful, permitindo pré-popular consultas online com contexto histórico sem "começar do zero".
- Métricas e observabilidade aprimoradas para UDFs: Métricas de latência mais precisas para execução de UDFs em Python, expostas através do listener StreamingQueryProgress.
- Melhorias de performance para UDFs Stateful em Python: Adicionadas otimizações para melhorar a performance de operações stateful em transformWithState em Python, especificamente para consultas RTM.
Conclusão
O RTM estende o Apache Spark Structured Streaming para uma nova classe de cargas de trabalho — aplicações operacionais sensíveis à latência que exigem resposta imediata a dados de streaming. Ao trazer latência de subsegundo para as APIs do Spark que sua equipe já utiliza, ele elimina a necessidade de operar um motor especializado separado para seus pipelines mais críticos em termos de tempo. Seja construindo pipelines de detecção de fraude, motores de personalização ou sistemas de computação de features de ML, o modo em tempo real oferece a latência que sua aplicação exige com a simplicidade e a amplitude do ecossistema do Spark.
Recursos Técnicos
Confira os seguintes recursos para começar com o RTM hoje:
- Documentação: Modo em tempo real no Structured Streaming
- Vídeo sob demanda: Primeiros passos com o Modo em Tempo Real
- Blog: Como Realizar Detecção de Fraude em Tempo Real: Configurando o Spark RTM com Databricks Lakebase
- Exemplos de código: Exemplos do modo em tempo real
- Webinar sob demanda: Deep Dive Técnico do Modo em Tempo Real
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.