Apresentando o Modo em Tempo Real no Apache Spark™ Structured Streaming
Processe eventos em milissegundos usando o novo Gatilho em Tempo Real do Spark
por Jerry Peng, Siying Dong, Abhay Bothra, Fatih Emekci, Karthikeyan Ramasamy, Navneeth Nair, Indrajit Roy, Matt Jones, Craig Lukasik e Ryan Nienhuis
- Processamento de streaming em milissegundos: Spark Structured Streaming introduz o modo em tempo real para processar dados em milissegundos, habilitando uma nova classe de apps de baixa latência.
- Sem reescritas necessárias: As equipes podem ativar o modo em tempo real com uma simples alteração de configuração — sem necessidade de replataforma ou reformulação de código.
- Agora em Public Preview: Disponível no Databricks com suporte para fontes e sinks populares; ideal para detecção de fraudes, personalização ao vivo e serviço de features de ML.
O Apache Spark™ Structured Streaming há muito tempo impulsiona pipelines críticos em escala, desde ETL de streaming até análises quase em tempo real e machine learning. Agora, estamos expandindo essa capacidade para uma classe totalmente nova de cargas de trabalho com o modo em tempo real, um novo tipo de gatilho que processa eventos à medida que chegam, com latência na casa dos dezenas de milissegundos.
Diferente dos gatilhos de micro-lotes existentes, que processam dados em um cronograma fixo (gatilho ProcessingTime) ou processam todos os dados disponíveis antes de desligar (gatilho AvailableNow), o modo em tempo real processa continuamente os dados e emite resultados assim que estão prontos. Isso permite casos de uso de latência ultrabaixa, como detecção de fraudes, personalização ao vivo e serviço de features de machine learning em tempo real, tudo sem alterar seu código existente ou replataformar.
Este novo modo está sendo contribuído para o Apache Spark de código aberto e agora está disponível em Public Preview no Databricks.
Neste post, abordaremos:
- O que é o modo em tempo real e como ele funciona
- Os tipos de aplicações que ele habilita
- Como você pode começar a usá-lo hoje
O que é o modo em tempo real?
O modo em tempo real oferece processamento contínuo e de baixa latência no Spark Structured Streaming, com latências p99 tão baixas quanto milissegundos de um dígito. As equipes podem ativá-lo com uma única alteração de configuração — sem reescritas ou replataformas necessárias — enquanto mantêm as mesmas APIs do Structured Streaming que usam hoje.
Como funciona o modo em tempo real
O modo em tempo real executa jobs de streaming de longa duração que agendam stages de forma concorrente. Os dados passam entre as tarefas na memória usando um shuffle de streaming, que:
- Reduz a sobrecarga de coordenação
- Remove os atrasos fixos de agendamento do modo de micro-lotes
- Oferece desempenho consistente abaixo de um segundo
Em testes internos do Databricks, as latências p99 variaram de alguns milissegundos a ~300 ms, dependendo da complexidade da transformação:
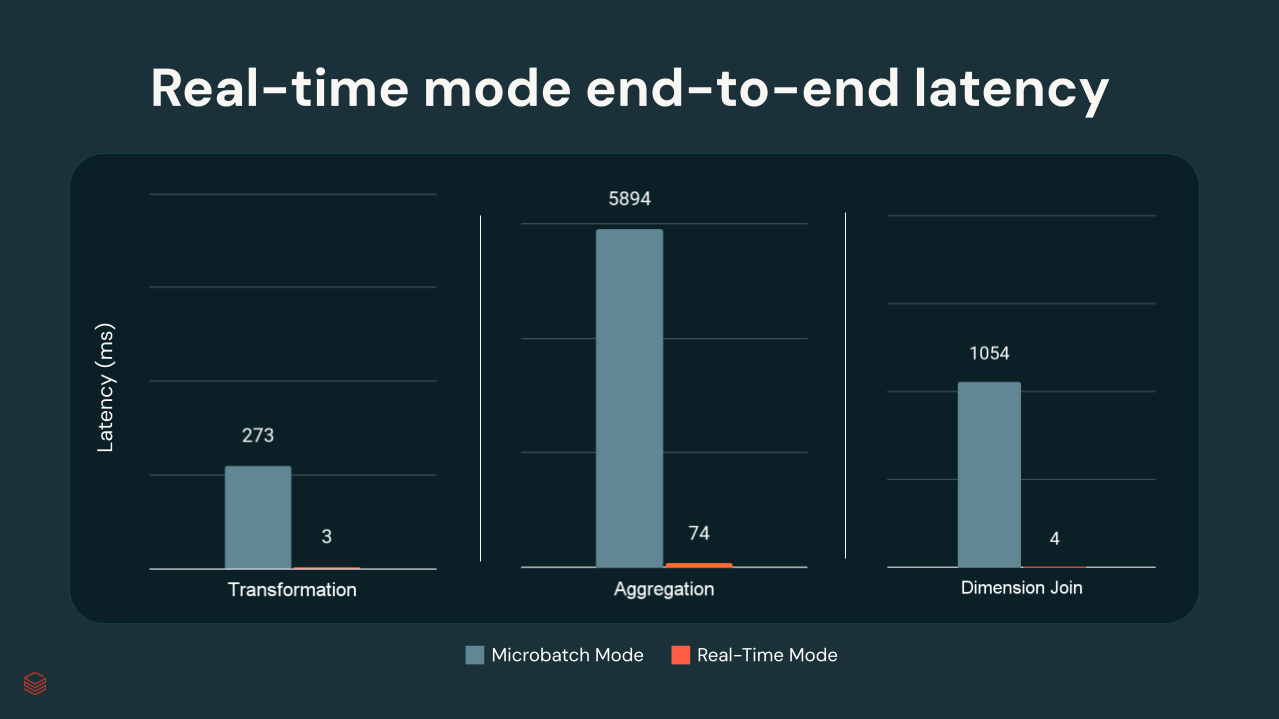
{kind=link}
Aplicações e Casos de Uso
O modo em tempo real foi projetado para aplicações de streaming que exigem processamento de latência ultrabaixa e tempos de resposta rápidos, muitas vezes no caminho crítico das operações de negócios.
O Modo em Tempo Real no Spark Structured Streaming entregou resultados notáveis em nossos testes iniciais. Para um pipeline de autorização de pagamentos crítico, onde realizamos criptografia e outras transformações, alcançamos latência ponta a ponta P99 de apenas 15 milissegundos. Estamos otimistas quanto à escalabilidade desse processamento de baixa latência em nossos fluxos de dados, atendendo consistentemente a SLAs rigorosos. —Raja Kanchumarthi, Lead Data Engineer, Network International

Além do caso de uso de autorização de pagamentos da Network International citado acima, vários adotantes iniciais já o utilizaram para impulsionar uma ampla gama de cargas de trabalho:
Detecção de fraudes em serviços financeiros: Um banco global processa transações de cartão de crédito do Kafka em tempo real e sinaliza atividades suspeitas, tudo em menos de 200 milissegundos — reduzindo o risco e o tempo de resposta sem replataforma.
Experiências personalizadas em varejo e mídia: Um provedor de streaming OTT atualiza recomendações de conteúdo imediatamente após um usuário terminar de assistir a um programa. Uma plataforma líder de e-commerce recalcula ofertas de produtos enquanto os clientes navegam — mantendo o engajamento alto com loops de feedback abaixo de um segundo.
Estado de sessão ao vivo e histórico de pesquisa: Um grande site de viagens rastreia e exibe as pesquisas recentes de cada usuário em tempo real entre dispositivos. Cada nova consulta atualiza o cache da sessão instantaneamente, permitindo resultados personalizados e preenchimento automático sem atraso.
Serviço de Features de ML em Tempo Real: Um aplicativo de entrega de comida atualiza features como localização do motorista e tempos de preparo em milissegundos. Essas atualizações fluem diretamente para modelos de machine learning e aplicativos voltados para o usuário, melhorando a precisão do ETA e a experiência do cliente.
Estes são apenas alguns exemplos. O modo em tempo real pode suportar qualquer carga de trabalho que se beneficie de transformar dados em decisões em milissegundos, desde alertas de sensores IoT e visibilidade da cadeia de suprimentos até telemetria de jogos ao vivo e personalização dentro do aplicativo.
Começando com o modo em tempo real
O modo em tempo real está agora disponível em Public Preview no Databricks. Se você já está usando o Structured Streaming, pode ativá-lo com uma única atualização de configuração e gatilho — sem reescritas necessárias.
Para experimentar no DBR 16.4 ou superior:
- Crie um cluster (recomendamos o Modo Dedicado) no Databricks com acesso à Public Preview.
Ative o modo em tempo real definindo a seguinte configuração:
Use o novo gatilho em sua consulta:
Checkpointing
A opção trigger(RealTimeTrigger.apply(...)) ativa o novo modo de execução em tempo real, permitindo que você alcance latências de processamento abaixo de um segundo. RealTimeTrigger aceita um argumento que especifica a frequência com que a consulta faz checkpoint. Por exemplo, trigger(RealTimeTrigger.apply(“x minutos”)) Por padrão, o intervalo de checkpoint é de 5 minutos, o que funciona bem para a maioria dos casos de uso. Reduzir este intervalo aumenta a frequência de checkpoint, mas pode impactar a latência. A maioria das fontes e sinks de streaming são suportadas, incluindo Kafka, Kinesis e forEach para escrita em sistemas externos.
Resumo
O modo em tempo real é ideal para casos de uso que exigem a menor latência possível. Para muitas cargas de trabalho analíticas, o modo de micro-lotes padrão pode ser mais econômico, ao mesmo tempo em que atende aos requisitos de latência. O modo em tempo real introduz uma pequena sobrecarga de sistema, portanto, recomendamos usá-lo para pipelines críticos de latência, como os exemplos acima. O suporte para fontes e sinks adicionais está em expansão, e estamos trabalhando ativamente para ampliar a compatibilidade e reduzir ainda mais a latência.
Para mais detalhes, por favor, revise a documentação do modo em tempo real para detalhes completos de implementação, fontes e sinks suportados, e exemplos de consultas. Você encontrará tudo o que precisa para ativar o novo gatilho e configurar suas cargas de trabalho de streaming.
Para uma visão mais ampla das novidades no Apache Spark, incluindo como o modo em tempo real se encaixa na evolução do motor, assista à keynote do Spark de Michael Armbrust do DAIS 2025. Ela cobre as mudanças arquiteturais por trás do próximo capítulo do Spark, com o modo em tempo real como parte central da história.
Para se aprofundar na engenharia por trás do modo em tempo real, assista à nossa sessão técnica aprofundada de nossos engenheiros, que detalha o design e a implementação.
E para ver como o modo em tempo real se encaixa na estratégia de streaming mais ampla no Databricks, confira o Guia Abrangente de Streaming na Plataforma de Inteligência de Dados.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.