DeepSeek R1 no Databricks
por Dan Pechi, Jai Behl, Michael Shtelma, Austin Zaccor e Hanlin Tang
- Implemente o DeepSeek-R1 com o Databricks Model Serving
- Aumente a eficiência com modelos destilados para raciocínio custo-efetivo.
- Gerencie o DeepSeek-R1 perfeitamente ao lado do OpenAI, Amazon Bedrock e outros modelos.
Deepseek-R1 é um modelo aberto de última geração que, pela primeira vez, introduz a capacidade de 'raciocínio' para a comunidade de código aberto. Em particular, o lançamento também inclui a destilação dessa capacidade nos modelos Llama-70B e Llama-8B, proporcionando uma combinação atraente de velocidade, custo-benefício e agora capacidade de 'raciocínio'. Estamos animados para compartilhar como você pode facilmente baixar e executar os modelos destilados DeepSeek-R1-Llama no Databricks Model Serving, e se beneficiar de sua segurança, otimizações de desempenho de primeira classe e integração com a Plataforma de Inteligência de Dados Databricks. Agora, com esses modelos de 'raciocínio' abertos, construa sistemas de agentes que podem raciocinar sobre seus dados de maneira ainda mais inteligente.
Implementando Modelos Deepseek-R1-Distilled-Llama no Databricks
Para baixar, registrar e implantar os modelos Deepseek-R1-Distill-Llama no Databricks, use o notebook incluído aqui, ou siga as instruções fáceis abaixo:
1. Inicie o cálculo necessário¹ e carregue o modelo e seu tokenizador:
Este processo deve levar alguns minutos, pois baixamos 32GB de pesos do modelo no caso do Llama 8B.
2. Em seguida, registre o modelo e o tokenizador como um modelo de transformadores. mlflow.transformers torna o registro de modelos no Catálogo Unity simples - basta configurar o tamanho do seu modelo (neste caso, 8B) e o nome do modelo.
1 Usamos o ML Runtime 15.4 LTS e um cluster de nó único g4dn.4xlarge para o modelo de 8B e um g6e.4xlarge para o modelo de 70B. Você não precisa necessariamente de GPUs para implantar o modelo dentro do notebook, desde que o computador usado tenha capacidade de memória suficiente.
3. Para servir este modelo usando nosso motor de Model Serving altamente otimizado, basta navegar até Serving e lançar um endpoint com seu modelo registrado!
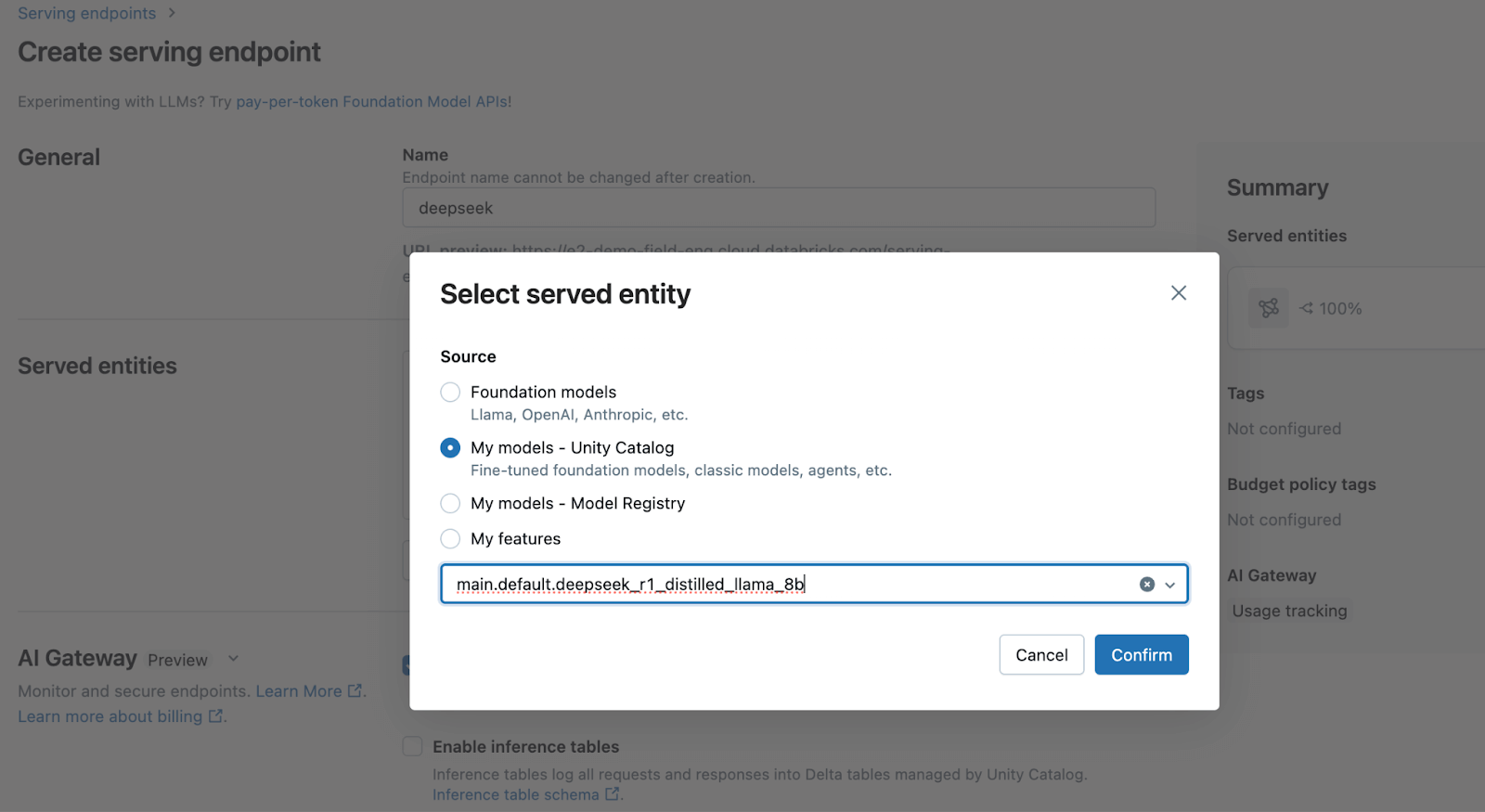
Uma vez que o endpoint esteja pronto, você pode facilmente consultar o modelo através da nossa API, ou usar o Playground para começar a prototipar suas aplicações.
Com o Databricks Model Serving, implantar este modelo é simples, mas poderoso, aproveitando nossas otimizações de desempenho de primeira classe, bem como a integração com o Lakehouse para governança e segurança.
Quando usar modelos de raciocínio
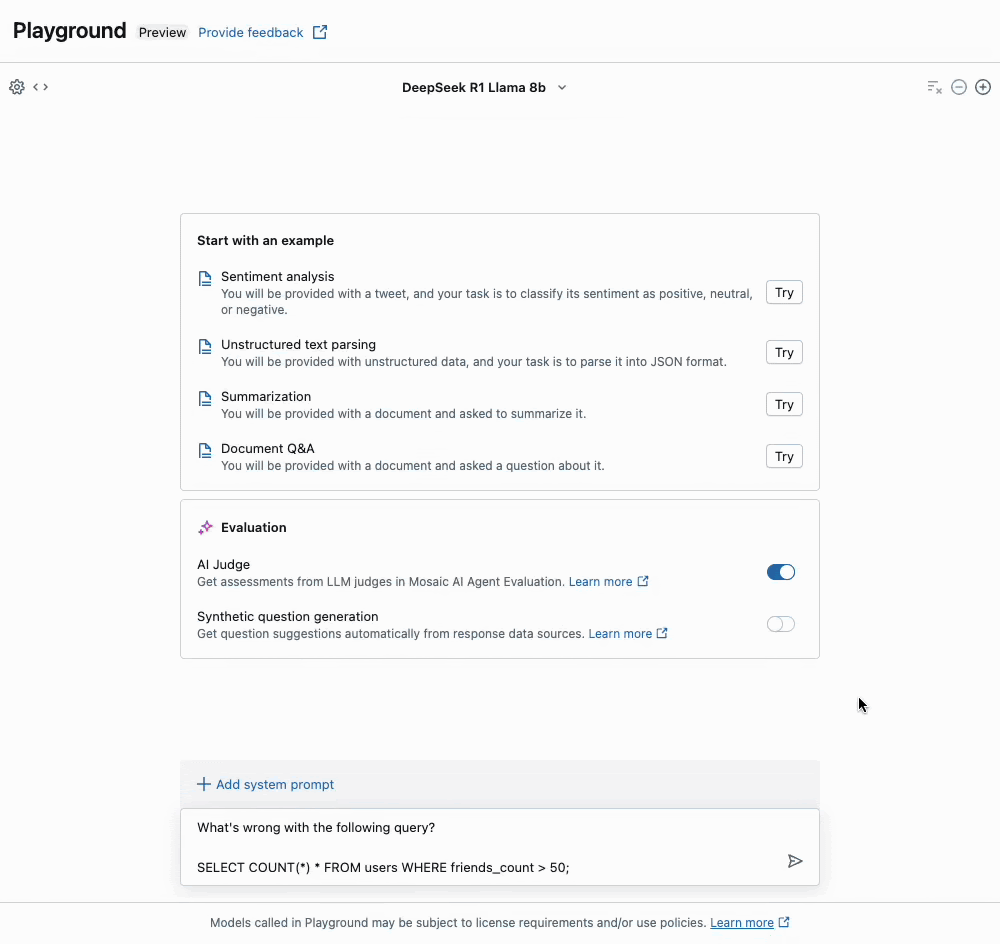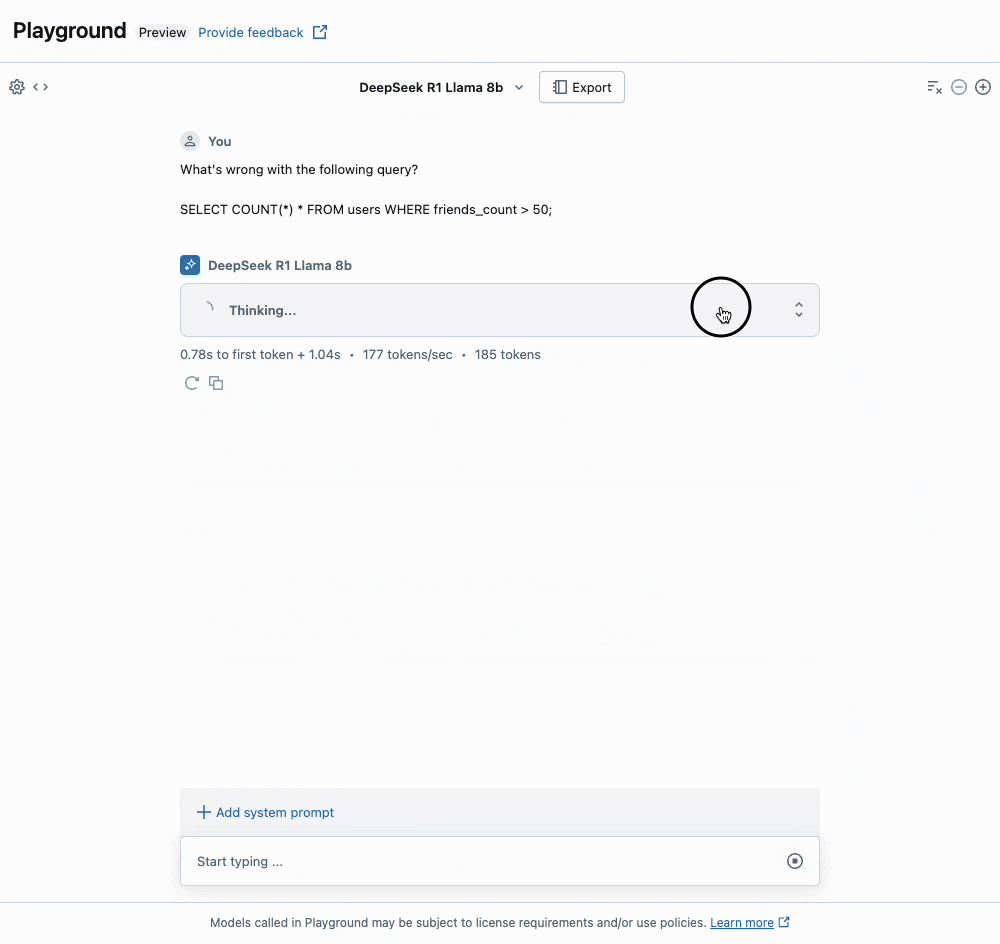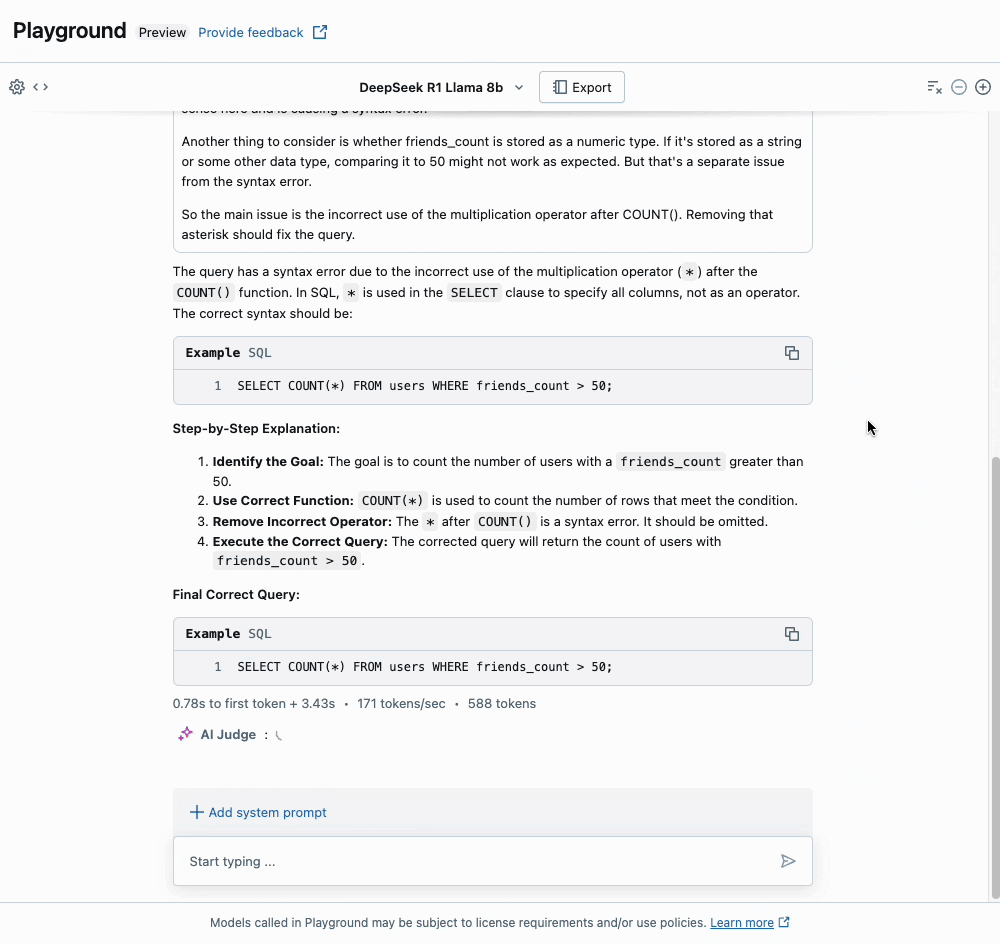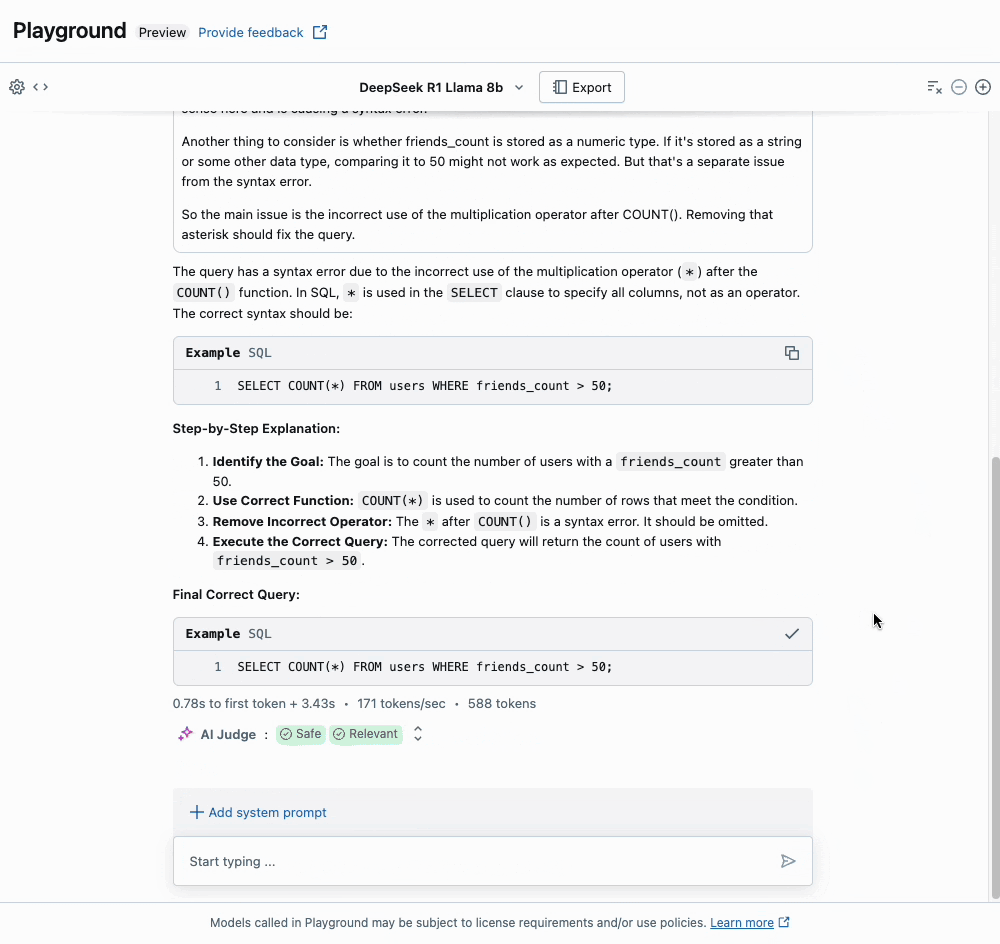
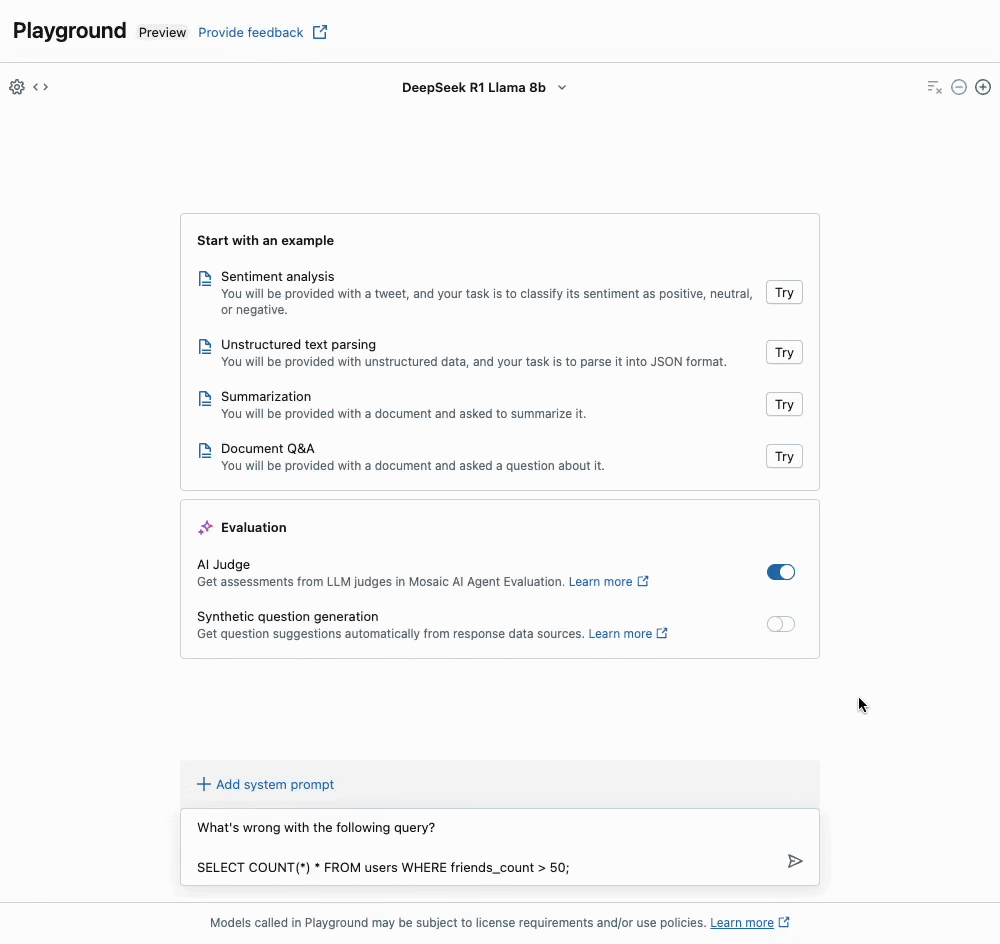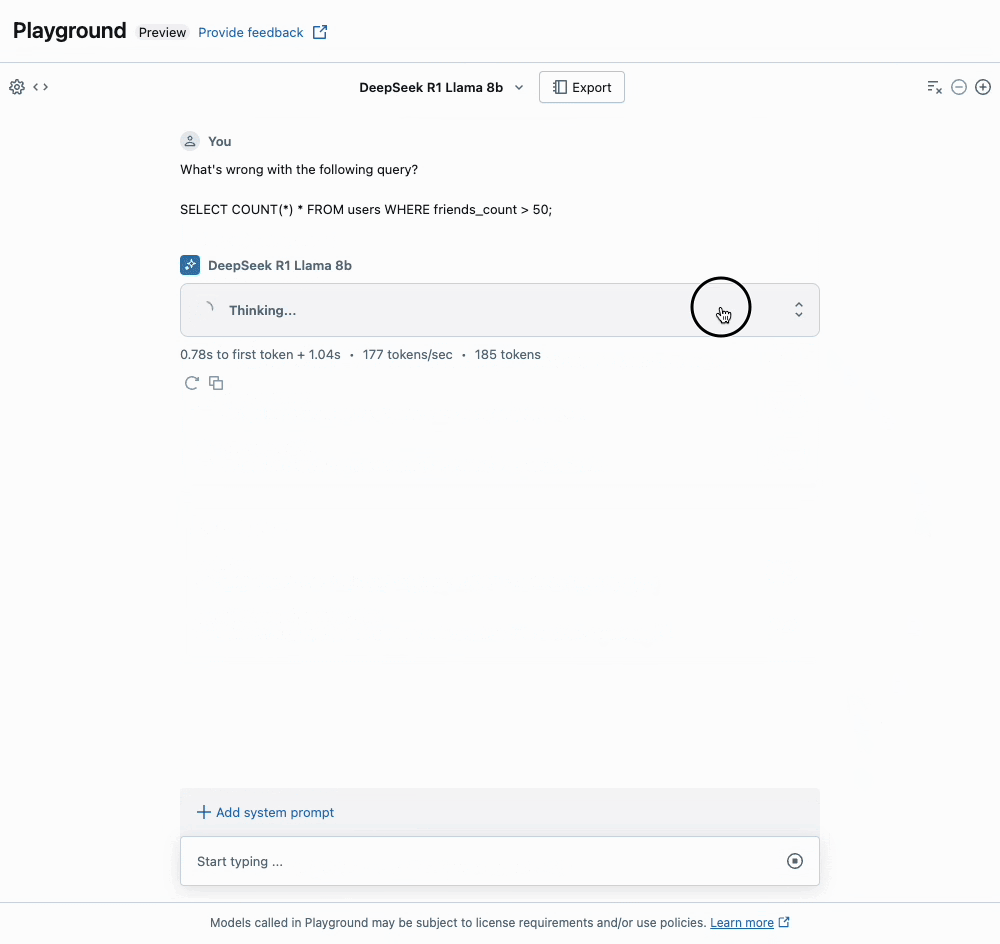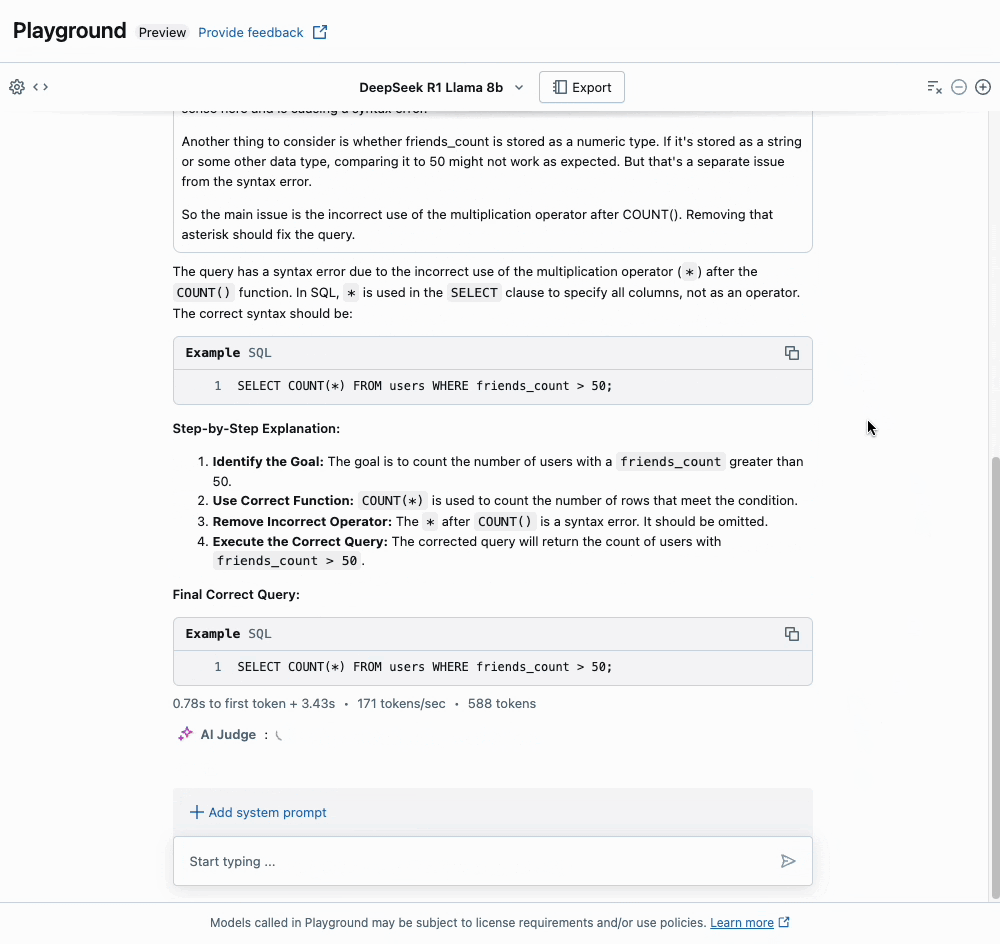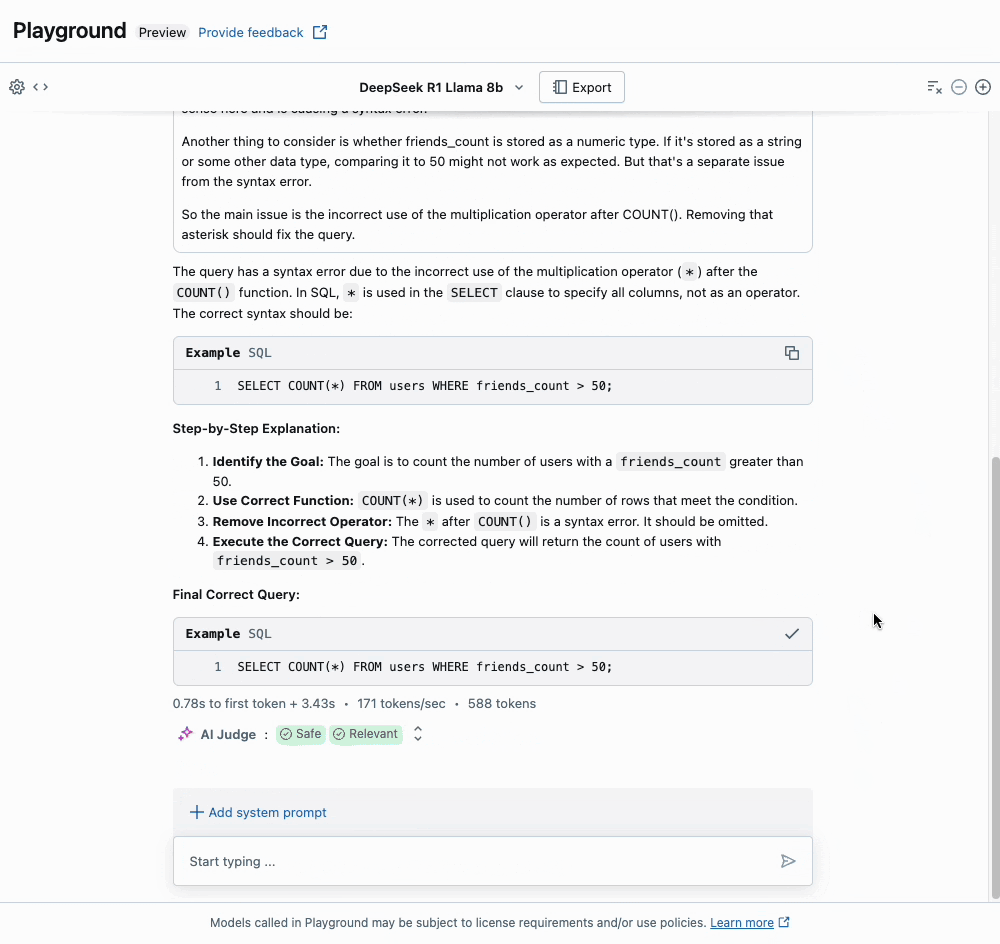
Um aspecto único da série de modelos Deepseek-R1 é a capacidade deles para uma cadeia de pensamento estendida (CoT), semelhante aos modelos o1 da OpenAI. Você pode ver isso em nossa interface de usuário Playground, onde a seção "Thinking" expansível mostra os rastros CoT do raciocínio do modelo. Isso pode levar a respostas de maior qualidade, particularmente para matemática e codificação, mas ao custo de significativamente mais tokens de saída. Também recomendamos que os usuários sigam as Diretrizes de Uso da Deepseek ao interagir com o modelo.
Estamos nos primeiros passos de saber como usar modelos de raciocínio, e estamos animados para ouvir quais novos sistemas de inteligência de dados nossos clientes podem construir com essa capacidade. Incentivamos nossos clientes a experimentar com seus próprios casos de uso e nos informar o que encontram. Fique atento para atualizações adicionais nas próximas semanas, enquanto mergulhamos mais fundo no R1, raciocínio e como construir inteligência de dados no Databricks.
Recursos
- Saiba mais sobre Databricks Model Serving
- Aplique modelos Deepseek-R1-distilled-Llama em grandes lotes de dados com Inferência em Lote LLM
- Construa Aplicativos Agentic e RAG de qualidade de produção com Agent Framework and Evaluation
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.