Anunciando o Lakebase Change Data Feed (CDF)
Abrindo o banco de dados OLTP para outros motores
- O Lakebase Change Data Feed (Public Preview) elimina a proliferação de pipelines de bancos de dados operacionais. Ative o CDF uma vez por projeto Lakebase para expor as alterações de cada tabela por meio de Tabelas Gerenciadas do Unity Catalog para acesso de leitura direta por qualquer motor, modelo ou agente.
- CDC nativo governado de ponta a ponta sem infraestrutura secundária: sem conectores de banco de dados, monitoramento de estado de replicação ou trabalhos de extração separados; consumidores downstream como pipelines de streaming SDP, visualizações materializadas DBSQL e embeddings Agent Bricks assinam o mesmo feed isolado sem impactar a carga de trabalho primária.
- Dados operacionais agora funcionam como a camada Bronze nativa na arquitetura medallion. As Tabelas Sincronizadas do Lakebase já servem dados Gold para aplicações; o Lakebase CDF fecha o ciclo com governança e linhagem completas do Unity Catalog em todo o ciclo de vida dos dados.
Mover dados do seu banco de dados operacional tradicionalmente significava configurar e monitorar um pipeline para cada origem e cada destino. Para a maioria das equipes, isso representa um esforço humano frágil, não governado e com complexidade O(n).
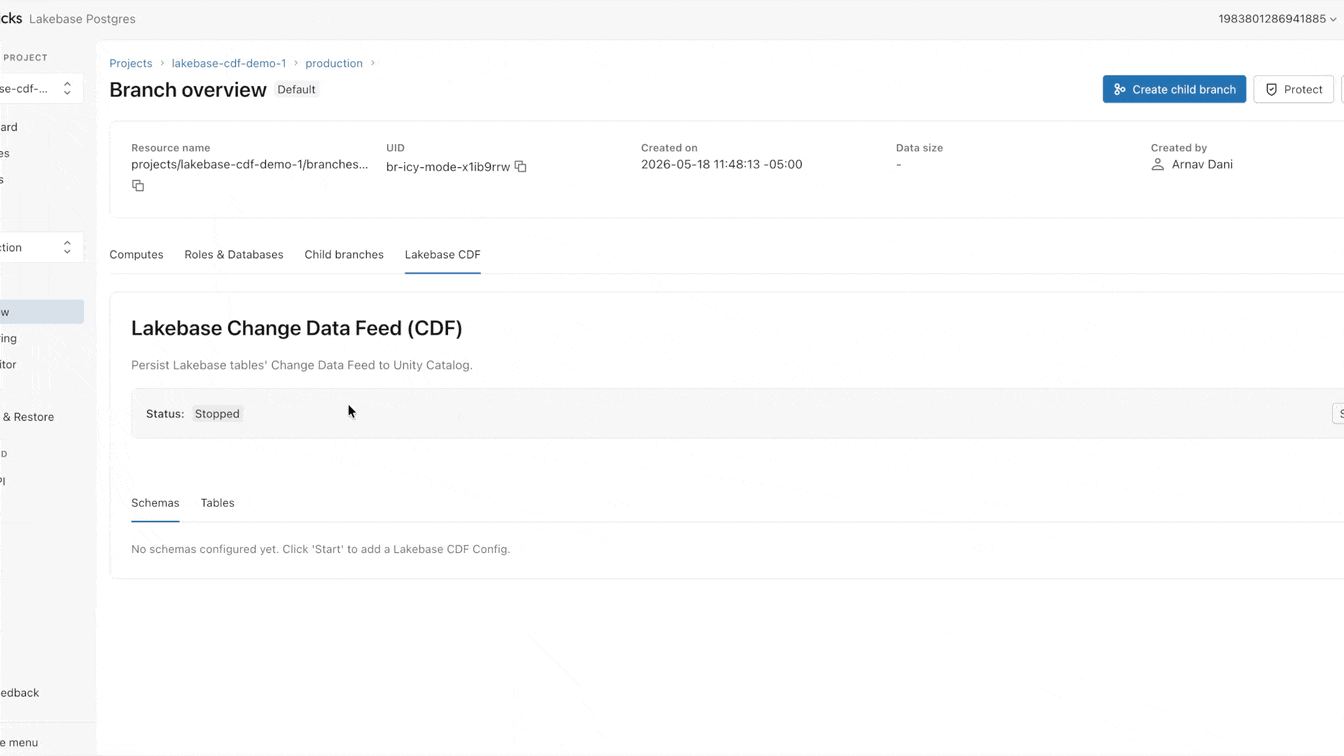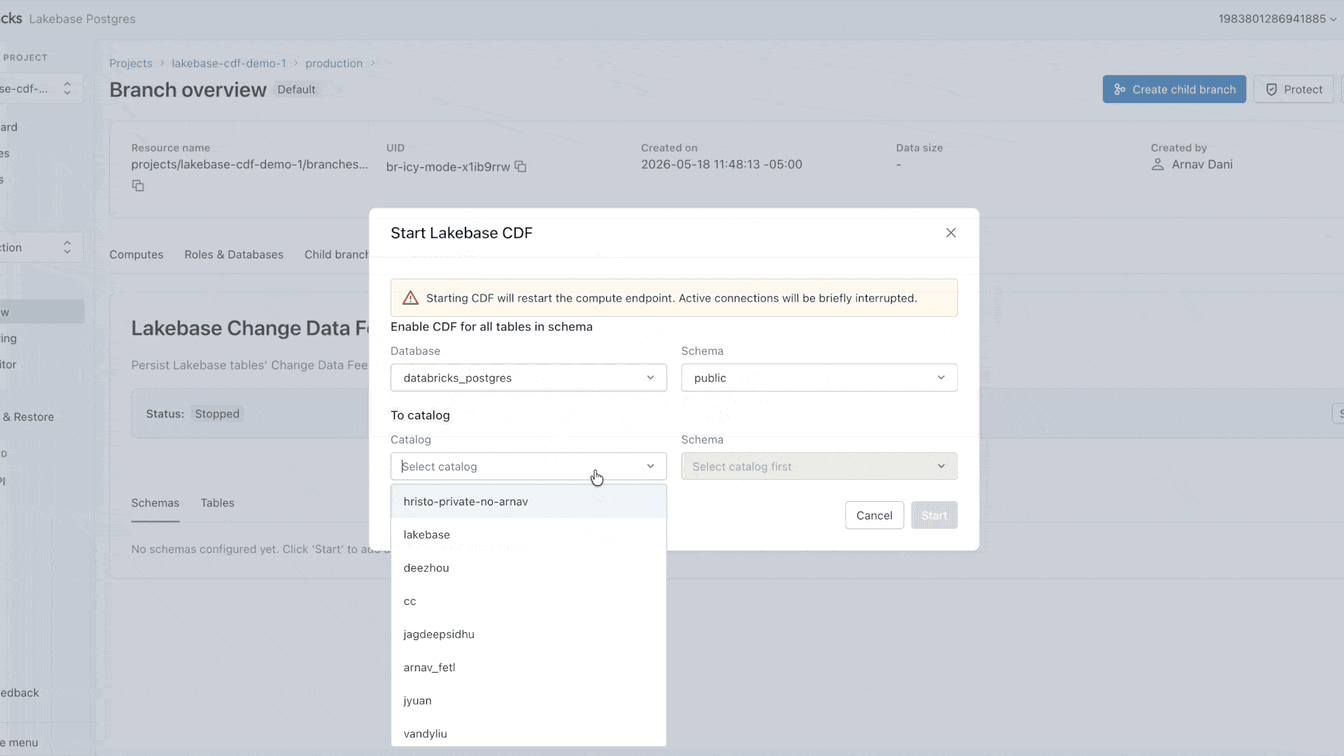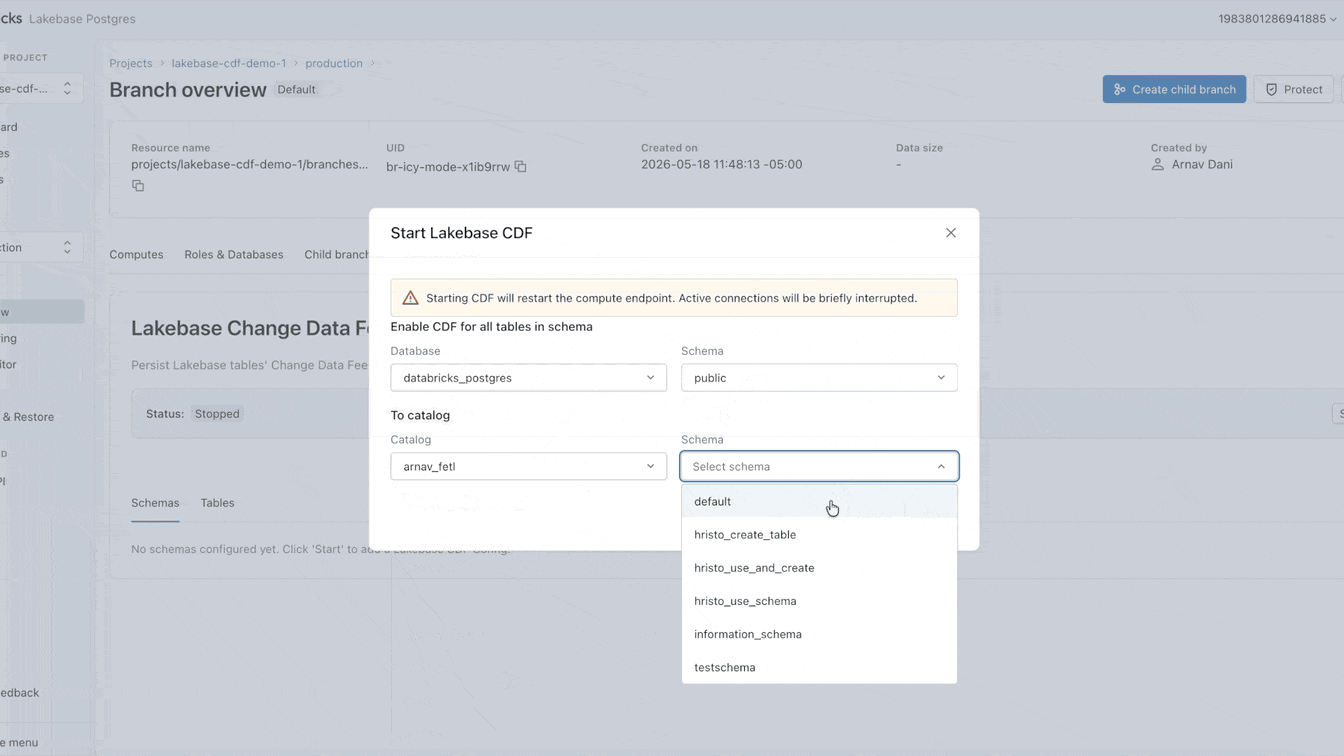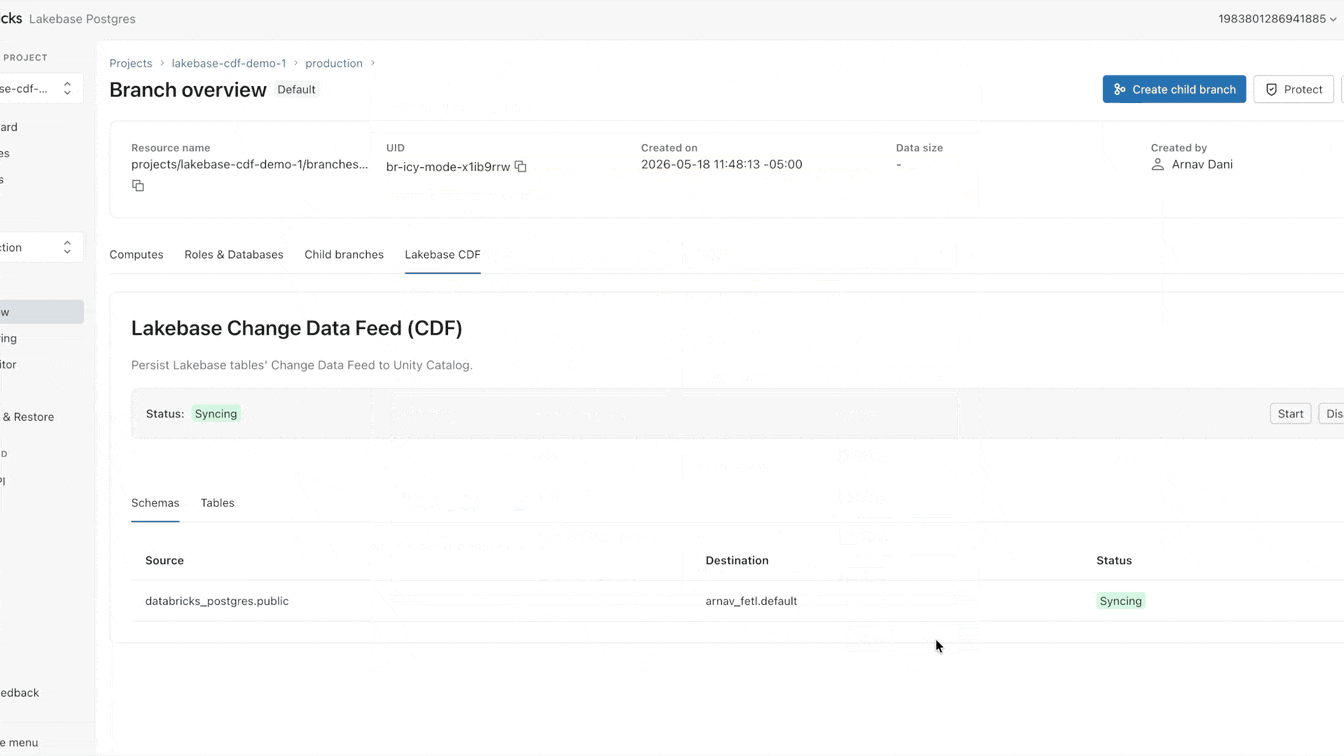
Hoje, estamos mudando essa abordagem. Disponível agora em Public Preview, Lakebase apresenta um Change Data Feed (CDF) que é armazenado e governado em Tabelas Gerenciadas do Unity Catalog. Ative o feed uma vez e permita que todos os motores, modelos e agentes leiam diretamente dele.
Por que ainda é tão difícil carregar dados operacionais no lake?
Embora o Lakeflow Connect tenha tornado a ingestão de dados no Lakehouse trivial, extrair dados do banco de dados OLTP continua sendo um processo manual e de alto atrito. Extrair a Captura de Dados de Alteração (CDC) força as equipes a configurar conectores de banco de dados, supervisionar estados de replicação, mitigar impactos de desempenho e rastrear erros por meio de ferramentas desconectadas. Esse modelo falha no desenvolvimento baseado em agentes que depende de ramificação rápida de dados. Manter pipelines de extração complexos e não governados para cada nova ramificação e cada destino é insustentável.
Nós resolvemos isso no Lakehouse. Agora estamos trazendo para o Lakebase.
O Lakehouse eliminou os pipelines de extração para análise, armazenando os dados uma vez em formatos abertos (Apache Iceberg™, Delta Lake). Ele estabeleceu o Change Data Feed (CDF) como o padrão para replicação downstream, alimentando fluxos de trabalho de ETL, streaming e logs de auditoria.
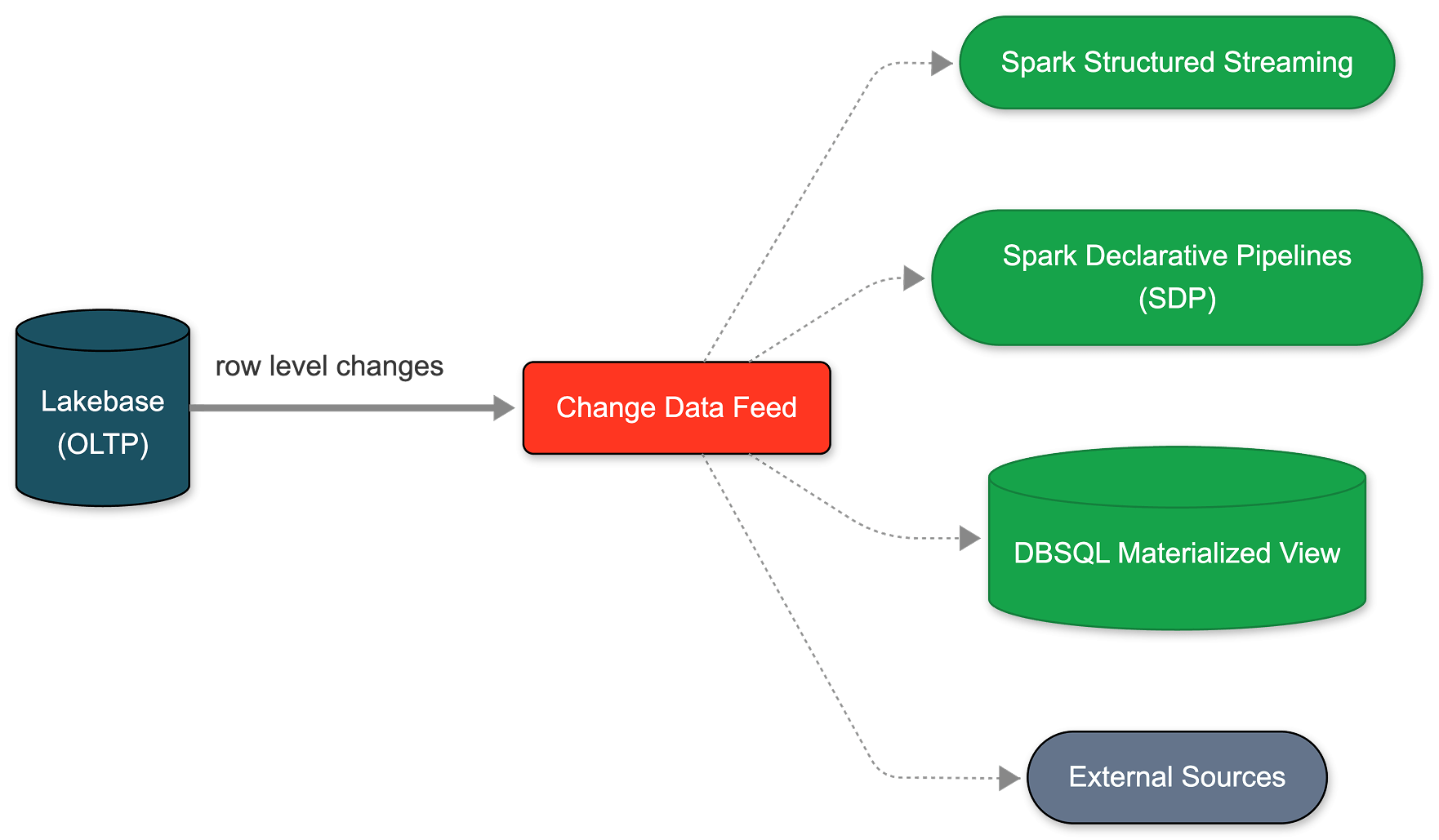
Agora você pode configurar esse CDF nativamente no Lakebase. Leva menos de um minuto para ativar, aplicando-se a todas as tabelas dentro de um projeto. A partir deste feed único, você pode construir pipelines de streaming com SDP, gerar visualizações materializadas com DBSQL ou computar e armazenar embeddings com Agent Bricks. Cada consumidor downstream assina o mesmo feed exato, completamente isolado da sua carga de trabalho operacional primária.
Bancos de dados operacionais pertencem à arquitetura medallion
Com o Lakebase, seus dados operacionais não estão mais isolados do Lakehouse. O Lakebase já oferece Synced Tables, estabelecendo o padrão de servir datasets Gold diretamente para aplicações. O Lakebase CDF completa a arquitetura. Seu banco de dados operacional agora é sua camada Bronze nativa, eliminando a necessidade de pipelines separados ou trabalhos de extração para carregar dados no Lakehouse. Em vez disso, você obtém governança e linhagem completas em todo o ciclo de vida dos dados por meio do Unity Catalog.
Este é apenas o começo. Estamos trazendo a abertura que você ama do Lakehouse diretamente para o Lakebase. Fique ligado para o Data and AI Summit e participe da nossa sessão especial sobre esta arquitetura.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.