Arquitetando a colaboração global de dados com o Delta Sharing
Permita que sua organização ganhe escala compartilhando dados de forma segura e eficiente entre nuvens, plataformas e regiões.
por Matei Zaharia, Bilal Obeidat, Tianyi Huang e Giselle Goicochea
O Delta Sharing evoluiu para OpenSharing, o primeiro protocolo aberto e neutro em relação a fornecedores para compartilhar com segurança ativos de IA, incluindo habilidades de agentes, modelos de IA e dados não estruturados. Leia o anúncio.
No cenário digital interconectado de hoje, o compartilhamento de dados e a colaboração entre organizações e plataformas são cruciais para as operações de negócios modernas. O Delta Sharing, um protocolo inovador e aberto de compartilhamento de dados, capacita as organizações a compartilhar e acessar dados com segurança em diversas plataformas, priorizando a segurança e a escalabilidade, sem restrições de fornecedor ou formato de dados.
Este blog é dedicado a apresentar opções de replicação de dados no Delta Sharing, explorando orientações de arquitetura adaptadas a cenários específicos de compartilhamento de dados. Com base em insights de nossas experiências com muitos clientes do Delta Sharing, nosso objetivo é reduzir os custos de saída de dados (egress) e melhorar o desempenho, fornecendo alternativas específicas de replicação de dados. Embora o compartilhamento em tempo real (live sharing) continue sendo adequado para muitos cenários de compartilhamento de dados entre regiões, há casos em que replicar todo o conjunto de dados e estabelecer um processo de atualização de dados para réplicas regionais locais se mostra mais econômico. O Delta Sharing facilita isso por meio do uso do armazenamento Cloudflare R2, do Change Data Feed (CDF) do Delta Sharing e das funcionalidades de Delta Deep Cloning. Como resultado dessas capacidades, o Delta Sharing é altamente valorizado pelos clientes por capacitar os usuários e oferecer uma flexibilidade excepcional no atendimento às suas necessidades de compartilhamento de dados.
O Delta Sharing é aberto, flexível e econômico
A Databricks e a Linux Foundation desenvolveram o Delta Sharing para fornecer a primeira abordagem de código aberto para compartilhamento de dados em dados, análise de dados e IA. Os clientes podem compartilhar dados em tempo real entre plataformas, nuvens e regiões com forte segurança e governança. Quer você use o projeto de código aberto por meio de auto-hospedagem (self-hosting) ou o Delta Sharing totalmente gerenciado na Databricks – ambos oferecem uma solução flexível, econômica e independente de plataforma para a entrega global de dados. Os clientes da Databricks recebem benefícios adicionais em um ambiente gerenciado que minimiza a sobrecarga administrativa e se integra nativamente ao Databricks Unity Catalog. Essa integração oferece uma experiência simplificada para o compartilhamento de dados dentro e entre organizações.
Delta Sharing na Databricks tem tido uma ampla adoção em vários cenários de colaboração desde sua disponibilidade geral em agosto de 2022.
Neste blog, exploraremos dois padrões de arquitetura comuns nos quais o Delta Sharing desempenhou um papel fundamental para viabilizar e aprimorar cenários de negócios críticos:
- Compartilhamento de dados entre regiões intra-empresa
- Modelo de agregador de dados (Hub and Spoke)
Como parte deste blog, também demonstraremos que a arquitetura de implantação do Delta Sharing é flexível e pode ser estendida de forma integrada para atender a novos requisitos de compartilhamento de dados.
Compartilhamento de dados entre regiões intra-empresa
Neste caso de uso, ilustraremos um padrão comum de implantação do Delta Sharing entre nossos clientes, onde há uma necessidade de negócios de compartilhar alguns dados entre regiões, como ter uma equipe de QA em regiões separadas ou uma equipe de relatórios interessada em dados de atividades de negócios em escala global. Geralmente, o compartilhamento de tabelas intra-empresa envolve:
- Compartilhamento de tabelas grandes: Há um requisito para compartilhar tabelas grandes em tempo real com os destinatários, onde os padrões de acesso variam. Os destinatários frequentemente executam consultas diversas com predicados diferentes. Um bom exemplo são os dados de clickstream e atividade do usuário, casos em que o acesso remoto é mais apropriado.
- Replicação local: Para melhorar o desempenho e gerenciar melhor os custos de saída de dados (egress), alguns dados devem ser replicados para criar uma cópia local, especialmente quando a região do destinatário tem um número significativo de usuários que acessam essas tabelas com frequência.
Neste cenário, tanto as unidades de negócios do provedor de dados quanto as do destinatário de dados compartilham a mesma conta do Unity Catalog, mas possuem metastores diferentes no Databricks.
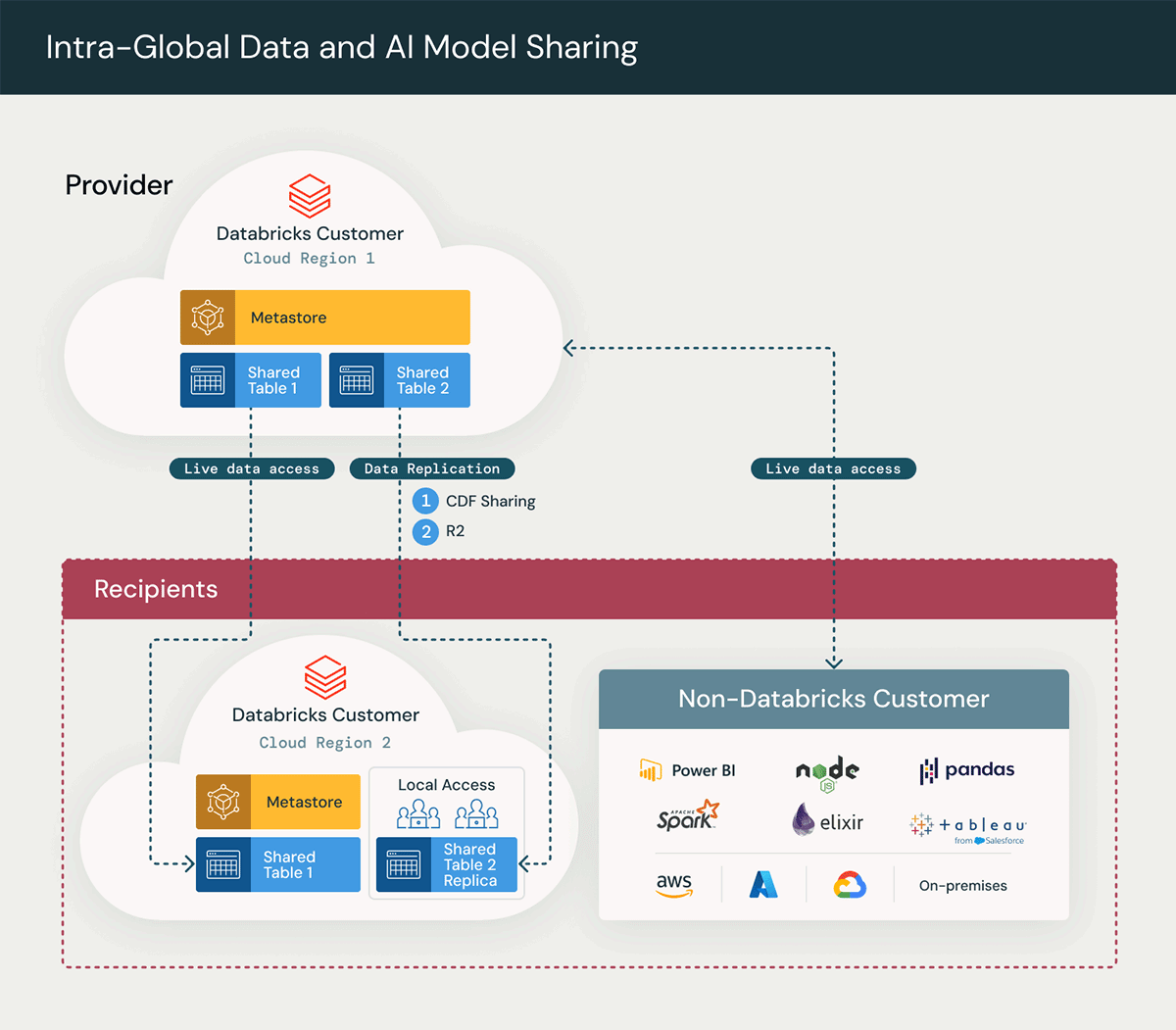
O diagrama acima ilustra uma arquitetura de alto nível da solução Delta Sharing, destacando as principais etapas do processo do Delta Sharing:
- Criação de um compartilhamento (share): Tabelas em tempo real são compartilhadas com o destinatário, permitindo o acesso imediato aos dados.
- Replicação de dados sob demanda: A implementação da replicação de dados sob demanda envolve a geração de uma cópia regional dos dados para melhorar o desempenho, reduzindo a necessidade de acesso à rede entre regiões e minimizando as taxas de saída de dados (egress) associadas. Isso é alcançado por meio da utilização das seguintes abordagens para replicação de dados:
A. Change Data Feed em uma tabela compartilhada
Esta opção requer o compartilhamento do histórico da tabela e a ativação do Change Data Feed (CDF), que deve ser explicitamente ativado no código de configuração definindo a propriedade da tabela delta.enableChangeDataFeed = true usando os comandos Create/Alter table.
Além disso, ao adicionar a tabela ao compartilhamento (Share), certifique-se de que ela seja adicionada com a opção CDF, conforme mostrado no exemplo abaixo.
Depois que os dados forem adicionados ou atualizados, as alterações poderão ser acessadas como neste exemplo
No lado do destinatário, as alterações podem ser acessadas e mescladas em uma cópia local dos dados de maneira semelhante à apresentada neste notebook. A propagação das alterações da tabela compartilhada para uma réplica local pode ser orquestrada usando um trabalho de fluxo de trabalho (workflow job) do Databricks.
B. Cloudflare R2 com a Databricks
O R2 é uma excelente opção para todos os cenários de Delta Sharing porque os clientes podem aproveitar ao máximo o potencial de compartilhamento sem se preocupar com cobranças imprevisíveis de saída de dados (egress). Isso é discutido em detalhes mais adiante neste blog.
C. Delta Deep Clone
Outra opção de caso especial para compartilhamento intra-empresa é usar o Delta Deep Clone ao compartilhar dentro da mesma conta de nuvem da Databricks. O Deep Cloning é uma funcionalidade do Delta que copia tanto os dados da tabela de origem quanto os metadados da tabela existente para o destino do clone. Além disso, o comando deep clone tem a capacidade de identificar novos dados e atualizá-los de acordo. Aqui está a sintaxe:
O comando anterior é executado no lado do destinatário, onde source_table_name é a tabela compartilhada e table_name é a cópia local dos dados que os usuários podem acessar.
Um trabalho simples do Databricks Workflows pode ser agendado para uma atualização incremental dos dados com as atualizações recentes usando o seguinte comando:
O mesmo caso de uso pode ser facilmente estendido para compartilhar dados com parceiros e clientes externos na plataforma Databricks ou em qualquer outra plataforma. Este é outro padrão estendido comum em que parceiros e clientes externos, que não usam o Databricks, desejam acessar esses dados por meio do Excel, Power BI, Pandas e outros softwares compatíveis, como o Oracle.
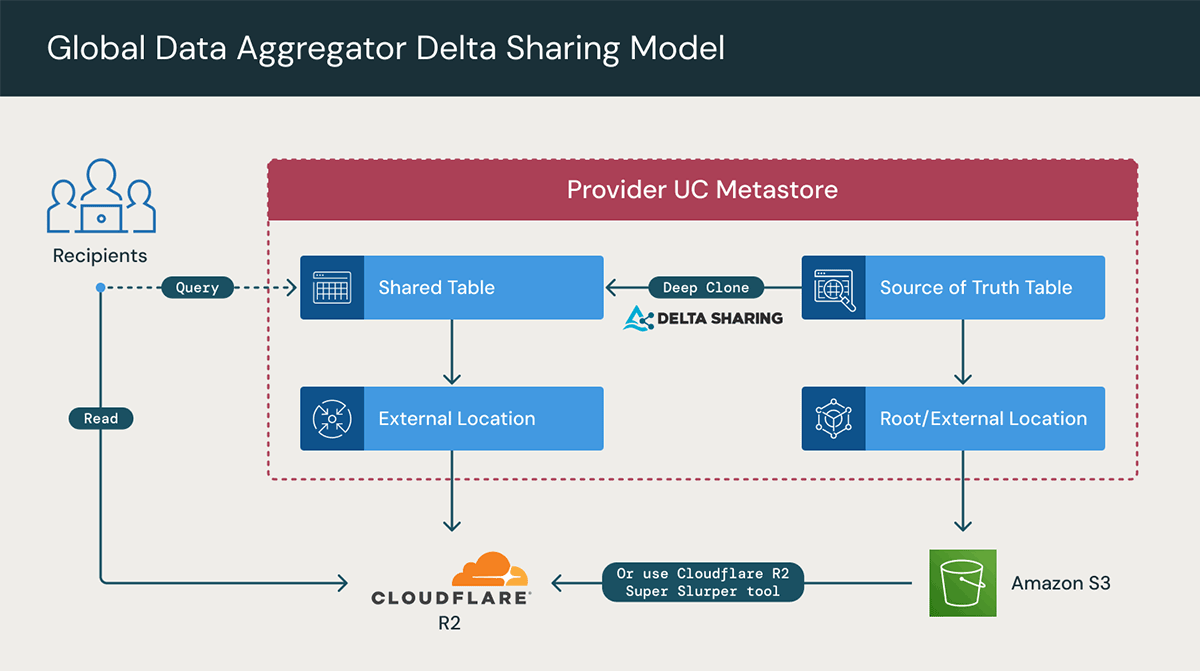
Modelo de agregador de dados (modelo Hub and Spoke)
Outro padrão de cenário comum surge quando uma empresa está focada em compartilhar dados com clientes, particularmente em casos que envolvem empresas agregadoras de dados ou quando a principal função de negócios é coletar dados em nome dos clientes. Um agregador de dados, como entidade, é especializado em coletar e mesclar dados de diversas fontes em um conjunto de dados unificado e coeso. Esses compartilhamentos de dados são fundamentais para atender a diversas necessidades de negócios, como tomada de decisões de negócios, análise de mercado, pesquisa e suporte às operações gerais de negócios.
O modelo de compartilhamento de dados neste padrão faz o seguinte:
- Conecta destinatários distribuídos em várias nuvens, incluindo AWS, Azure e GCP.
- Oferece suporte ao consumo de dados em diversas plataformas, variando em complexidade desde código Python até planilhas do Excel.
- Permite escalabilidade para o número de destinatários, a quantidade de compartilhamentos e os volumes de dados.
Em geral, isso normalmente pode ser alcançado pelo provedor estabelecendo um workspace do Databricks em cada nuvem e replicando os dados usando CDF em uma tabela compartilhada (conforme discutido acima) em todas as três nuvens para melhorar o desempenho e reduzir os custos de egress. Em seguida, dentro de cada região de nuvem, os dados podem ser compartilhados com os clientes e parceiros apropriados.
No entanto, uma abordagem nova, mais eficiente e direta pode ser adotada utilizando o R2 por meio da Cloudflare com o Databricks, atualmente em private preview.
A integração do Cloudflare R2 com o Databricks permitirá que as organizações compartilhem e colaborem em dados em tempo real de forma segura, simples e econômica. Com a Cloudflare e o Databricks, os clientes em comum podem eliminar a complexidade e os custos dinâmicos que impedem o aproveitamento total do potencial das iniciativas de análise multicloud e de AI. Especificamente, haverá taxa zero de egress e nenhuma necessidade de transferências de dados complexas ou replicação dispendiosa de conjuntos de dados entre regiões.
O uso dessa opção requer as seguintes etapas:
- Adicionar o Cloudflare R2 como um local de armazenamento externo (mantendo a fonte da verdade dos dados no S3/ADLS/etc.)
- Criar novas tabelas no Cloudflare R2 e sincronizar os dados de forma incremental
- Delta deep clone
- R2 Super Slurper
- Criar um Delta Share, como de costume, na tabela R2
Conforme explicado acima, essas abordagens demonstram vários métodos de replicação de dados sob demanda, cada um com suas vantagens distintas e requisitos específicos, tornando-os adequados para vários casos de uso.
Comparando métodos de replicação de dados para compartilhamento entre regiões
Todos os três mecanismos anteriores permitem que os usuários do Delta Sharing criem uma cópia local para minimizar as taxas de egress, especialmente entre nuvens e regiões. A tabela abaixo fornece um resumo rápido para diferenciar essas opções.
| Ferramenta de replicação de dados | Principais destaques | Recomendação |
|---|---|---|
| Change data feed em uma tabela compartilhada |
| Use para compartilhamento externo com parceiros/clientes entre regiões |
| Cloudflare R2 com Databricks |
| Fortemente recomendado para Delta Sharing em grande escala em termos de número de compartilhamentos e mais de 2 regiões |
| Delta Deep Clone |
| Recomendado ao compartilhar internamente entre regiões |
O Delta Sharing é aberto, flexível e econômico e, no Databricks, oferece suporte a um amplo espectro de ativos de dados, incluindo notebooks, volumes e modelos de AI. Além disso, várias otimizações melhoraram significativamente o desempenho dos protocolos do Delta Sharing. O investimento contínuo do Databricks nos recursos do Delta Sharing, incluindo monitoramento aprimorado, escalabilidade, facilidade de uso e observabilidade, reforça seu compromisso em aprimorar a experiência do usuário e garantir que o Delta Sharing permaneça na vanguarda da colaboração de dados no futuro.
Próximos passos
Ao longo deste blog, fornecemos orientações de arquitetura com base em nossa experiência com muitos clientes do Delta Sharing. Nosso foco principal está no gerenciamento de custos e no desempenho. Embora o compartilhamento em tempo real seja adequado para muitos cenários de compartilhamento de dados entre regiões, exploramos casos em que a replicação de todo o conjunto de dados e o estabelecimento de um processo de atualização de dados para réplicas regionais locais se mostram mais econômicos. O Delta Sharing facilita isso por meio da utilização das funcionalidades do R2 e do CDF Delta Sharing, oferecendo aos usuários maior flexibilidade.
No caso de uso de compartilhamento de dados entre regiões dentro da empresa (Intra-Enterprise Cross-Regional Data Sharing), o Delta Sharing se destaca no compartilhamento de tabelas grandes com padrões de acesso variados. A replicação local, facilitada pelo compartilhamento de CDF, garante o desempenho ideal e o gerenciamento de custos. Além disso, o R2 por meio da Cloudflare com o Databricks oferece uma opção eficiente para o Delta Sharing em grande escala em várias regiões e nuvens.
Para saber mais sobre como integrar o Delta Sharing à sua estratégia de colaboração de dados, confira os recursos mais recentes:
- Leia o guia técnico da O'Reilly, Data Sharing and Collaboration with Delta Sharing (lançamento antecipado)
- Aprofunde-se na documentação do Databricks Delta Sharing.
- Leia mais sobre o Delta Sharing: um padrão aberto para compartilhamento seguro de dados
- Assista ao anúncio em vídeo do Delta Sharing com Matei Zaharia (Keynote Data + AI Summit 2021)
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.