Agentes LLM são bons na otimização da ordem de junção?
por Eric Liang, Ryan Marcus, Sid Taneja e Yuhao Zhang
- O que é: Exploramos a aplicação de agentes de LLM (Large Language Model) de ponta ao problema clássico de otimização da ordem de junção (join order) em bancos de dados.
- O Desafio: Otimizadores de consulta tradicionais frequentemente enfrentam dificuldades com a Ordem de Junção, onde o número de planos possíveis cresce exponencialmente com o número de tabelas, muitas vezes levando a um desempenho ruim devido à cardinalidade mal estimada. Agentes de LLM abordam isso agindo como um DBA orientado por dados, raciocinando através de estatísticas de tempo de execução reais e contexto semântico que heurísticas automatizadas frequentemente perdem.
- Resultados e Conquistas: Em benchmarks experimentais, o agente protótipo melhorou o otimizador Databricks em 80% dos casos, melhorando a latência das consultas em um fator de 1.3x no geral.
Introdução
Na plataforma de inteligência Databricks, exploramos e utilizamos regularmente novas técnicas de IA para melhorar o desempenho do motor e simplificar a experiência do usuário. Aqui apresentamos resultados experimentais sobre a aplicação de modelos de ponta a um dos desafios mais antigos de bancos de dados: a ordenação de junções (join ordering).
Este blog faz parte de uma colaboração de pesquisa com a UPenn.
O Problema: Ordenação de Junções (Join Ordering)
Desde sua concepção, os otimizadores de consulta em bancos de dados relacionais têm lutado para encontrar boas ordenações de junções para consultas SQL. Para ilustrar a dificuldade da ordenação de junções, considere a seguinte consulta:
Quantos filmes foram produzidos pela Sony e estrelados por Scarlett Johansson?
Suponha que queremos executar esta consulta sobre o seguinte esquema:
| Nome da Tabela | Colunas da Tabela |
|---|---|
| Ator | actorID, actorName, actorDOB, … |
| Empresa | companyID, companyName, … |
| Estrelas | actorID, movieID |
| Produz | companyID, movieID |
| Filme | movieID, movieName, movieYear , … |
As tabelas de entidade Ator, Empresa e Filme estão conectadas através das tabelas de relacionamento Produz e Estrelas (por exemplo, via chaves estrangeiras). Uma versão desta consulta em SQL poderia ser:
Logicamente, queremos realizar uma operação de junção simples: Ator ⋈ Estrelas ⋈ Filme ⋈ Produz ⋈ Empresa. Mas fisicamente, como cada uma dessas junções é comutativa e associativa, temos muitas opções. O otimizador de consulta poderia escolher:
- Primeiro encontrar todos os filmes estrelados por Scarlett Johansson, depois filtrar apenas os filmes produzidos pela Sony,
- Primeiro encontrar todos os filmes produzidos pela Sony, depois filtrar os filmes estrelados por Scarlett Johansson,
- Em paralelo, computar os filmes da Sony e os filmes de Scarlett Johansson, depois pegar a interseção.
Qual plano é o ideal depende dos dados: se Scarlett Johansson estrelou significativamente menos filmes do que a Sony produziu, o primeiro plano pode ser o ideal. Infelizmente, estimar essa quantidade é tão difícil quanto executar a própria consulta (em geral). Pior ainda, normalmente há muito mais do que 3 planos para escolher, pois o número de planos possíveis cresce exponencialmente com o número de tabelas — e consultas analíticas frequentemente juntam 20-30 tabelas diferentes.
Como funciona a ordenação de junções hoje? Otimizadores de consulta tradicionais resolvem este problema com três componentes: um estimador de cardinalidade projetado para adivinhar rapidamente o tamanho de subconsultas (por exemplo, para adivinhar quantos filmes a Sony produziu), um modelo de custo para comparar diferentes planos potenciais e um procedimento de busca que navega pelo espaço exponencialmente grande. A estimativa de cardinalidade é especialmente difícil e levou a uma ampla gama de pesquisas que buscam melhorar a precisão da estimativa usando uma variedade de abordagens [A].
Todas essas soluções adicionam complexidade significativa a um otimizador de consulta e exigem um esforço de engenharia considerável para integrar, manter e colocar em produção. Mas e se agentes impulsionados por LLM, com suas habilidades de adaptação a novos domínios com prompting, detiverem a chave para resolver este problema de décadas?
Ordenação de Junções Agente (Agentic Join Ordering)
Quando otimizadores de consulta selecionam uma ordenação de junção ruim1, especialistas humanos podem corrigi-la diagnosticando o problema (frequentemente uma cardinalidade mal estimada) e instruindo o otimizador de consulta a escolher uma ordenação diferente. Este processo geralmente requer várias rodadas de testes (por exemplo, executando a consulta) e inspeção manual dos resultados intermediários.
Otimizadores de consulta geralmente precisam escolher ordenações de junção em algumas centenas de milissegundos, portanto, integrar um LLM no caminho crítico (hot path) do otimizador de consulta, embora potencialmente promissor, não é possível hoje. No entanto, o processo iterativo e manual de otimizar a ordenação de junção para uma consulta, que pode levar um especialista humano várias horas, poderia ser potencialmente automatizado com um agente LLM! Este agente tenta automatizar esse processo de ajuste manual.
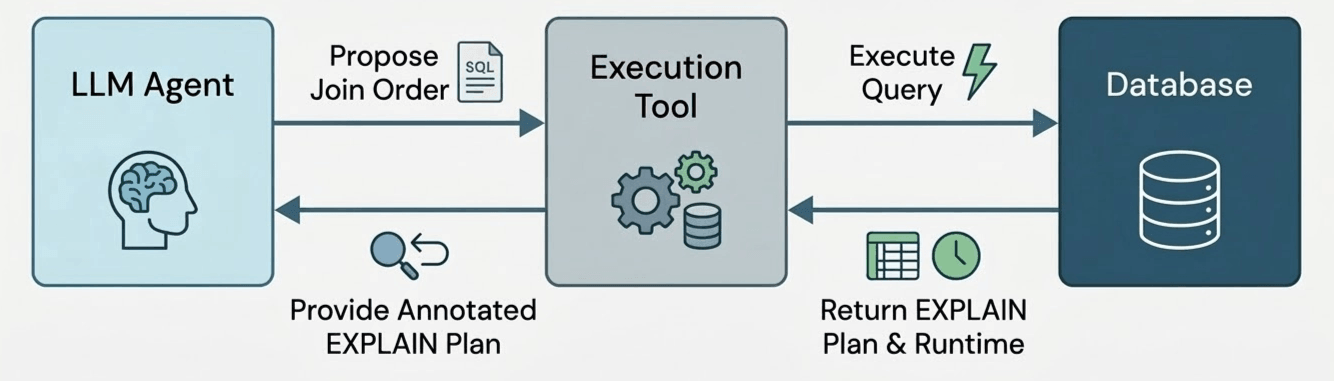
Para testar isso, desenvolvemos um protótipo de agente de otimização de consulta. O agente tem acesso a uma única ferramenta, que executa uma ordenação de junção potencial para uma consulta e retorna o tempo de execução da ordenação de junção (com um tempo limite da duração da consulta original) e o tamanho de cada subplano computado (por exemplo, o plano EXPLAIN EXTENDED).
Deixamos o agente rodar por 50 iterações, permitindo que ele experimente livremente diferentes ordenações de junção. O agente pode usar essas 50 iterações para testar planos promissores (“exploração”) ou para explorar alternativas arriscadas, mas informativas (“exploração”). Depois, coletamos a ordenação de junção de melhor desempenho testada pelo agente, que se torna nosso resultado final. Mas como sabemos que o agente escolheu uma ordenação de junção válida? Para garantir a correção, cada chamada de ferramenta gera uma ordenação de junção usando saídas de modelo estruturadas, o que força a saída do modelo a corresponder a uma gramática que especificamos para admitir apenas reordenações de junção válidas. Note que isso difere de trabalhos anteriores [B] que pedem ao LLM para escolher uma ordenação de junção instantaneamente no “caminho crítico” do otimizador de consulta; em vez disso, o LLM pode agir como um experimentador offline que testa vários planos candidatos e aprende com os resultados observados – assim como um humano ajustando uma ordenação de junção manualmente!.
Para avaliar nosso agente no DBR, usamos o Join Order Benchmark (JOB), um conjunto de consultas projetadas para serem difíceis de otimizar. Como o conjunto de dados usado pelo JOB, o conjunto de dados IMDb, tem apenas cerca de 2 GB (e, portanto, o Databricks poderia processar até mesmo ordenações de junção ruins com bastante rapidez), escalamos o conjunto de dados duplicando cada linha 10 vezes [C].
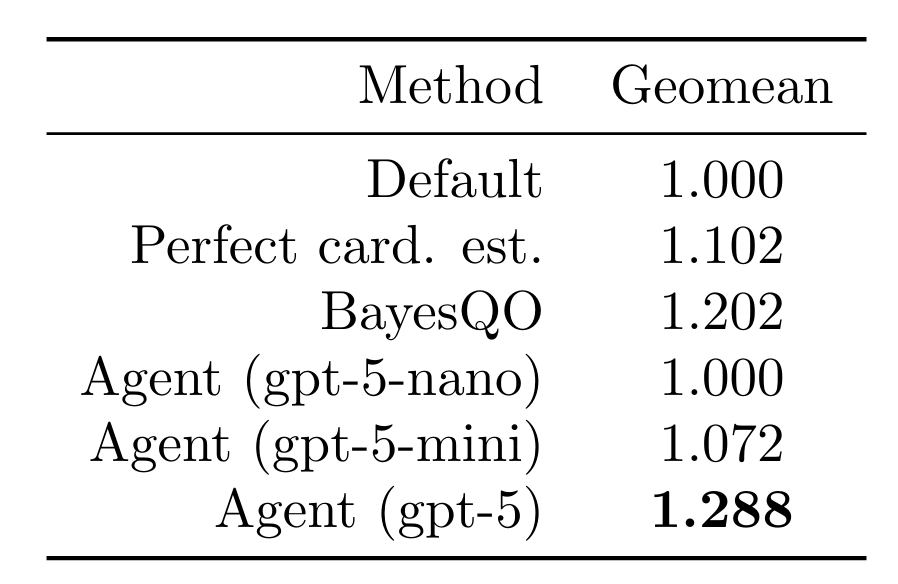
Deixamos nosso agente testar 15 ordenações de junção (rollouts) por consulta para todas as 113 consultas no benchmark de ordenação de junção. Relatamos os resultados na melhor ordenação de junção encontrada para cada consulta. Ao usar um modelo de ponta, o agente conseguiu melhorar a latência da consulta em um fator de 1.288 (geomean). Isso supera o uso de estimativas de cardinalidade perfeitas (intratáveis na prática), modelos menores e o recente otimizador offline BayesQO (embora o BayesQO tenha sido projetado para PostgreSQL, não para Databricks).
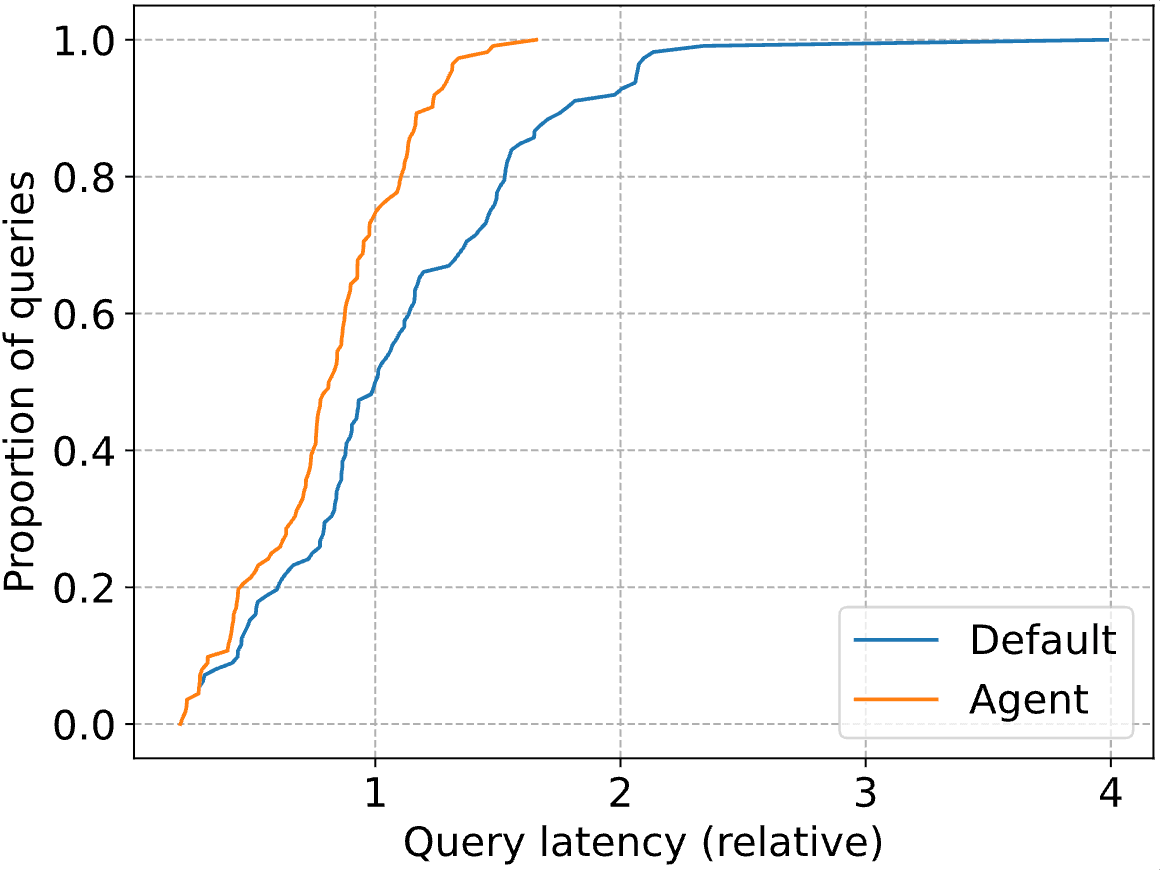
Os ganhos realmente impressionantes estão na cauda da distribuição, com a latência P90 da consulta caindo 41%. Abaixo, plotamos o CDF completo tanto para o otimizador Databricks padrão (“Default”) quanto para nosso agente (“Agent). As latências das consultas são normalizadas para a latência mediana do otimizador Databricks (ou seja, em 1, a linha azul atinge uma proporção de 0.5).
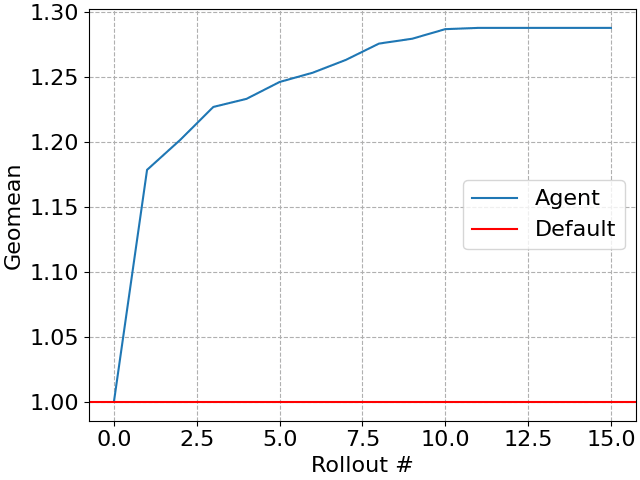
Nosso agente melhora progressivamente a carga de trabalho a cada plano testado (às vezes chamado de rollout), criando um simples “algoritmo a qualquer momento” onde orçamentos de tempo maiores podem ser traduzidos em melhor desempenho da consulta. Claro, eventualmente o desempenho da consulta parará de melhorar.
Uma das maiores melhorias que nosso agente encontrou foi na consulta 5b, um simples join de 5 vias que procura por produtoras americanas que lançaram um filme pós-2010 em VHS com uma nota referenciando 1994. O otimizador do Databricks focou primeiro em encontrar produtoras americanas de VHS (o que é realmente seletivo, produzindo apenas 12 linhas). O agente encontra um plano que primeiro procura por lançamentos em VHS referenciando 1994, o que se mostra significativamente mais rápido. Isso ocorre porque a consulta usa predicados LIKE para identificar lançamentos em VHS, que são excepcionalmente difíceis para estimadores de cardinalidade.
Nosso protótipo demonstra o potencial de sistemas agentivos reparando e melhorando autonomamente consultas de banco de dados. Este exercício levantou várias questões sobre o design de agentes em nossas mentes:
- Quais ferramentas devemos dar ao agente? Em nossa abordagem atual, o agente pode executar ordens de join candidatas. Por que não deixar o agente emitir consultas de cardinalidade específicas (por exemplo, calcular o tamanho de um subplano particular), ou consultas para testar certas suposições sobre os dados (por exemplo, para determinar que não houve lançamentos em DVD antes de 1995).
- Quando essa otimização agentiva deve ser acionada? Certamente, um usuário pode sinalizar manualmente uma consulta problemática para intervenção. Mas poderíamos também aplicar proativamente essa otimização a consultas em execução regular? Como podemos determinar se uma consulta tem “potencial” para otimização?
- Podemos entender automaticamente as melhorias? Quando o agente encontra uma ordem de join melhor do que a encontrada pelo otimizador padrão, essa ordem de join pode ser vista como uma prova de que o otimizador padrão está escolhendo uma ordem subótima. Se o agente corrigir um erro sistemático no otimizador subjacente, podemos descobrir isso e usá-lo para melhorar o otimizador?
Claro, não somos os únicos a pensar sobre o potencial dos LLMs para otimização de consultas [D]. Na Databricks, estamos animados com a possibilidade de aproveitar a generalização dos LLMs para melhorar os próprios sistemas de dados.
Se você estiver interessado neste tópico, veja também nosso próximo blog da UCB sobre "Como os agentes LLM pensam através de ordens de join SQL?".
Junte-se a nós
À medida que avançamos, estamos animados para continuar expandindo os limites de como a IA pode moldar as otimizações de banco de dados. Se você é apaixonado por construir a próxima geração de motores de banco de dados, junte-se a nós!
1 Databricks usa técnicas como filtros de tempo de execução para mitigar o impacto de ordens de join ruins. Os resultados apresentados aqui incluem essas técnicas.
Notas
A. Técnicas para estimativa de cardinalidade incluíram, por exemplo, feedback adaptativo, aprendizado profundo, modelagem de distribuição, teoria de banco de dados, teoria de aprendizado, e decomposições de fatores. Trabalhos anteriores também tentaram substituir completamente a arquitetura tradicional do otimizador de consultas por aprendizado por reforço profundo, multi-armed bandits, otimização Bayesiana, ou algoritmos de join mais avançados.
B. Abordagens baseadas em RAG, por exemplo, foram usadas para construir sistemas “LLM no caminho crítico”.
C. Embora rudimentar, essa abordagem foi usada em trabalhos anteriores.
D. Outros pesquisadores propuseram sistemas de reparo de consulta baseados em RAG, sistemas de reescrita de consulta potencializados por LLM, e até mesmo sistemas de banco de dados inteiros sintetizados por LLMs.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.