Are LLM agents good at join order optimization?
by Eric Liang, Ryan Marcus, Sid Taneja and Yuhao Zhang
- What it is: We explore applying frontier Large Language Model (LLM) agents to the classic database problem of SQL join order optimization.
- The Challenge: Traditional query optimizers often struggle with Join Ordering, where the number of possible plans grows exponentially with the number of tables, often leading to poor performance due to misestimated cardinality. LLM agents address this by acting like a data-driven DBA, reasoning through actual runtime statistics and semantic context that automated heuristics often miss.
- Results & Outcomes: In experimental benchmarks, the prototype agent improved upon the Databricks optimizer in 80% of cases, improving query latency by a factor of 1.3x overall.
Introduction
In the Databricks intelligence platform, we regularly explore and use new AI techniques to improve engine performance and simplify the user experience. Here we present experimental results on applying frontier models to one of the oldest database challenges: join ordering.
This blog is part of a research collaboration with UPenn.
The Problem: Join Ordering
Since their inception, query optimizers in relational databases have struggled to find good join orderings for SQL queries. To illustrate the difficulty of join ordering, consider the following query:
How many movies were produced by Sony and starred Scarlett Johansson?
Suppose we want to execute this query over the following schema:
| Table name | Table columns |
|---|---|
| Actor | actorID, actorName, actorDOB, … |
| Company | companyID, companyName, … |
| Stars | actorID, movieID |
| Produces | companyID, movieID |
| Movie | movieID, movieName, movieYear , … |
The Actor, Company, and Movie entity tables are connected via the Produces and Stars relationship tables (e.g., via foreign keys). A version of this query in SQL might be:
Logically, we want to perform a simple join operation: Actor ⋈ Stars ⋈ Movie ⋈ Produces ⋈ Company. But physically, since each of these joins are commutative and associative, we have a lot of options. The query optimizer could choose to:
- First find all movies starring Scarlett Johansson, then filter out for just the movies produced by Sony,
- First find all movies produced by Sony, then filter out those movies starring Scarlett Johansson,
- In parallel, compute Sony movies and Scarlett Johansson movies, then take the intersection.
Which plan is optimal depends on the data: if Scarlett Johansson has starred in significantly fewer movies than Sony has produced, the first plan might be optimal. Unfortunately, estimating this quantity is as difficult as executing the query itself (in general). Even worse, there are normally far more than 3 plans to choose from, as the number of possible plans grows exponentially with the number of tables — and analytics queries regularly join 20-30 different tables.
How does join ordering work today? Traditional query optimizers solve this problem with three components: a cardinality estimator designed to quickly guess the size of subqueries (e.g., to guess how many movies Sony has produced), a cost model to compare different potential plans, and a search procedure that navigates the exponentially-large space. Cardinality estimation is especially difficult, and has led to a wide range of research seeking to improve estimation accuracy using a wide range of approaches [A].
All of these solutions add significant complexity to a query optimizer, and require significant engineering effort to integrate, maintain, and productionize. But what if LLM-powered agents, with their abilities to adapt to new domains with prompting, hold the key to solving this decades-old problem?
Agentic join ordering
When query optimizers select a bad join ordering1, human experts can fix it by diagnosing the issue (often a misestimated cardinality), and instructing the query optimizer to choose a different ordering. This process often requires multiple rounds of testing (e.g., executing the query) and manually inspecting the intermediary results.
Query optimizers typically need to pick join orders in a few hundred milliseconds, so integrating an LLM into the hot path of the query optimizer, while potentially promising, is not possible today. But, the iterative and manual process of optimizing the join order for a query, which might take a human expert multiple hours, could potentially be automated with an LLM agent! This agent tries to automate that manual tuning process.
To test this, we developed a prototype query optimization agent. The agent has access to a single tool, which executes a potential join order for a query and returns the runtime of the join order (with a timeout of the original query’s runtime) and the size of each computed subplan (e.g., the EXPLAIN EXTENDED plan).
We let the agent run for 50 iterations, allowing the agent to freely try out different join orders. The agent is free to use these 50 iterations to test out promising plans (“exploitation”), or to explore risky-but-informative alternatives (“exploration”). Afterwards, we collect the best performing join order tested by the agent, which becomes our final result. But how do we know the agent picked a valid join order? To ensure correctness, each tool call generates a join ordering using structured model outputs, which forces the model’s output to match a grammar we specify to only admit valid join reorderings. Note that this differs from prior work [B] that asks the LLM to pick a join order instantly in the “hot path” of the query optimizer; instead, the LLM gets to act like an offline experimenter that tries many candidate plans and learns from the observed outcomes – just like a human tuning a join order by hand!.
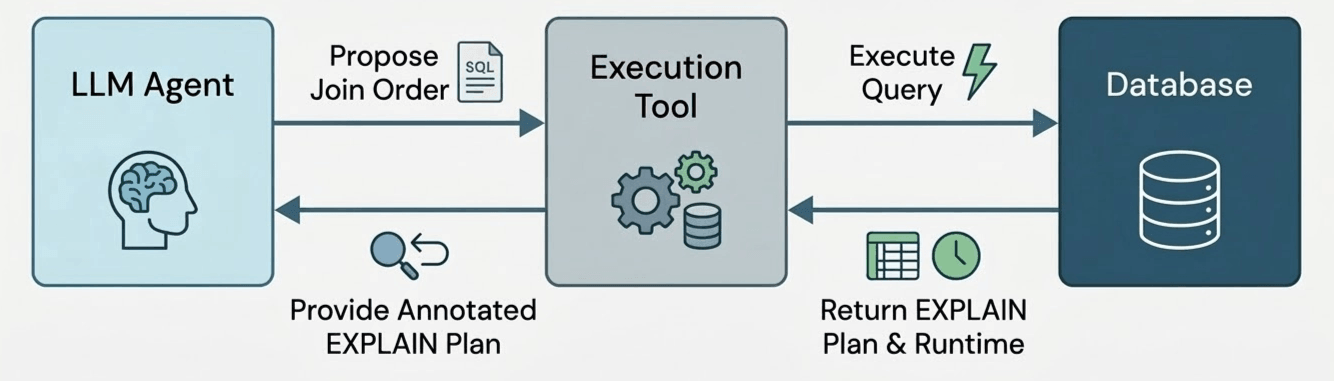
To evaluate our agent in DBR, we used the Join Order Benchmark (JOB), a set of queries that were designed to be difficult to optimize. Since the dataset used by JOB, the IMDb dataset, is only around 2GB (and therefore Databricks could process even poor join orderings fairly quickly), we scaled up the dataset by duplicating each row 10 times [C].
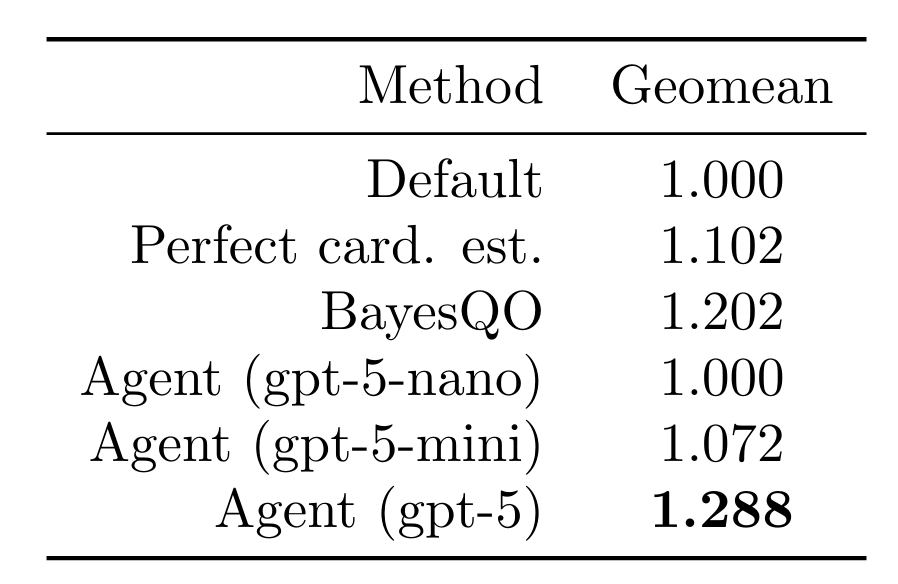
We let our agent test 15 join orders (rollouts) per query for all 113 queries in the join order benchmark. We report results on the best join order found for each query. When using a frontier model, the agent was able to improve query latency by a factor of 1.288 (geomean). This outperforms using perfect cardinality estimates (intractable in practice), smaller models, and the recent BayesQO offline optimizer (although BayesQO was designed for PostgreSQL, not Databricks).
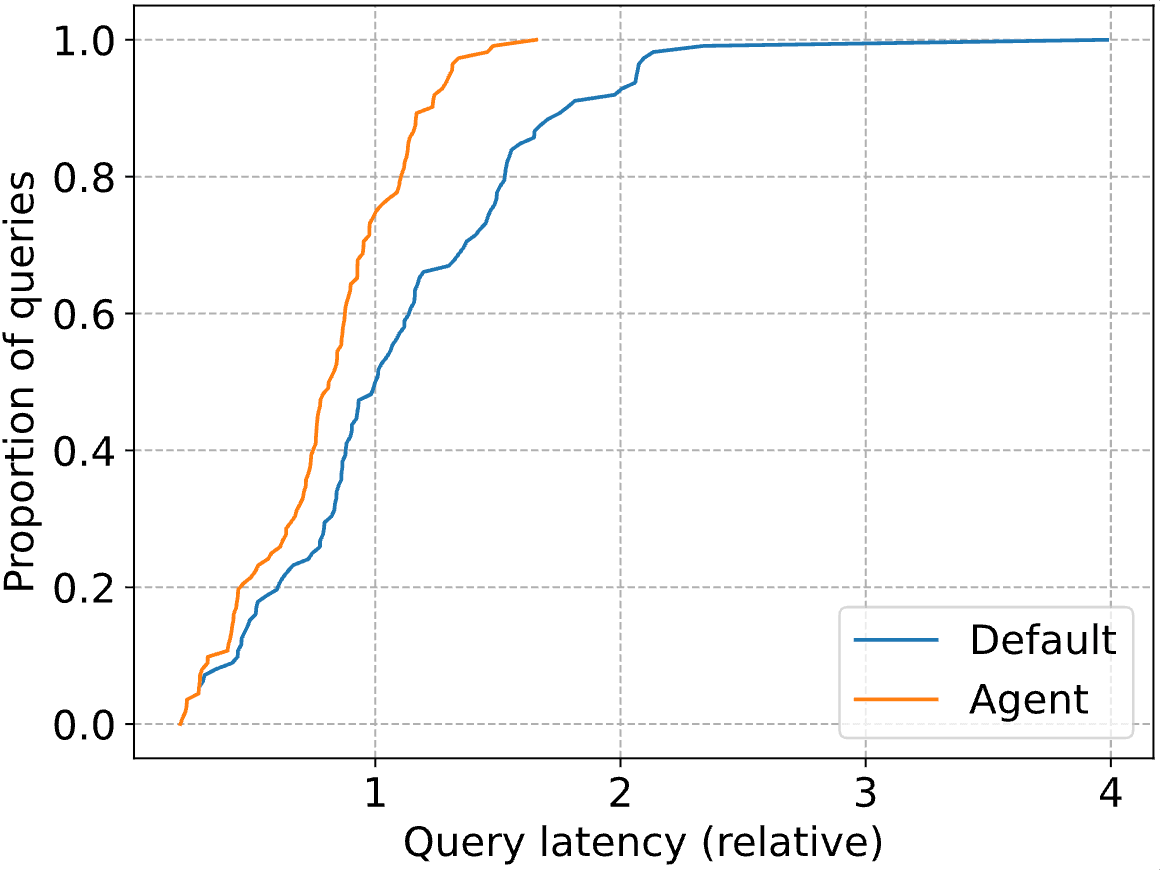
The real impressive gains are in the tail of the distribution, with the P90 query latency dropping by 41%. Below, we plot the entire CDF for both the standard Databricks optimizer (”Default”) and our agent (”Agent). Query latencies are normalized to the median latency of the Databricks optimizer (i.e., at 1, the blue line reaches a proportion of 0.5).
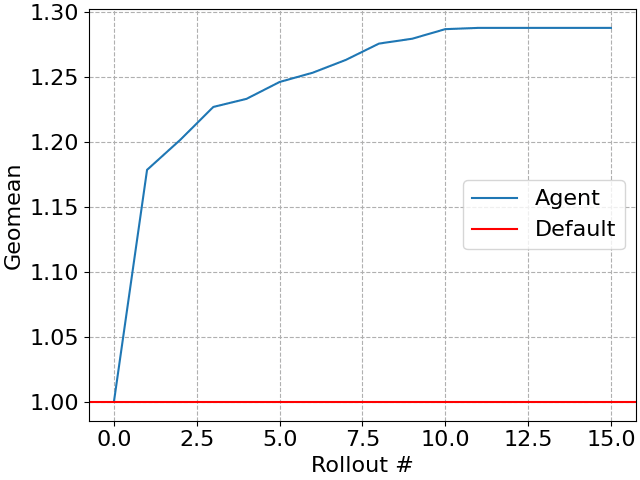
Our agent progressively improves the workload with each tested plan (sometimes called a rollout), creating a simple “anytime algorithm” where larger time budgets can be translated into further query performance. Of course, eventually query performance will stop improving.
One of the largest improvements our agent found was in query 5b, a simple 5-way join which looks for American production companies that released a post-2010 movie on VHS with a note referencing 1994. The Databricks optimizer focused first on finding American VHS production companies (which is indeed selective, producing only 12 rows). The agent finds a plan that first looks for VHS releases referencing 1994, which turns out to be significantly faster. This is because the query uses LIKE predicates to identify VHS releases, which are exceptionally difficult for cardinality estimators.
Our prototype demonstrates the promise of agentic systems autonomously repairing and improving database queries. This exercise raised several questions about agent design in our minds:
- What tools should we give the agent? In our current approach, the agent can execute candidate join orders. Why not let the agent issue specific cardinality queries (e.g., compute the size of a particular subplan), or queries to test certain assumptions about the data (e.g., to determine that there were no DVD releases prior to 1995).
- When should this agentic optimization be triggered? Surely, a user can flag a problematic query manually for intervention. But could we also proactively apply this optimization to regularly-running queries? How can we determine if a query has “potential” for optimization?
- Can we automatically understand improvements? When the agent finds a better join order than the one found by the default optimizer, this join order can be viewed as a proof that the default optimizer is choosing a suboptimal order. If the agent corrects a systematic error in the underlying optimizer, can we discover this and use it to improve the optimizer?
Of course, we are not the only ones thinking about the potential of LLMs for query optimization [D]. At Databricks, we are excited about the possibility of harnessing the generalizability of LLMs to improve data systems themselves.
If you are interested in this topic, see also our followup UCB blog on "How do LLM agents think through SQL join orders?".
Join Us
As we look ahead, we’re excited to keep pushing the boundaries of how AI can shape database optimizations. If you’re passionate about building the next generation of database engines, join us!
1 Databricks use techniques like runtime filters to mitigate the impact of poor join orders. The results presented here include those techniques.
Notes
A. Techniques for cardinality estimation have included, for example, adaptive feedback, deep learning, distribution modeling, database theory, learning theory, and factor decompositions. Prior work has also attempted to entirely replace the traditional query optimizer architecture with deep reinforcement learning, multi-armed bandits, Bayesian optimization, or more advanced join algorithms.
B. RAG-based approaches, for example, have been used to build “LLM in the hot path” systems.
C. While crude, this approach has been used in prior work.
D. Other researchers have proposed RAG-based query repair systems, LLM-powered query rewrite systems, and even entire database systems synthesized by LLMs.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.