Bastidores do Lakebase
Ramificando o Ciclo de Desenvolvimento (Parte 1)
por Cameron Casher e Kevin Hartman
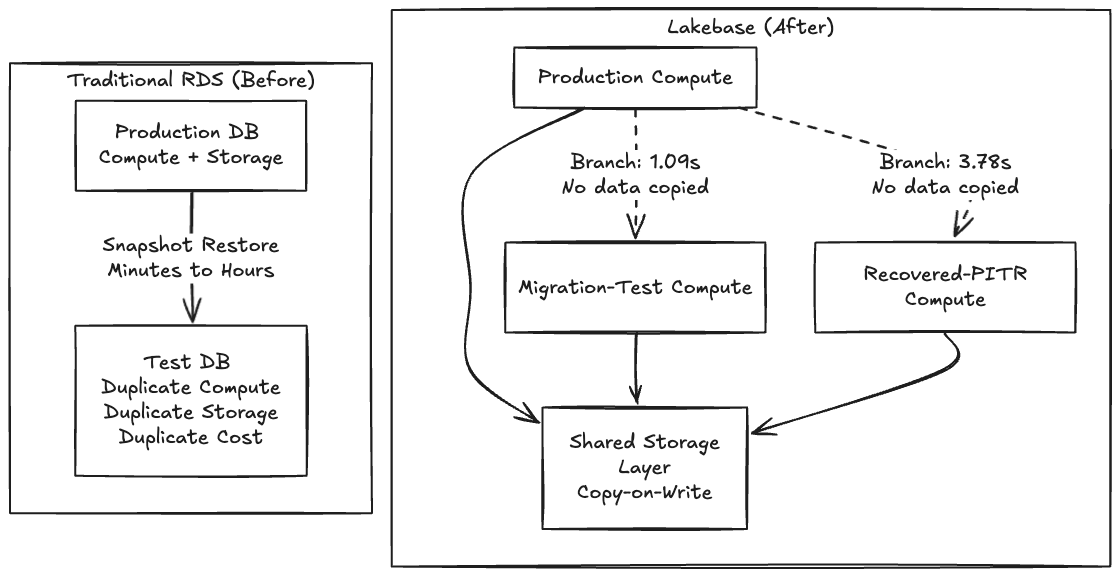
Por trinta anos, o banco de dados operacional e o banco de dados analítico foram dois artefatos, dois planos de governança, dois orçamentos e, geralmente, duas rotações de plantão, conectados por um job de ETL que alguém escreveu às pressas e ninguém quer assumir a responsabilidade. Essa divisão nunca foi uma escolha de design; foi uma restrição física. OLTP e OLAP tinham layouts de armazenamento genuinamente diferentes, perfis de computação diferentes e modos de falha diferentes, então construímos duas plataformas e as conectamos após o fato.
Essa restrição está se dissolvendo. Quando o armazenamento é compartilhado, a computação é serverless e isolada por carga de trabalho, e a governança reside na camada de catálogo, "operacional" e "analítico" deixam de ser categorias arquitetônicas e passam a ser padrões de acesso contra a mesma base.
Para testar se isso é realmente verdade na prática, pegamos o Backstage, o Portal de Desenvolvedor Interno notoriamente pesado em estado do Spotify, o desconectamos de seu banco de dados Postgres padrão e o apontamos para o Lakebase da Databricks. Ao longo desta série de três partes, exploraremos o que acontece com os Ciclos de Implantação (Parte 1), Governança (Parte 2) e FinOps (Parte 3) quando você colapsa o muro entre o aplicativo operacional e a plataforma de dados.
A Configuração: Apontando o Backstage para o Lakebase
O Lakebase expõe uma superfície Postgres serverless (utilizando a arquitetura da Neon por baixo dos panos) que reside dentro da Plataforma Databricks. Como ele fala Postgres via protocolo de conexão, o Backstage não sabe nem se importa que não está falando com o RDS.
Conectá-lo exigiu apontar o app-config.yaml para o Lakebase e trocar a busca em memória padrão do Backstage por PgSearchEngine. Um obstáculo imediato: o Lakebase rejeita os Tokens de Acesso Pessoal clássicos do Databricks, esperando um OAuth JWT em vez disso. A CLI fornece databricks postgres generate-database-credential, que gera um JWT com escopo e de curta duração para um endpoint específico, a abordagem pretendida para aplicativos e CI. Para este POC, encapsulamos esse comando em um script cron leve que reescreveu o DATABRICKS_TOKEN em nosso arquivo .env a cada 50 minutos para lidar com a expiração do token.
Com a autenticação resolvida, as migrações Knex foram executadas sem problemas e o portal estava no ar.
Branching Altera o Ciclo de Desenvolvimento do Banco de Dados
A coisa mais subestimada sobre um Postgres tradicional não é seu conjunto de recursos; é o ritmo que ele impõe às equipes que o possuem.
A Thoughtworks tem sido uma defensora consistente do Backstage como base para IDP através do Technology Radar, então, além de estar muito familiarizada com a ferramenta, escolhemos o Backstage para este POC porque suas migrações de esquema são notoriamente frágeis e parecia uma oportunidade perfeita para testar uma integração com o Lakebase. Em um RDS tradicional, testar uma migração arriscada significa esperar minutos ou horas para que um snapshot seja restaurado em uma instância paralela. Como fazer uma cópia é lento e caro, as equipes simplesmente não testam. Elas cruzam os dedos e executam a migração em uma janela de manutenção.
Quando fazer uma cópia se torna gratuito, você para de perguntar "esta alteração é segura o suficiente para executar?" e começa a perguntar "qual fork da produção eu quero experimentar primeiro?"
Como o Lakebase separa o armazenamento da computação usando uma arquitetura copy-on-write, criar um branch não copia nenhum dado, ele cria um ponteiro para as mesmas páginas subjacentes e só diverge na escrita. É por isso que a operação é instantânea.
Um detalhe que a documentação não deixa claro: o corpo da requisição deve aninhar tudo dentro de um objeto spec, e você deve especificar ttl, expire_time, ou no_expiry. Sem isso, a API retorna "Expiration must be specified."
O plano de controle o reconheceu instantaneamente. O clone real do plano de dados do catálogo Backstage de ~63 MB foi concluído em 1,09 segundos.
Recuperação de Ponto no Tempo: O Botão de Desfazer
Branching e Recuperação de Ponto no Tempo (PITR) são essencialmente o mesmo primitivo: branching é apenas PITR com source_branch_time = now. Para testar a recuperação contra dados reais excluídos, limpamos nossa tabela final_entities, reduzindo a contagem de 32 para 0.
Em seguida, criamos um branch de recuperação a partir de um timestamp capturado segundos antes da exclusão:
O tempo decorrido de ponta a ponta foi de 3,78 segundos.
A verificação dos dados confirmou que o branch recuperado tinha todas as 32 entidades de volta; a produção ainda estava em zero, confirmando que a exclusão foi real e os branches são totalmente isolados. Notavelmente, solicitamos 22:56:02Z, mas o Lakebase se ajustou para 22:55:50Z, 12 segundos antes, voltando para o registro WAL mais próximo. Essa granularidade em nível de WAL é uma ressalva importante para fluxos de trabalho de recuperação sensíveis ao tempo, mas o ciclo do incidente ainda foi concluído em menos de um minuto.
Quando o estado do banco de dados se torna um artefato barato e que pode ser bifurcado em vez de um volume EBS de 2 TB, toda operação arriscada recebe um teste e todo incidente recebe um desfazer.
Da Capacidade de Infraestrutura ao Fluxo de Trabalho do Desenvolvedor
Como mostrado acima, isso prova que o branching de banco de dados funciona – um clone de 1 segundo, uma recuperação de 4 segundos e um aplicativo real que não sabe a diferença. Mas há uma lacuna entre "o banco de dados pode fazer branching" e "minha equipe faz branching do banco de dados tão naturalmente quanto faz branching de código". Fechar essa lacuna é onde o impacto massivo na produtividade do desenvolvedor pode ser realizado em ganhos objetivos.
Passamos os últimos meses trabalhando com equipes de desenvolvimento para responder a uma pergunta específica: o que acontece com a velocidade de uma equipe quando o branching de banco de dados se torna invisível – quando não é um comando CLI que você executa, mas algo que acontece automaticamente como parte de como você já trabalha em seu editor de escolha? O trabalho está em andamento em uma extensão VS Code/Cursor que sincroniza branches git e de banco de dados automaticamente para provar isso – mas as ferramentas são secundárias ao que elas possibilitam.
O Que o Branching Possibilita
Entre as equipes com as quais tivemos experiência, o ciclo de sprint sem branching de banco de dados se parece com isto:
- Criar um branch git para desenvolvimento de recursos
- Escrever objetos mock para cada interface de banco de dados (MockUserRepository, MockOrderService...) para fins de teste
- Escrever testes unitários com um banco de dados mockado ou em memória (H2, SQLite)
- Enviar um PR, obter revisão e mesclar código
- Implantar em um ambiente de staging compartilhado
- Descobrir que a migração do esquema não funciona com dados reais ou que o tamanho dos dados é um bloqueador
- Corrigir a migração do esquema, reimplantar, repetir
Com a disponibilidade de ramificações de banco de dados, o ciclo de desenvolvimento de recursos de um desenvolvedor muda:
- Crie um branch git – um branch de banco de dados Lakebase pode ser criado automaticamente em 1 segundo
- Seu IDE se conecta ao branch real do banco de dados imediatamente
- Escreva código e execute migrações contra dados reais do banco de dados em tempo real desde a primeira linha de código
- Escreva testes de integração contra o banco de dados real – não mocks de banco de dados
- Várias soluções podem ser experimentadas, já que o rollback das alterações do banco de dados é trivial
- Envie e abra um PR – CI cria seu próprio branch de banco de dados, valida código e esquema, publica um diff de esquema
- Os membros da equipe de QA podem obter seu próprio branch de banco de dados para testes destrutivos – pode ser redefinido em segundos
- Merge – Uma vez feito o merge, o pipeline de CD pode migrar ambientes upstream como UAT e produção e limpar todos os branches – código e dados.
Os objetos mock desaparecem. As colisões de staging desaparecem. O "funciona na minha máquina, mas quebra em staging" desaparece, os desenvolvedores obtêm um banco de dados ao vivo para experimentar várias soluções. As alterações no banco de dados que costumavam ser descobertas na implantação agora são capturadas durante o desenvolvimento, onde são baratas de corrigir. Branches instantâneos para testes de desempenho, branches descartáveis e isolados para testes funcionais e um branch em execução para stakeholders de UAT se tornam triviais.
Em nossa experiência com várias equipes parceiras avaliando esse fluxo de trabalho, objetos mock representam 20-30% do código de teste. Isso não é cobertura de teste – é infraestrutura de teste. Infraestrutura que diverge do comportamento de produção ao longo do tempo, criando falsa confiança. Quando ramificar um banco de dados equivalente à produção não custa nada, o mocking se torna a escolha cara.
A questão agora é quanto do seu sprint você está gastando em soluções alternativas para uma restrição que não existe mais.
Na Parte 2 desta série, veremos o que acontece com a segurança e a conformidade quando esse banco de dados operacional for absorvido diretamente no Unity Catalog, a camada de governança unificada da Databricks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.